This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It’s fascinating how what is considered “modern” for backend practices keep evolving over time; back in the 2000s, virtualizing your servers was the cutting-edge thing to do; while around 2010 if you onboarded to the cloud, you were well ahead of the pack. Joshua has remained technical while working as an executive.
As an example, cloud-based post-production editing and collaboration pipelines demand a complex set of functionalities, including the generation and hosting of high quality proxy content. It is worth pointing out that cloud processing is always subject to variable network conditions.
In this post we consider the case in which our data application requires access to one or more large files that reside in cloud object storage. This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Multi-part downloading is critical for pulling large files from the cloud in a timely fashion.
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
This led us to use a number of observability tools, including VPC flow logs , ebpf agent metrics , and Envoy networking bytes metrics to rectify the situation. Lessons learned Some of the key discoveries made during our journey include: Cloud service provider data transfer pricing is more complex than it initially seems.
Google Cloud Dataflow is a unified processing service from Google Cloud; you can think it’s the destination execution engine for the Apache Beam pipeline. Triggering based on data-arriving characteristics such as counts, bytes, data punctuations, pattern matching, etc. Triggering at completion estimates such as watermarks.
Apache Impala is used today by over 1,000 customers to power their analytics in on premise as well as cloud-based deployments. For instance, in both the struct s above the largest member is a pointer of size 8 bytes. Total size of the Bucket is 16 bytes. Similarly, the total size of DuplicateNode is 24 bytes.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS knows how to assemble and decrypt the parts. Disk Caching? — ?
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. The following graphs illustrate the observed clock skew on our Cassandra fleet, suggesting the safety of this technique on modern cloud VMs with direct access to high-quality clocks.
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloud storage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. But as it turns out, we can’t use it.
Snowflake allows security teams to store all their data in a single platform and maintain it all in a readily accessible state, with virtually unlimited cloud data storage capacity. In the cloud, computing can be measured in various ways, like bytes scanned or CPU cycles. Now there are a few ways to ingest data into Snowflake.
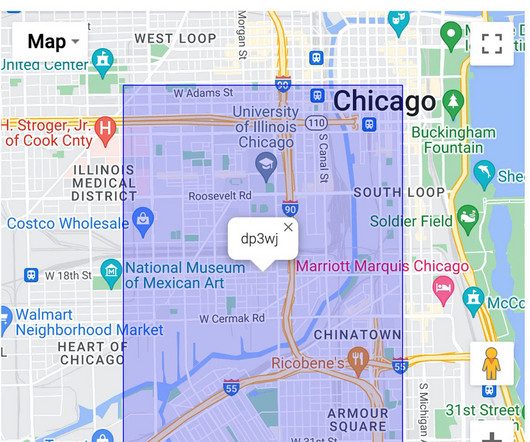
(Note: If you have never heard of the geospatial index or would like to learn more about it, check out this article ) Data The data used in this article is the Chicago Crime Data which is a part of the Google Cloud Public Dataset Program. Anyone with a Google Cloud Platform account can access this dataset for free.
Cloudera DataFlow for the Public Cloud (CDF-PC) is a complete self-service streaming data capture and movement platform based on Apache NiFi. By using component_name and “Hello World Prometheus,” we’re monitoring the bytes received aggregated by the entire process group and therefore the flow.
Ingestion Pipelines : Handling data from cloud storage and dealing with different formats can be efficiently managed with the accelerator. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool. This is ideal for tasks such as data aggregation, reporting or batch predictions.
The customer experience and marketing teams primarily use this to accelerate the acquisition of every byte of customer data from appropriate channels, devices, and platforms and its transformation into a unified customer profile. Companies frequently use CDP Software as the sole source of consumer information.
We’re taking in 16 bytes of data at a time from the stream. This function will provide basic units of data in the form of raw bytes. These bytes can then be converted into a readable JSON format. Stay tuned to get all the updates about our upcoming blogs on the cloud and the latest technologies.
We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. sk) { return 0; } u64 key = (u64)sk; struct source *src; src = bpf_map_lookup_elem(&socks, &key); When capturing the connection close event, we include how many bytes were sent and received over the connection.
With Avro, we can have data fields serialize as type bytes , which allows for the inclusion of binary format data, such as these image cutouts or generally any individual file: Image cutouts from simulated data of a supernova detection. The cloud-based Kafka system is public facing for other astronomy researchers. Armed with a Ph.D.
Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google Cloud Storage as Maven artifact repositories. zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0 zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces.
Rockset hosted a tech talk on its new cloud architecture that separates storage-compute and compute-compute for real-time analytics. With compute-compute separation in the cloud, users can allocate multiple, isolated clusters for ingest compute or query compute while sharing the same real-time data.
I decided it was time to put Web3 to the test and see how it fares against the contemporary approach to building apps - the cloud. As a result, you pick your blockchain (and token / currency), although this is equally true of Web2 (pick your cloud provider). Unfortunately I found Web3 to be very lacking.
With the global cloud data warehousing market likely to be worth $10.42 billion by 2026, cloud data warehousing is now more critical than ever. Cloud data warehouses offer significant benefits to organizations, including faster real-time insights, higher scalability, and lower overhead expenses. What is Google BigQuery Used for?
When it comes to cloud, being an early adopter does not necessarily put you ahead of the game. I know of companies that have been perpetually “doing cloud” for 10 years, but very few that have “done cloud” in a way that democratises and makes data accessible, with minimal pain points. Cloud is an enabler.
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). Seagate Technology forecasts that enterprise data will double from approximately 1 to 2 Petabytes (one Petabyte is 10^15 bytes) between 2020 and 2022.
jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. The packaging of payloads for Oracle WMS Cloud. It can then send that activity to cloud services like AWS Kinesis, Amazon S3, Cloud Pub/Sub, or Google Cloud Storage and a few JDBC sources.
link] byte[array]: Doing range gets on cloud storage for fun and profit Cloud blob storage like S3 has become the standard for storing large volumes of data, yet we have not talked about how optimal its interfaces are.
It has been observed across several migrations from CDH distributions to CDP Private Cloud that Hive on Tez queries tend to perform slower compared to older execution engines like MR or Spark. Tez determines the reducers automatically based on the data (number of bytes) to be processed. Tuning Guidelines.
However, these schemas are only enforced as “agreement” between the clients and are totally agnostic to brokers, which still see all messages as entirely untyped byte arrays. Confluent Server is a component of the Confluent Platform that includes Kafka and additional cloud-native and enterprise-level features.
Service Segmentation: The ease of the cloud deployments has led to the organic growth of multiple AWS accounts, deployment practices, interconnection practices, etc. Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems.
Brokers in the cloud (e.g., AWS EC2) and on-premises machines locally (or even in another cloud). I’m naming AWS because it’s what the majority of people use, but this applies to any IaaS/cloud solution. But once you move into more complex networking setups and multiple nodes, you have to pay more attention to it.
The target could be a particular Node (network endpoint), a file-system, a directory, a data-file or a byte-offset range within a given data-file. A Typical flow control for Apache Ozone using this Fault Injection Framework looks like this: . Query OM/SCM/DataNodes to identify the target for failure injection.
When people ask me the very top-level question “why do people use Kafka,” I usually lead with the story in my last post , where I talked about how Apache Kafka ® is helping us deliver on the promises the cloud made to us a decade ago. But I follow it up quickly with a second and potentially unrelated pattern: real-time data pipelines.
Magic numbers are unique byte sequences at the beginning of files that can be used to determine their file types. Cloud Access Security Broker (CASB) For businesses that have previously deployed several SaaS apps, CASBs give a visibility and administrative control point. Source Code 6. Source code 6.
Amazon Web Services is a cloud platform with more than 165 fully-featured services. To learn more, check out Cloud Computing Security course. Redshift has more than 6,5000 deployments which make it the biggest cloud data warehouse deployments. Amazon Redshift does the same for big data analytics and data warehousing.
Primarily the egress fees, which are levied for data movement out of a cloud provider’s network. When your data comes from another cloud environment or even a separate region within the same cloud, it often results in additional expenses for every byte being transferred into the Snowflake platform.
Note, I did not do this as part of the cloud job for this project, as I pickled my embeddings to use without having to keep a cluster up and running indefinitely. However, it is fairly simple to setup Milvus and load a Spark Dataframe to a collection. spark.executor.cores: The number of cores to use on each executor.
Founded by the original creators of Kafka, Confluent provides a cloud-native and complete data streaming platform available everywhere a business’s data may reside. Confluent Platform is a complete, enterprise-grade distribution of Kafka for on-premises and private cloud workloads.
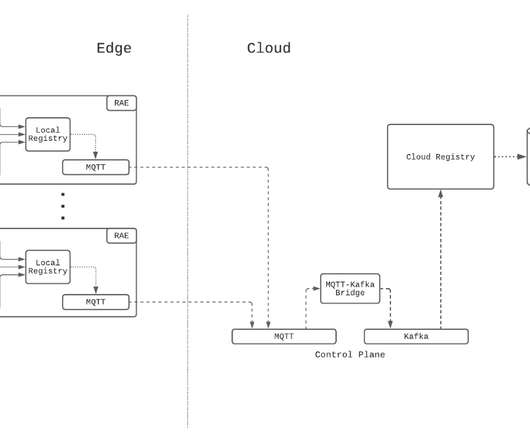
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. Since Kafka is a supported messaging platform at Netflix, a bridge is established between the two protocols to allow cloud-side services to communicate with the control plane.
Our talk follows an earlier video roundtable hosted by Rockset CEO Venkat Venkataramani, who was joined by a different but equally-respected panel of data engineering experts, including: DynamoDB author Alex DeBrie ; MongoDB director of developer relations Rick Houlihan ; Jeremy Daly , GM of Serverless Cloud. Doing the pre-work is important.
sent 11,286 bytes received 172 bytes 2,546.22 The replication of encrypted data between two on-prem clusters or between on-prem & cloud storage usually fails citing the file checksums not matching if the encryption keys are different on source and destination clusters. keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
At a high-level, Zuul (cloud gateway) was to become the termination point for token inspection and payload encryption/decryption. EAS is functionally a series of filters that run in Zuul, which may call out to external services to support their domain, e.g., to a service to handle MSL tokens or another for Cookies.
Java has become the go-to language for mobile development, backend development, cloud-based solutions, and other trending technologies like IoT and Big Data. It is a hosting service that has cloud-based storage. It is an adjective for the process used to create, design, and implement a cloud-based computer program.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content