This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Outsourcing the replication of Kafka will simplify the overall application layer, and the author narrates what Kafka would be like if we had to develop a durable cloud-native event log from scratch. link] Yuval Yogev: Making Sense of Apache Iceberg Statistics A rich metadata model is vital to improve query efficiency. and Lite 2.0)
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. This results in a fast and scalable metadata handling system.
As an example, cloud-based post-production editing and collaboration pipelines demand a complex set of functionalities, including the generation and hosting of high quality proxy content. The inspection stage examines the input media for compliance with Netflix’s delivery specifications and generates rich metadata.
As the demand for big data grows, an increasing number of businesses are turning to cloud data warehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. This model supports both simple and complex data models, balancing flexibility and efficiency.
MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. We can store the data and metadata in a checkpointing directory. In Spark, checkpointing may be used for the following data categories- Metadata checkpointing: Metadata rmeans information about information. appName('ProjectPro').getOrCreate()
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
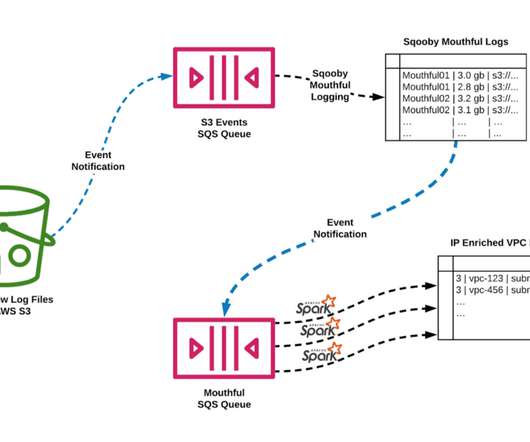
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. This file includes: Metadata ?—?This Mount multiple objects? — ?
A file and folder interface for Netflix Cloud Services Written by Vikram Krishnamurthy , Kishore Kasi , Abhishek Kapatkar , and Tejas Chopra In this post, we are introducing Netflix Drive, a Cloud drive for media assets and providing a high level overview of some of its features and interfaces. The major pieces, as shown in Fig.
When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. Brokers in the cloud (e.g., AWS EC2) and on-premises machines locally (or even in another cloud). This is the metadata that’s passed back to clients. The default is 0.0.0.0,
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloud storage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. But as it turns out, we can’t use it.
This cluster can be from AWS / GCP / Azure cloud service or a Kubernetes cluster. Object Store: Responsible for storing data in a distributed setting and helping in sharing objects efficiently, and storing the metadata needed. Hardware can be either your laptop or any cloud service provider for setting up the Ray cluster.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
One key part of the fault injection service is a very lightweight passthrough fuse file system that is used by Ozone for storing all its persistent data and metadata. The APIs are generic enough that we could target both Ozone data and metadata for failure/corruption/delays. NetFilter Extension.
Geo-Replication in Kafka is a process by which you can duplicate messages in one cluster across other data centers or cloud regions. Message Broker: Kafka is capable of appropriate metadata handling, i.e., a large volume of similar types of messages or data, due to its high throughput value. config/server.properties 25.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
Rockset hosted a tech talk on its new cloud architecture that separates storage-compute and compute-compute for real-time analytics. With compute-compute separation in the cloud, users can allocate multiple, isolated clusters for ingest compute or query compute while sharing the same real-time data.
Service Segmentation: The ease of the cloud deployments has led to the organic growth of multiple AWS accounts, deployment practices, interconnection practices, etc. Cloud Network Insight is a suite of solutions that provides both operational and analytical insight into the Cloud Network Infrastructure to address the identified problems.
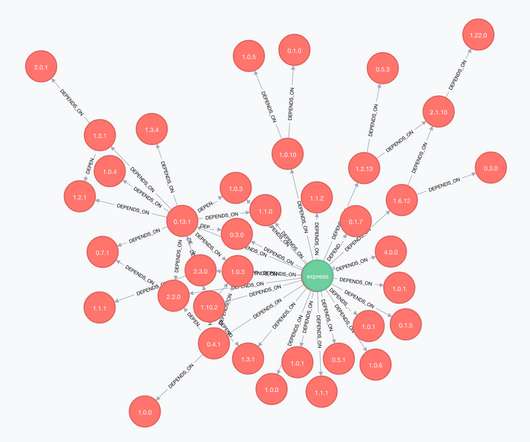
Rigid file naming standards that had built-in dependency metadata. Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google Cloud Storage as Maven artifact repositories. zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. sent 11,286 bytes received 172 bytes 2,546.22 keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
Founded by the original creators of Kafka, Confluent provides a cloud-native and complete data streaming platform available everywhere a business’s data may reside. Confluent Platform is a complete, enterprise-grade distribution of Kafka for on-premises and private cloud workloads.
Map Reduce programs in cloud computing are parallel, making them ideal for executing large-scale data processing across multiple machines in a cluster. It ensures that the data collected from cloud sources or local databases is complete and accurate. NameNode is often given a large space to contain metadata for large-scale files.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
Adopting a cloud data warehouse like Snowflake is an important investment for any organization that wants to get the most value out of their data. This query will fetch a list of all tables within a database, along with helpful metadata about their settings.
Java has become the go-to language for mobile development, backend development, cloud-based solutions, and other trending technologies like IoT and Big Data. It allows the addition of metadata to the changes, which facilitates team members in pinpointing the changes introduced in the code, why it was made, and when and who made it.
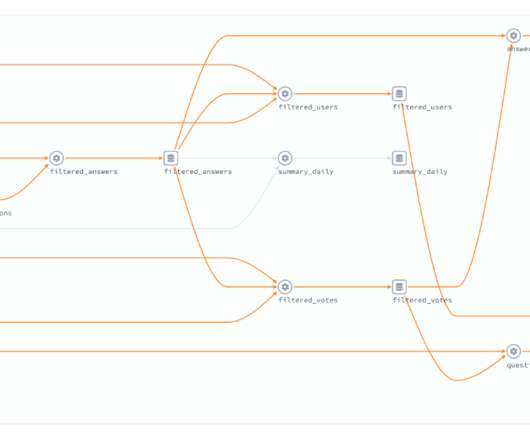
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
As the only data observability platform to provide full visibility into delta tables With our delta lake integration, Monte Carlo supports all delta tables across all metastores and all three major platform providers including Microsoft Azure, AWS and Google Cloud.
As the demand for big data grows, an increasing number of businesses are turning to cloud data warehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
Most importantly, you will need to know: the file path of your Google Cloud service account’s JSON key the name of your Google Cloud project If that doesn’t mean anything to you, never fear! Our schema has changed, and we want Datakin to have the latest metadata about tables and columns. % dbt version: 0.21.0
For additional knowledge, you can consider going for the best Cloud Computing certification courses. EC2 Instances AWS provides a web service called Amazon Elastic Compute Cloud (Amazon EC2), which facilitates resizable compute capacity. Users can avail of this service to launch virtual servers (instances) on the cloud.
The key can be a fixed-length sequence of bits or bytes. Secure Image Sharing in Cloud Storage Selective image encryption can be applied in cloud storage services where users want to share images while protecting specific sensitive content. Key Generation: A secret encryption key is generated.
RocksDB-Cloud RocksDB is an embedded key-value store. To achieve durability, we built RocksDB-Cloud. RocksDB-Cloud replicates all the data and metadata for a RocksDB instance to S3. We limit the number of bytes that can be written per second to all RocksDB instances assigned to a leaf node.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
Avro files store metadata with data and also let you specify independent schema for reading the files. 12) Mention a business use case where you worked with the Hadoop Ecosystem You can share details on how you deployed Hadoop distributions like Cloudera and Hortonworks in your organization either in a standalone environment or on the cloud.
Map Reduce programs in cloud computing are parallel, making them ideal for executing large-scale data processing across multiple machines in a cluster. It ensures that the data collected from cloud sources or local databases is complete and accurate. NameNode is often given a large space to contain metadata for large-scale files.
Avro files store metadata with data and also let you specify independent schema for reading the files. 12) Mention a business use case where you worked with the Hadoop Ecosystem You can share details on how you deployed Hadoop distributions like Cloudera and Hortonworks in your organization either in a standalone environment or on the cloud.
Geo-Replication in Kafka is a process by which you can duplicate messages in one cluster across other data centers or cloud regions. Message Broker: Kafka is capable of appropriate metadata handling, i.e., a large volume of similar types of messages or data, due to its high throughput value. config/server.properties 25.
Did you know that by default, NPM keeps all the packages and metadata it ever downloads in its cache folder indefinitely? link] So what happens is that when you install things, NPM will store the tarballs and metadata into the packages folder. That is a lot of metadata. Well it does. So far so good.
Server logs might, for example, contain additional metadata such as the referring URL, HTTP status codes, bytes delivered, and user agents. Challenge #1: Volume With the expansion of hybrid networks, cloud computing, and digital transformation, log data has also increased in volume.
hey ( credits ) 🥹It's been a long time since I've put words down on paper or hit the keyboard to send bytes across the network. At the same time they announced their model will run on-device (keeping your data safe and private) and when more compute will be required they will use a private cloud. Looks neat.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content