This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
link] Intuit: Vibe Coding in the Age of AI: Navigating the Future of Software Development 2.0 link] Intuit: Vibe Coding in the Age of AI: Navigating the Future of Software Development 2.0 It is exciting to see how far it will go and how the industry evolves around the concept of vibe coding.
Numeric data consists of four sub-types: Integer type (INT64) Numeric type (NUMERIC DECIMAL) Bignumeric type (BIGNUMERIC BIGDECIMAL) Floating point type (FLOAT64) BYTES Although they work with raw bytes rather than Unicode characters, BYTES also represent variable-length data. Deploy the model and monitor its performance.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. Worried about finding good Hadoop projects with Source Code ?
Some of the major advantages of using PySpark are- Writing code for parallel processing is effortless. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. Interview Questions on PySpark in Data Science Let us take a look at PySpark interview questions and answers related to Data Science.
String & Binary Snowflake Data Types VARCHAR, STRING, TEXT Snowflake data types It is a variable-length character string of a maximum of 16,777,216 bytes and holds Unicode characters(UTF-8). We retrieved the same by querying the newly created table implemented using the code below. WHERE clause).
Quintillion Bytes of data per day. This simple code below helps to find the duplicate values and return the values without any duplicate observations. To avoid data redundancy and retain only valid values, the code snippet below helps clean data to remove duplicates. As per statistics, we produce 2.5 Dealing with Outliers.
BigQuery charges users depending on how many bytes are read or scanned. With on-demand pricing, you are charged $5 per TB for each TB of bytes processed in a particular query (the first TB of data processed per month is completely free of charge). Source Code- How to deal with slowly changing dimensions using Snowflake?
Quotas are byte-rate thresholds that are defined per client-id. The process of converting the data into a stream of bytes for the purpose of the transmission is known as serialization. Deserialization is the process of converting the bytes of arrays into the desired data format. What do you understand about quotas in Kafka?
Streaming, batch, and interactive processing pipelines can share and reuse code and business logic. Spark Streaming Architecture Furthermore, each batch of data uses Resilient Distributed Datasets (RDDs) , the core abstraction of a fault-tolerant dataset in Spark that allows the streaming data to be processed via any library or Spark code.
quintillion bytes of data is produced daily. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Why do data engineers love Azure Data Factory? You may use a visual editor to alter data in a series of phases without having to write any additional code beyond data expressions.
It covers everything from interview questions for beginners to intermediate professionals, along with excellent coding and data science-related questions. Check out the example code below for complete implementation- The expression - df['Age'] > 25 creates a boolean mask, and using it inside the square brackets (df[.])
Our tutorial teaches you how to unlock the power of parallelism and optimize your Python code for optimal performance. ​​Imagine By leveraging multiple CPUs or even multiple machines, Python Ray enables you to parallelize your code and process data at lightning-fast speeds. Github stars, 4.3k
Built for the AI era, Components offers compartmentalized code units with proper guardrails that prevent "AI slop" while supporting code generation. If you look at all the BI or UI-based ETL tools, the code is a black box for us, but we validate the outcome generated by the black-box.
Automated Data Flow Management : With a visual design interface, NiFi simplifies the creation and management of data flows, promoting automation and reducing the need for complex coding. Content Repository The Content Repository stores the actual content bytes of a given FlowFile.
cAdvisor exported metrics documentation — describes container_referenced_bytes as an intrusive metric to collect The metric container_referenced_bytes is enabled by default in cAdvisor and tracks the total bytes of memory that a process references during each measurement cycle. This is where we ended our investigation.
We used OO design to support various deserialization methods to mimic Python lists, sets, and dictionaries, using LMDBs byte-based key-value records. The results were immediately noticeablethe memory usage on the hosts decreased by 4.5%, and we were able to add more processes running instances of our application code.
The provided code ( inspired by LangChain’s cook on GitHub ) automates extracting elements from PDFs, categorizing them, generating summaries, storing them in a vector database, and retrieving relevant multimodal context to answer user queries. The function ensures that inputs are valid Base64 strings before data processing.
Graph Support: Provides Pydantic Graph for defining complex workflows, avoiding spaghetti code, and improving project maintainability. Explore Pydantic AI GitHub Repository by ProjectPro to get the full code and start coding your own AI agent today! If input data violates the validation rules, Pydantic raises an error.
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. 15 Tableau Projects for Beginners to Practice with Source Code Big Data Engineer Salary Big Data Engineer Salary By Experience The salary of a Big Data Engineer at an entry-level is $112,555 annually in the US.
Literals in Python are the direct representations of fixed values in your code. Literals in Python are pieces of data that are saved in the source code so that your software can work properly. Literals in Python are fixed values that are written straight into the code. What Are Literals in Python?
The FAQ clarifies that Retrieval-Augmented Generation (RAG) is not dead but requires effective retrieval strategies beyond naive vector search, especially for complex tasks like coding.
A user-defined function (UDF) is a common feature of programming languages, and the primary tool programmers use to build applications using reusable code. Metadata for a file, block, or directory typically takes 150 bytes. In terms of writing code, using Python for Big Data is much faster than any other programming language.
Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. Most code examples for this certification test will be written in Python. Check out the ProjectPro repository with unique Hadoop Mini Projects with Source Code to help you grasp Hadoop basics.
Naturally, you would think that there must be something wrong with the code running in it. There is no doubt that this is the most silly piece of code I’ve ever written. The code runs in a Notebook, which means it runs in the ipykernel process, that is a child process of the jupyter-lab process. The workbench has 64CPUs.
It is the volume and fine-tuning of these parameters on the training data that make LLMs versatile and adaptable across various applications, from text generation and language translation to code generation and conversational AI, making them invaluable for businesses and data scientists looking to automate and optimize tasks.
With working code snippets and in-depth explanations, you’ll gain hands-on experience to develop your model and see the process in action. For example, BERT uses WordPiece, while GPT uses byte pair encoding (BPE). The Gradio Blocks code snippet that does the following: Defines a web interface layout using Gradio Blocks.
Any company looking to hire a Hadoop Developer is looking for Hadoopers who can code well - beyond the basic Hadoop MapReduce concepts. Coprocessor in HBase is a framework that helps users run their custom code on Region Server. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on July 18, 2025 in Python Image by Author | Canva What if there is a way to make your Python code faster? __slots__ in Python is easy to implement and can improve the performance of your code while reducing the memory usage. Let’s see the code. to_numpy().ravel(),
quintillion bytes of data generated daily, the landscape is ripe for skilled individuals to step in and make sense of this wealth of information. Check out these data science projects with source code in Python today! With over 2.5 According to the U.S. Struggling with solved data science projects?
Customize at the Edge CloudFront allows you to run serverless code at the edge, which opens up possibilities for customizing content and delivering personalized experiences to your users with reduced latency. Object Delivery: CloudFront starts forwarding the object to the user when it receives the first byte from the origin server.
Image Processing Projects Ideas in Python with Source Code for Hands-on Practice to develop your computer vision skills as a Machine Learning Engineer. ” Despite the advantages images have over text data, there is no denying the complexities that the extra bytes they eat up can bring. imread('gray.png', cv2.IMREAD_GRAYSCALE)
Backend code I wrote and pushed to prod took down Amazon.com for several hours. and hand-rolled C -code. To update code, we flipped a symlink ( a symbolic link is a file whose purpose is to point to a file or directory ) to swap between the code and HTML files contained in these directories.
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Brief overview of image coding formats The JPEG format was introduced in 1992 and is widely popular. This is followed by quantization and entropy coding. Advanced Video Coding ( AVC ) format.
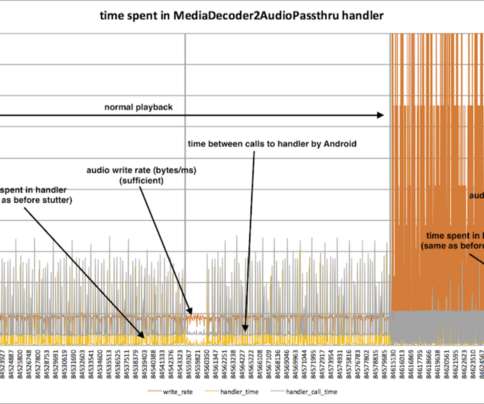
Next I started reading the Ninja source code. I wanted to find the precise code that delivers the audio data. I recognized a lot, but I started to lose the plot in the playback code and I needed help. You can see three distinct behaviors in this chart: The two, tall spiky parts where the data rate reaches 500 bytes/ms.
In short, debug symbols are extra “stuff” in your intermediate object files — and ultimately in your executables — that help your debugger map the machine code being executed back into higher-level source code concepts like variables and functions. corresponds to which part of the source code (variables, functions, etc.).
Source code 2. Source code 3. Source code 4. Source Code Cyber Security Final Year Projects 1. Source code 2. Source code 3. The project will focus on creating a user-friendly interface as a web / Desktop application and incorporating robust algorithms to assess password strength accurately.
How it works: Millisampler comprises userspace code to schedule runs, store data, and serve data, and an eBPF-based tc filter that runs in the kernel to collect fine-timescale data. The user code attaches the tc filter and enables data collection. Millisampler collects a variety of metrics.
Challenges Large packet size One of the main challenges is the size of the Kyber768 public key share, which is 1184 bytes. This is close to the typical TCP/IPv6 maximum segment size (MSS) of 1440 bytes, but is still fine for a full TLS handshake. However, the key size becomes an issue during TLS resumption.
Meta’s Native Assurance team regularly performs manual code reviews as part of our ongoing commitment to improve the security posture of Meta’s products. For example, it uses SELinux policies to reduce the attack surfaces exposed to unprivileged code running on the device.
Chart 2: Bytes logged per second via Legacy versus Tulip. We can see that while the number of logging schemas remained roughly the same (or saw some organic growth), the bytes logged saw a significant decrease due to the change in serialization format. Reader (like logger) comes in two flavors , (a) code generated and (b) generic.
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
reading and writing to a byte stream). Say we have some arbitrary Python class, a first approximation may be to define encode and decode methods: from typing import Self class MyClass : def encode ( self ) - > bytes : # Implementation goes here. classmethod def decode ( cls , data : bytes ) - > Self : # Implementation goes here.
An Avro file is formatted with the following bytes: Figure 1: Avro file and data block byte layout The Avro file consists of four “magic” bytes, file metadata (including a schema, which all objects in this file must conform to), a 16-byte file-specific sync marker, and a sequence of data blocks separated by the file’s sync marker.
Impala has always focused on efficiency and speed, being written in C++ and effectively using techniques such as runtime code generation and multithreading. For instance, in both the struct s above the largest member is a pointer of size 8 bytes. Total size of the Bucket is 16 bytes. Folding data into pointers.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content