This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. This results in a fast and scalable metadata handling system.
Some of the major advantages of using PySpark are- Writing code for parallel processing is effortless. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects. We can store the data and metadata in a checkpointing directory. Mention some of the major advantages and disadvantages of PySpark.
Built for the AI era, Components offers compartmentalized code units with proper guardrails that prevent "AI slop" while supporting code generation. If you look at all the BI or UI-based ETL tools, the code is a black box for us, but we validate the outcome generated by the black-box. and Lite 2.0)
This layer stores the metadata needed to optimize a query or filter data. To enable and keep table maintenance simpler, all DML functions (such as DELETE and UPDATE) make use of the underlying micro-partition metadata. For instance, only a small number of operations, such as deleting all of the records from a table, are metadata-only.
Our tutorial teaches you how to unlock the power of parallelism and optimize your Python code for optimal performance. ​​Imagine By leveraging multiple CPUs or even multiple machines, Python Ray enables you to parallelize your code and process data at lightning-fast speeds. Github stars, 4.3k
Message Broker: Kafka is capable of appropriate metadata handling, i.e., a large volume of similar types of messages or data, due to its high throughput value. Quotas are byte-rate thresholds that are defined per client-id. Deserialization is the process of converting the bytes of arrays into the desired data format.
Standardization of file formats, encodings, and metadata ensures consistency and smooth downstream processing. These databases employ indexing techniques like HNSW and FAISS , ensuring optimized search capabilities while preserving metadata and relationships between modalities.
NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. The following are the steps to follow in a NameNode recovery process: Launch a new NameNode using the FsImage (the file system metadata replica).
Graph Support: Provides Pydantic Graph for defining complex workflows, avoiding spaghetti code, and improving project maintainability. Explore Pydantic AI GitHub Repository by ProjectPro to get the full code and start coding your own AI agent today! If input data violates the validation rules, Pydantic raises an error.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
The FAQ clarifies that Retrieval-Augmented Generation (RAG) is not dead but requires effective retrieval strategies beyond naive vector search, especially for complex tasks like coding. The architecture uses Python, Piper (Airflow-based orchestrator), Terrablob (S3 abstraction) for cold storage, and MySQL for metadata.
Any company looking to hire a Hadoop Developer is looking for Hadoopers who can code well - beyond the basic Hadoop MapReduce concepts. Coprocessor in HBase is a framework that helps users run their custom code on Region Server. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Brief overview of image coding formats The JPEG format was introduced in 1992 and is widely popular. This is followed by quantization and entropy coding. Advanced Video Coding ( AVC ) format.
An Avro file is formatted with the following bytes: Figure 1: Avro file and data block byte layout The Avro file consists of four “magic” bytes, file metadata (including a schema, which all objects in this file must conform to), a 16-byte file-specific sync marker, and a sequence of data blocks separated by the file’s sync marker.
This file includes: Metadata ?—?This That is, all mounted files that were opened and every single byte range read that MezzFS received. Finally, MezzFS will record various statistics about the mount, including: total bytes downloaded, total bytes read, total time spent reading, etc. File operations ?—?All Actions ?—?MezzFS
The bucket in itself is actually nothing but a collection of SST files holding all the time series data and metadata for the corresponding bucket size. See the graph below, which shows the compaction read and write bytes on a cluster when it is bootstrapping for the first time. The bucket id is unix time divided by bucket size.
We’ll demonstrate using Gradle to execute and test our KSQL streaming code, as well as building and deploying our KSQL applications in a continuous fashion. The first requirement to tackle: how to express dependencies between KSQL queries that exist in script files in a source code repository. Managing KSQL dependencies.
This framework does not require any code changes to the system-under-test that is being validated. One key part of the fault injection service is a very lightweight passthrough fuse file system that is used by Ozone for storing all its persistent data and metadata. No changes to Ozone code required for simulating failures.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Each version contains metadata (keys and values) and a data pointer. You can think of a data pointer as special metadata that points to where the actual data you published is stored. Direct data pointers are automatically replicated globally.
It is ideal for cross-platform applications because it is a compiled language with object code that can work across more than one machine or processor. All programming is done using coding languages. Java, like Python or JavaScript, is a coding language that is highly in demand. So, the Java developer’s key skills are: 1.
architecture (with some minor deviations) to achieve their data integration objectives around scalability and use of metadata. “A The other advantage is because we follow a standard design, we are able to generate a lot of our code using code templates and metadata. This layer has minimal transformation rules.
88% of respondents “Always” or “Often” use Types in their Python code. The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation.
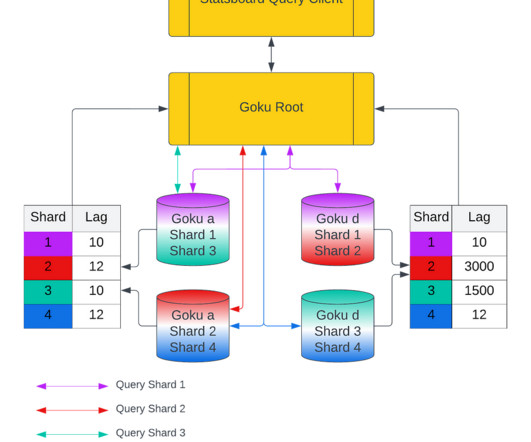
Indexing Improvements for Metric Name(GokuS) A time series metadata or key consists of the following Multiple hosts can emit time series for a unique metric name (e.g. We had to make sure the code changes did not affect the query SLA we had set with the client team. We browsed through the code of the folly version we wereusing.
Full code on GitHub. Note that the MappingProcessor and FilteringProcessor code is omitted here for clarity. Full code on GitHub. Full code on GitHub. Full code on GitHub. Below shows how this simple application can be written with the Processor API: final Topology topology = new Topology(); topology. of(Duration.
Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation. A solution is to read the bytes that we need when we need them directly from Blob Storage. open ( "container/file.svs" ) as f : # read the first 256 bytes print ( f.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
Spark Structured Streaming is a powerful streaming framework that can easily satisfy the requirements described above with a few lines of code (about 70 in our case) but the cost profile is pretty high. Despite the relative simplicity of the code, the cluster resources necessary are significant.
DoorDash’s internal platform team already has built many features which come in handy, like an Asgard-based microservice, which comes with a good set of built-in features like request-metadata, logging, and dynamic-value framework integration. New input formats: Currently, the platform is supporting byte-based input.
Once there, you will see two lines of code that look similar to these: export OPENLINEAGE_URL=[link] export OPENLINEAGE_API_KEY={{YOUR_API_KEY}} Run these two export commands, making sure to replace the {{ TOKENS }} if you didn’t copy and paste them from the docs. These are most conveniently found in Docs page of your Datakin instance.
This layer stores the metadata needed to optimize a query or filter data. To enable and keep table maintenance simpler, all DML functions (such as DELETE and UPDATE) make use of the underlying micro-partition metadata. For instance, only a small number of operations, such as deleting all of the records from a table, are metadata-only.
During the development phase, the team agreed on a blend of PyCharm for developing code and Jupyter for interactively running the code. StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. sports activities).
This would hold the set of all possible features (in this case, all article IDs), and the code is brute forcing all of them in order to reconstruct the set of articles viewed by the user. With key-value-store-based feature stores, the additional cost of storing some metadata (like event timestamps) is relatively minor. Uncompressed).
The key can be a fixed-length sequence of bits or bytes. By encrypting specific regions or metadata within images, investigators can ensure that the crucial details remain tamper-proof and secure, providing reliable evidence in legal proceedings. Key Generation: A secret encryption key is generated.
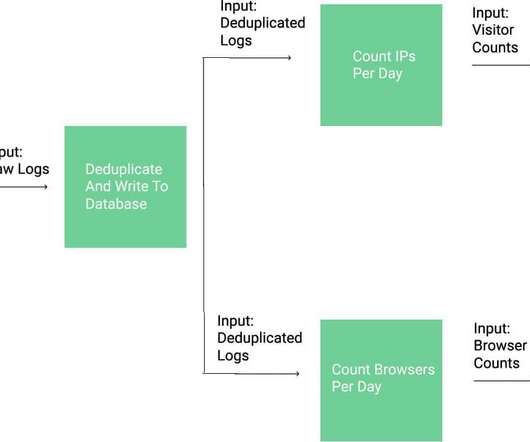
As it serves the request, the web server writes a line to a log file on the filesystem that contains some metadata about the client and the request. status — the response status code from the server. body_bytes_sent — the number of bytes sent by the server to the client in the response body. 200 30294 "[link] "Mozilla/5.0 (X11;
Any company looking to hire a Hadoop Developer is looking for Hadoopers who can code well - beyond the basic Hadoop MapReduce concepts. Coprocessor in HBase is a framework that helps users run their custom code on Region Server. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
Foundational encoding, whether it is ASCII or another byte-level code, is delimited correctly into fields or columns and packaged correctly into JSON, parquet, or other file system. It should detect “schema drift,” and may involve operations that validate datasets against source system metadata, for example. In a valid schema.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
tesla-integration" You’ll notice in the results that not only will you see the lat and long you sent to the Kafka topic but some metadata that Rockset has added too including an ID, a timestamp and some Kafka metadata, this can be seen in Fig 2. js Now we have a map rendering, we need some code to fetch our points from Rockset.
NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. The following are the steps to follow in a NameNode recovery process: Launch a new NameNode using the FsImage (the file system metadata replica).
It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. In S3, data consists of the following components – key (name), value (data), version ID, metadata and access control lists. Creating secure architectures with defined controls and manageable as code in version-controlled templates.
Yahoo (One of the biggest user & more than 80% code contributor to Hadoop ) Facebook Netflix Amazon Adobe eBay Hulu Spotify Rubikloud Twitter Click on this link to view a detailed list of some of the top companies using Hadoop. Avro files store metadata with data and also let you specify independent schema for reading the files.
Yahoo (One of the biggest user & more than 80% code contributor to Hadoop ) Facebook Netflix Amazon Adobe eBay Hulu Spotify Rubikloud Twitter Click on this link to view a detailed list of some of the top companies using Hadoop. Avro files store metadata with data and also let you specify independent schema for reading the files.
Message Broker: Kafka is capable of appropriate metadata handling, i.e., a large volume of similar types of messages or data, due to its high throughput value. Quotas are byte-rate thresholds that are defined per client-id. Deserialization is the process of converting the bytes of arrays into the desired data format.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content