This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Before we get started, let’s be clear…when using cloudstorage, it is usually not recommended to work with files that are particularly large. here , here , and here ). CPU cores and TCP connections).
BigQuery basics and understanding costs ∘ Storage ∘ Compute · ? Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. Photo by Konstantin Evdokimov on Unsplash ?
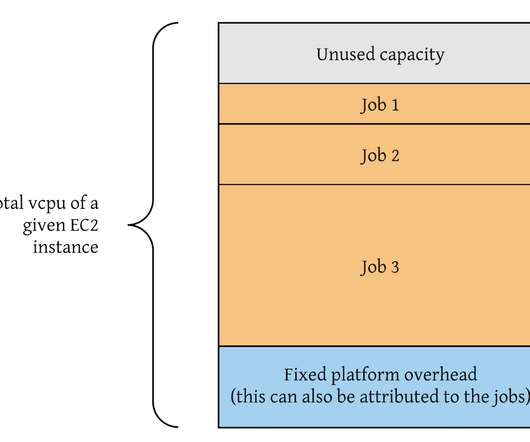
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloudstorage and then downloaded by the next processing step. Since not all projects are terabytes projects, allocating the largest cloudstorage to all packager instances is not an efficient use of cloud resources.
Ingestion Pipelines : Handling data from cloudstorage and dealing with different formats can be efficiently managed with the accelerator. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool. This is ideal for tasks such as data aggregation, reporting or batch predictions.
Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google CloudStorage as Maven artifact repositories. zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0 6 objects dropped. 6 objects created. m2 directory.
Data Store Characteristics Netflix Drive relies on a data store that allows streaming bytes into files/objects persisted on the storage media. The transfer mechanism for transport of bytes is a function of the data store. The data store should expose APIs that allow Netflix Drive to perform I/O operations.
link] byte[array]: Doing range gets on cloudstorage for fun and profit Cloud blob storage like S3 has become the standard for storing large volumes of data, yet we have not talked about how optimal its interfaces are.
BigQuery also supports many data sources, including Google CloudStorage, Google Drive, and Sheets. It can process data stored in Google CloudStorage, Bigtable, or Cloud SQL, supporting streaming and batch data processing. Due to this, combining and contrasting the STRING and BYTE types is impossible.
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloudstorage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. But as it turns out, we can’t use it.
With this feature, you can efficiently manage, govern, and analyze your data irrespective of its storage location, ensuring optimal data management. Cloudflare has announced their partnership with Snowflake which empowers customers to employ Cloudflare R2 as an external storage option for their tables.
jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. It can then send that activity to cloud services like AWS Kinesis, Amazon S3, Cloud Pub/Sub, or Google CloudStorage and a few JDBC sources. jar Archive: functions/build/libs/functions-1.0.0.jar
sent 11,286 bytes received 172 bytes 2,546.22 The replication of encrypted data between two on-prem clusters or between on-prem & cloudstorage usually fails citing the file checksums not matching if the encryption keys are different on source and destination clusters. keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library.
And yet it is still compatible with different clouds, storage formats (including Kudu , Ozone , and many others), and storage engines. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library.
The size of an event is chosen to be around 1K bytes, which is what we found to be the sweet spot for many real-life systems. Rockset delegates compaction CPU to remote compactors , but some minimum CPU is still needed on the leaves to copy files to and from cloudstorage. Each event has nested objects and arrays inside it.
The key can be a fixed-length sequence of bits or bytes. Secure Image Sharing in CloudStorage Selective image encryption can be applied in cloudstorage services where users want to share images while protecting specific sensitive content. Key Generation: A secret encryption key is generated.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content