This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Streaming, batch, and interactive processing pipelines can share and reuse code and business logic. Spark Streaming Architecture Furthermore, each batch of data uses Resilient Distributed Datasets (RDDs) , the core abstraction of a fault-tolerant dataset in Spark that allows the streaming data to be processed via any library or Spark code.
cAdvisor exported metrics documentation — describes container_referenced_bytes as an intrusive metric to collect The metric container_referenced_bytes is enabled by default in cAdvisor and tracks the total bytes of memory that a process references during each measurement cycle. This means memory use can be significant (e.g.
Trusted by top companies like Adobe, Amazon, Google, and OpenAI, Pydantic simplifies data validation and structure definition, making it easier to build scalable, production-grade AI applications. Graph Support: Provides Pydantic Graph for defining complex workflows, avoiding spaghetti code, and improving project maintainability.
Literals in Python are the direct representations of fixed values in your code. Literals in Python are pieces of data that are saved in the source code so that your software can work properly. Literals in Python are fixed values that are written straight into the code. What Are Literals in Python?
Naturally, you would think that there must be something wrong with the code running in it. There is no doubt that this is the most silly piece of code I’ve ever written. The code runs in a Notebook, which means it runs in the ipykernel process, that is a child process of the jupyter-lab process. The workbench has 64CPUs.
Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. Most code examples for this certification test will be written in Python. Check out the ProjectPro repository with unique Hadoop Mini Projects with Source Code to help you grasp Hadoop basics.
If the content is unavailable in that edge location, CloudFront retrieves it from a designated origin, such as an Amazon S3 bucket, a MediaPackage channel, or an HTTP server that serves as the definitive source for the content. Source: medium.com/tensult Worried about finding good Hadoop projects with Source Code ?
They allow the definition of “interfaces for types”, where values of types which conform to that specification can be freely swapped out. reading and writing to a byte stream). classmethod def decode ( cls , data : bytes ) - > Self : # Implementation goes here. traits” in Rust and “concepts” in C++20). write ( obj.
Chart 2: Bytes logged per second via Legacy versus Tulip. We can see that while the number of logging schemas remained roughly the same (or saw some organic growth), the bytes logged saw a significant decrease due to the change in serialization format. Reader (like logger) comes in two flavors , (a) code generated and (b) generic.
We’ll demonstrate using Gradle to execute and test our KSQL streaming code, as well as building and deploying our KSQL applications in a continuous fashion. In this way, registration queries are more like regular data definition language (DDL) statements in traditional relational databases. Managing KSQL dependencies.
See the graph below, which shows the compaction read and write bytes on a cluster when it is bootstrapping for the first time. Figure 10: compaction read and write bytes showing non zero values as soon as host starts up. This slow bootstrap time was a definite hindrance on our move to less compute heavy instances for cost savings.
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
By default, gRPC uses protobuf as its IDL (interface definition language) and data serialization protocol. Our protobuf message definition (.proto link] When the protobuf compiler (protoc) compiles this message definition, it creates the code in the language of your choice (Java in our example).
Instead, we chose to use an envoy circuitbreaker , which returns an HTTP 503 code immediately to the downstream caller. This should definitely help bring down the downtime further given that all of the steps for replication, cutting the traffic over to the upgraded DB, and the rollback setup would be handled within their platform.
For alert stream rates low enough such that scientists can visually inspect messages, this format can definitely be appropriate. Much of the code used by modern astronomers is written in Python, so the ZTF alert distribution system endpoints need to at least support Python. Alert data pipeline and system design.
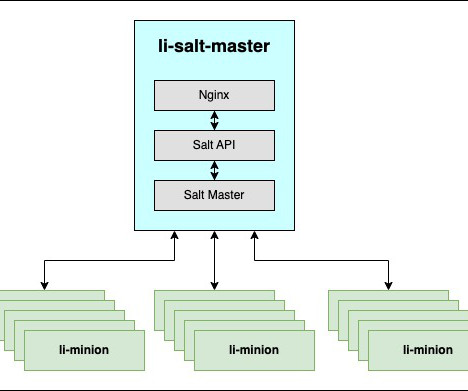
li-minion : Installable python agent which gets installed on all 300K + hosts, It is wrapped & packaged as RPM with customized code which automatically discovers relevant master hosts and generates minion config on every start. This product enforces security checks on clients modules to ensure clients are following safe coding practices.
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). Seagate Technology forecasts that enterprise data will double from approximately 1 to 2 Petabytes (one Petabyte is 10^15 bytes) between 2020 and 2022.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. We provide the functions: prefix to reference the subproject directory with our code. jar Zip file size: 5849 bytes, number of entries: 5.
So, all the code snippets in this article will use the following logger: static final Logger logger = LoggerFactory. So, all the code snippets in this article will use the following logger: static final Logger logger = LoggerFactory. Moreover, we’ll also use Lombok to reduce the boilerplate code when dealing with checked exceptions.
By the end of this course, expect to write 300-400 lines of code. It’s a jam-packed, long-form, hands-on course where you’ll write not hundreds but thousands of lines of code from scratch in dozens of examples and exercises, including an image processing project that you can use for your own pictures. They are constants once defined.
At the highest level, the definition of the Passport is as follows: message Passport { Header header = 1; UserInfo user_info = 2 ; DeviceInfo device_info = 3 ; Integrity user_integrity = 4 ; Integrity device_integrity = 5 ; } The Header element communicates the name of the service that created the Passport.
It is ideal for cross-platform applications because it is a compiled language with object code that can work across more than one machine or processor. All programming is done using coding languages. Java, like Python or JavaScript, is a coding language that is highly in demand. So, the Java developer’s key skills are: 1.
Definition : A namespace is a logical collection of a unique set of metric configurations/properties like rollup support, backfilling capability, TTL, etc. We had to make sure the code changes did not affect the query SLA we had set with the client team. We browsed through the code of the folly version we wereusing.
Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation. A solution is to read the bytes that we need when we need them directly from Blob Storage. open ( "container/file.svs" ) as f : # read the first 256 bytes print ( f.
When we enabled brotli in a straightforward manner, it reduced bytes sent as expected. In the end, we decided that the brotli treatment was better mainly on the basis of sending 10% fewer bytes over the wire. Does sending fewer bytes actually drive performance? In hindsight, there was a lot of evidence that I was wrong.
We need to know network delay, round trip time, a protocol’s handshake latency, time-to-first-byte and time-to-meaningful-response. One of these metrics is time-to-first-byte. Workload definition language The workload definition language is one of the challenges we’re looking to solve. We need to develop new metrics (e.g.
IValue is always 16 bytes, and does not allocate heap memory for integers, booleans, floating-point numbers, and short strings. Strings We handle character strings and byte strings similarly; the value of tag1 is the only difference. tag0 is usually a subtype, and the meaning of the other two fields changes depending on type.
The other advantage is because we follow a standard design, we are able to generate a lot of our code using code templates and metadata. The metadata contains our data mappings and the code templates contain the expected structure of our ETL code scripts/files,” he said.
Such libraries use the advanced type system of the Scala language (and/or some macro magic for some specific information not provided by types alone) to generate code and compile-time that otherwise would have to be written by hand or by using reflection – and no-one wants to write those JsObjects by hand.
Given that definition, event time will never change, but processing time changes constantly for each event as it flows through the pipeline step. Triggering based on data-arriving characteristics such as counts, bytes, data punctuations, pattern matching, etc. Triggering at completion estimates such as watermarks.
Programming is the process of developing software or applications by coding in a specific language. Programming languages such as Python, Ruby, and Java are used to write code that can be executed by a computer. What is Programming? Programming is basically an application that performs a specific task or solves a complex problem.
With more than eight years of experience in diverse industries, Sarwat has spent the last four building over 20 data pipelines in both Python and PySpark with hundreds of lines of code. The entirety of the code resided in one colossal repository, a monolith without a solid structure to ensure bug-free production code.
Streaming, batch, and interactive processing pipelines can share and reuse code and business logic. Spark Streaming Architecture Furthermore, each batch of data uses Resilient Distributed Datasets (RDDs) , the core abstraction of a fault-tolerant dataset in Spark that allows the streaming data to be processed via any library or Spark code.
Updating build.sbt To follow along add the following code to the build.sbt : val Http4sVersion = "0.23.23" val CirceVersion = "0.14.6" First, create a resources folder under main , then under resources add a chat.html file with the following code: <!Doctype Setting Up 2.1. fromPath ( fs2. Within the HttpRoutes.of[F]{} import fs2.io.net.Network
file with the following code: const sqlite3 = require ( "sqlite3" ). INTEGER : The value is a signed integer, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. REAL : The value is a floating point value, stored as an 8-byte IEEE floating point number. in addition to the SQLite library.
39 How to Prevent a Data Mutiny Key trends: modular architecture, declarative configuration, automated systems 40 Know the Value per Byte of Your Data Check if you are actually using your data 41 Know Your Latencies key questions: how old is data? We handle the "_deleted" table approach already. What does that do? Increase visibility.
Having knowledge of advanced Java concepts for hadoop is a plus but definitely not compulsory to learn hadoop. The choice for using Java for hadoop development was definitely a right decision made by the team with several Java intellects available in the market. Your search for the question “How much Java is required for Hadoop?”
For example, if you were measuring absolute table size, you would could trigger an event when: The current total size (bytes or rows) decreases to a specific volume The current total size remains the same for a specific amount of time Numeric distribution tests Is my data within an accepted range? Image courtesy of Monte Carlo.
read_csv works quickly and efficiently, and it’s also efficient to read in code. quintillion bytes of data, and the immensity of today’s data has made data engineers more important than ever. And there are many other options that allow data practitioners to focus on their goals instead of having to worry about programming details.
You then control the controller by providing colour data as an RGB byte sequence using just a single pin. There are definite parallels to software development somewhere in there… Anyhow, after hunting around the IKEA website I found a BLANDA MATT (bamboo serving bowl) that I figured upended, was about the right size and shape for a base.
Binary Data types It includes Variable/Fixed binary data types such as maximum length of 8000 bytes. Triggers Triggers refer to SQL codes that are executed on their own in response to some events on a specific table. Date / Time Data Types Includes DATE, DATETIME (fsp), TIMESTAMP (fsp), TIME (fsp), YEAR.
8) Difference between ADLS and Azure Synapse Analytics Fig: Image by Microsoft Highly scalable and capable of ingesting and processing enormous amounts of data, Azure Data Lake Storage Gen2 and Azure Synapse Analytics are both available (on a Peta Byte scale). 2) What is Azure’s primary ETL service? 30) What are dataflow mappings?
It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. Creating secure architectures with defined controls and manageable as code in version-controlled templates. Amazon S3 Amazon S3 is an object storage service which allows users to store and retrieve data from anywhere using the internet.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content