This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Below is a quick reference of those field name length limits, but of course, you should reference your RDBMS documentation for specific limitations: File geodatabase and memory workspace – 128 characters SQLite and most enterprise geodatabases – 128 characters with 256-byte maximum SQL – 128 characters PostgreSQL – 63 bytes (..)
Drawing an analogy to Byte Pair Encoding (BPE) in NLP, we can think of tokenization as merging adjacent actions to form new, higher-level tokens. Tokenizing User Interactions : Not all raw user actions contribute equally to understanding preferences. Tokenization helps define what constitutes a meaningful token in a sequence.
Numeric data consists of four sub-types: Integer type (INT64) Numeric type (NUMERIC DECIMAL) Bignumeric type (BIGNUMERIC BIGDECIMAL) Floating point type (FLOAT64) BYTES Although they work with raw bytes rather than Unicode characters, BYTES also represent variable-length data.
At Pinterest, we have an in-house rate limiter implementation: it maintains a budget (number of credits) based on the configured rate (bytes per second) and the time elapsed in between requests. It exposes an interface for conducting rate limiting when interacting with S3.
In physical replication, changes are transmitted as raw byte-level data, specifying exactly what blocks of disk pages have been modified. PostgreSQL (Physical Replication) : Uses Write-Ahead Logs (WAL), which record low-level changes to the database at a disk block level.
Google offers "on-demand pricing," where users are charged for each byte of requested and processed data; the first 1 TB of data per month is free. The hourly rate starts at $0.25 and increases from there. Similar to Snowflake, BigQuery separates storage and computation costs.
Quotas are byte-rate thresholds that are defined per client-id. The process of converting the data into a stream of bytes for the purpose of the transmission is known as serialization. Deserialization is the process of converting the bytes of arrays into the desired data format. What do you understand about quotas in Kafka?
String & Binary Snowflake Data Types VARCHAR, STRING, TEXT Snowflake data types It is a variable-length character string of a maximum of 16,777,216 bytes and holds Unicode characters(UTF-8). Snowflake often represents each byte as two hexadecimal characters while displaying BINARY values.
Quintillion Bytes of data per day. As per statistics, we produce 2.5 With such a vast amount of data available, dealing with and processing data has become the main concern for companies. The problem lies in the real-world data.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now.
BigQuery charges users depending on how many bytes are read or scanned. With on-demand pricing, you are charged $5 per TB for each TB of bytes processed in a particular query (the first TB of data processed per month is completely free of charge). You can pre-purchase credits to cover consumption for several Snowflake plans.
You can store up to 1 billion 2-byte Unicode characters using nvarchar [(n | max)]. The maximum size of a single column in Azure Synapse Analytics depends on the storage technology used and also on the datatype of the column. Briefly discuss the method for setting up a spark job in Azure Synapse Analytics.
<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store")); wordCounts.toStream().to("WordsWithCountsTopic", Kafka Spark Streaming Java Example Below is an example of an elastic, fault-tolerant, stateful, scalable wordCount application that is ready to run on a large scale in production. split("W+"))).groupBy((key,
quintillion bytes of data is produced daily. With the proliferation of data sources, IoT devices, and edge nodes, almost 2.5 This data is distributed across many platforms, including cloud databases, websites, CRM tools, social media channels, email marketing, etc.
The result is the sum of memory usage in bytes, which is then converted to megabytes for better readability. The memory_usage() method with deep=True calculates the memory usage including the memory used by the objects within the DataFrame. Discuss techniques to reduce memory usage when working with large datasets in Pandas.
cAdvisor exported metrics documentation — describes container_referenced_bytes as an intrusive metric to collect The metric container_referenced_bytes is enabled by default in cAdvisor and tracks the total bytes of memory that a process references during each measurement cycle.
MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. In the event that memory is inadequate, partitions that do not fit in memory will be kept on disc, and data will be retrieved from the drive as needed.
Ray gives the ability to specify resources for each class or function, these resources can be specified the following: num_cpus : a float value can be provided num_gpus : a float value can be provided memory: value in bytes Ray's resources are logical and not physical.
Content Repository The Content Repository stores the actual content bytes of a given FlowFile. The default approach involves a persistent Write-Ahead Log on a specified disk partition. This repository ensures the resiliency and durability of FlowFile information.
def looks_like_base64(sb): """Check if the string looks like base64""" return re.match("^[A-Za-z0-9+/]+[=]{0,2}$", sb) is not None Identifying Image Data from Base64 We next define a function to determine whether the Base64-encoded data corresponds to an image format by analyzing the first few bytes of the decoded data.
[link] Rentry: Dummy's Guide to Modern LLM Sampling The article provides a comprehensive guide to modern Large Language Model (LLM) sampling techniques, explaining why sub-word tokenization (using methods like Byte Pair Encoding or SentencePiece) is preferred over letter or whole-word tokenization.
[link] Daniel Lemire: Fast character classification with z3 The author discusses using the Z3 theorem prover to automatically compute lookup tables (LUTs) for fast character classification, specifically for vectorized base64 decoding using SIMD instructions.
We used OO design to support various deserialization methods to mimic Python lists, sets, and dictionaries, using LMDBs byte-based key-value records. In the API processes, we maintain persistent read-only connections, allowing LMDB to paginate data present in virtual shared memory efficiently.
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management.
Metadata for a file, block, or directory typically takes 150 bytes. In other words, having too many files will lead to the generation of too much metadata. And storing these metadata in RAM will become problematic. What is the main differencebetween distCP and Sqoop?
Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. The World Economic Forum predicts that by 2025, 463 exabytes of data will be produced daily across the world.
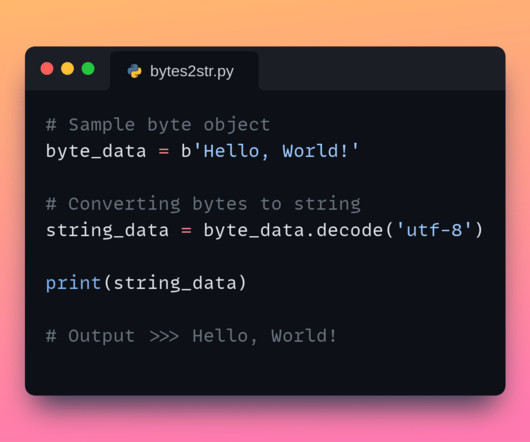
Byte Literals Byte literals are groups of bytes that start with b or B. Byte and Unicode Literals Python makes it easy to work with Unicode and byte data, which is useful for translation. Encoding and Decoding Bytes byte_data = b'Hello' print(byte_data.decode('utf-8')) # Decode to string b.
2) Number of Tokens Tokens are the individual units of text used by LLMs, which can range from single characters to entire words or more, depending on the model's tokenization method (such as byte-pair encoding). The number of tokens parameter acts as a control mechanism, allowing users to limit the total number of tokens generated.
This has negatively affected a portion of hot workloads and forced bytes to get stranded on HDDs. This will bring meaningful impact to server and rack level bytes densification as well as help lower per-TB acquisition and power costs at both the drive and server level.
quintillion bytes of data are generated every day and thats a great sign for anyone interested in a data-driven career. The world is becoming increasingly reliant on data, about 2.5 There are many career paths related to data including data scientist, data analyst, ML engineer, AI engineer, BI engineer, and many more.
For example, BERT uses WordPiece, while GPT uses byte pair encoding (BPE). A few common methods used for data preprocessing for LLMs are: Normalization: Normalize text data to handle variations in language, spelling, and syntax. Tokenization : Use tokenizers compatible with your model architecture.
To iterate through these values in reverse order-the bytes of the actual value should be written twice. With the use of Apache Phoenix, user can retrieve data from HBase through SQL queries. 8) Is it possible to iterate through the rows of HBase table in reverse order? 9) Should the region server be located on all DataNodes?
. $ sudo strace -T -e trace=openat,read python3 benchmark.py However, the time it took the second time (i.e. 0.027698 seconds) is 100x the time it took the first time (i.e. 0.000259 seconds) ! This means that if there are 98 processes, the time spent on reading this file alone will be 98 * 0.027698 = 2.7 seconds!
A critical question we continuously ask is: How do we evaluate and monitor which bytes should have been served from local OCAs but resulted in a cache miss? A cache miss occurs when bytes are not served from the best available OCA for a given Netflix client, independent of OCA state. What is a Cache Miss?
quintillion bytes of data are generated every day. The world is becoming increasingly dependent on data, about 2.5 Data is shaping our decisions, from personalized shopping experiences to checking weather forecasts before leaving home. All of these data science applications have a life cycle to follow.
quintillion bytes of data generated daily, the landscape is ripe for skilled individuals to step in and make sense of this wealth of information. With over 2.5 According to the U.S.
Performance Comparison: Time Benchmark Now let’s measure the performance by measuring the time and memory. The slotted class duration is 46.45% faster, but the memory usage is the same for this example. Machine Learning in Action Now, in this section, let’s continue with the machine learning.
Object Delivery: CloudFront starts forwarding the object to the user when it receives the first byte from the origin server. The CloudFront charges will be listed in the CloudFront section of your AWS billing statement as region-specific DataTransfer-Out-Bytes. This ensures that the content is delivered to the user in a timely manner.
” Despite the advantages images have over text data, there is no denying the complexities that the extra bytes they eat up can bring. You can try to replicate the results by using this Kaggle dataset ImageProcessing. Optimization, therefore, becomes the only way out.If
But sometimes, you may need to work with bytes instead. Let’s learn how to convert bytes to string in Python. Strings are common built-in data types in Python.
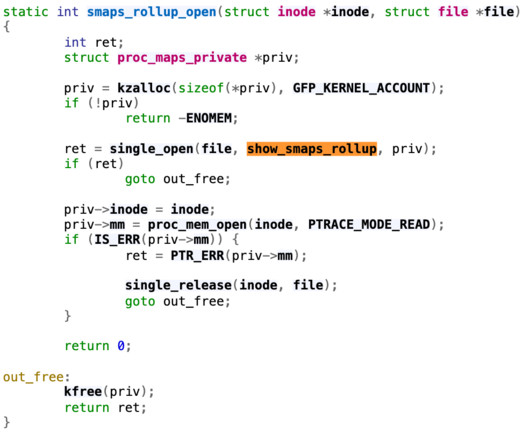
Rather than failing with an error, this encountered an existing bug in the DEC Unix “copy” (cp) command, where cp simply overwrote the source file with a zero-byte file. After this zero-byte file was deployed to prod, the Apache web server processes slowly picked up the empty configuration file.
If you've used Kafka Streams, Kafka clients, or Schema Registry, you’ve probably felt the frustration of unknown magic bytes. Here are a few ways to fix the issue.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content