This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we will discuss the AvroTensorDataset API, techniques we used to improve dataprocessing speeds by up to 162x over existing solutions (thereby decreasing overall training time by up to 66%), and performance results from benchmarks and production. an array within a map, within a union, etc…).
Introduction In the field of data warehousing, there’s a universal truth: managing data can be costly. Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. But let me give you a magical spell to appease the dragon: burn data, not money! in europe-west3.
The purpose was to accelerate the dataprocessing operations commonly found in our workloads in ways that were not possible using Arrow. In the new representation , the first four bytes of the view object always contain the string size. first writing StringView at position 2, then 0 and 1).
In the age of AI, enterprises are increasingly looking to extract value from their data at scale but often find it difficult to establish a scalable data engineering foundation that can process the large amounts of data required to build or improve models. For conversion, if you’re just getting started, start small.
Foresighted enterprises are the ones who will be able to leverage this data for maximum profitability through dataprocessing and handling techniques. With the rise in opportunities related to Big Data, challenges are also bound to increase. Below are the 5 major Big Data challenges that enterprises face in 2024: 1.
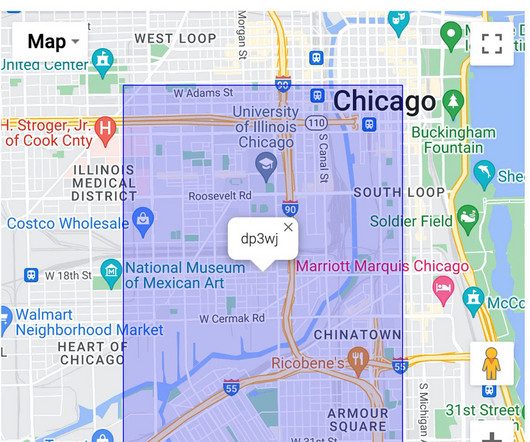
It consists of approximately 8 million rows of data (with a total amount of 1.52 GB) recording incidents of crime that occurred in Chicago since 2001, where each record has geographic data indicating the incident’s location. Big Query provides the job execution details for every query executed. GB to 55 MB and 7M to 260k).
Pinterest’s real-time metrics asynchronous dataprocessing pipeline, powering Pinterest’s time series database Goku, stood at the crossroads of opportunity. The mission was clear: identify bottlenecks, innovate relentlessly, and propel our real-time analytics processing capabilities into an era of unparalleled efficiency.
Google's Dremel is an interactive ad-hoc query solution for analyzing read-only hierarchical data. The dataprocessing architectures of BigQuery and Dremel are slightly similar, however. It can processdata stored in Google Cloud Storage, Bigtable, or Cloud SQL, supporting streaming and batch dataprocessing.
The dataprocessing pipeline characterizes these objects, deriving key parameters such as brightness, color, ellipticity, and coordinate location, and broadcasts this information in alert packets. Part of the alert data that we need to distribute is a small cutout image (or “postage stamp”) of the transient candidate.
The solution is as simple but highly effective as adopting incremental dataprocessing and applying ownership and lining style conventions. I like the 3G model with Guardrails, Guidelines & Gadget, which I’m sure I will use more often :-). Rebalancing, the awkward middle child.
Big data sets are generally huge – measuring tens of terabytes – and sometimes crossing the threshold of petabytes. It is surprising to know how much data is generated every minute. quintillion bytes of data are created every single day, and it’s only going to grow from there. As estimated by DOMO : Over 2.5
Balancing correctness, latency, and cost in unbounded dataprocessing Image created by the author. Intro Google Dataflow is a fully managed dataprocessing service that provides serverless unified stream and batch dataprocessing. Triggering at the point in processing time.
Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation. Besides, even if we mounted multiple disks, the cost and time it would take to transfer all this data on every new machine would be too much.
In this article, we’ll explore what Snowflake Snowpark is, the unique functionalities it brings to the table, why it is a game-changer for developers, and how to leverage its capabilities for more streamlined and efficient dataprocessing. This is crucial for organizations that use both SQL and Python for dataprocessing and analysis.
Better decision-making: Real-time insights into dataprocessing allow for more informed decisions about resource allocation or process optimization. 5 Things You Must Monitor in a Data Pipeline To achieve observability, track specific metrics and events that provide insights into your pipeline’s functionality.
I’d been hearing lots of talk about Bun, particularly on the Bytes email blast but hadn’t had a chance to properly check it out so I was particularly interested in seeing how it did. For the most part, it worked fine but some of the more intensive dataprocessing challenges were painfully slow to run, despite my best efforts at optimising.
We need to know network delay, round trip time, a protocol’s handshake latency, time-to-first-byte and time-to-meaningful-response. One of these metrics is time-to-first-byte. You can measure network delay, round trip time, protocol handshake times, time-to-first-byte and time-to-meaningful-response.
Discretized Streams, or DStreams, are fundamental abstractions here, as they represent streams of data divided into small chunks(referred to as batches). As a result, we can easily apply SQL queries (using the DataFrame API) or scala operations (using the DataSet API) to stream data through this library. split("W+"))).groupBy((key,
Another talk I would like to mention was given by Jan Pustelnik about Reactive Streams for fast dataprocessing. Being familiar with these, the highlight for me was that stream processing your data is not a new idea at all. Throw a few macros into the mix and you're already getting into mind-bending territory.
This problem is not new in dataprocessing. So the problem is: How can the Streams DSL be able to “rewrite” a user’s specified computational logic automatically to generate efficient processor topologies? In DBMS, for example, it has a famous term: query optimization.
Snowflake Data Marketplace gives users rapid access to various third-party data sources. Moreover, numerous sources offer unique third-party data that is instantly accessible when needed. Snowflake's machine learning partners transfer most of their automated feature engineering down into Snowflake's cloud data platform.
Data tracking is becoming more and more important as technology evolves. A global data explosion is generating almost 2.5 quintillion bytes of data today, and unless that data is organized properly, it is useless. Some important big dataprocessing platforms are: Microsoft Azure.
To mitigate this, in Python v2, we replaced the intermediate processing batches with Parquet storage and loaded the table once into the database, rather than after each batch. This strategy dramatically reduced processing time and network costs. Our answer to this challenge lay in big dataprocessing.
36 Give Data Products a Frontend with Latent Documentation Document more to help everyone 37 How Data Pipelines Evolve Build ELT at mid-range and move to data lakes when you need scale 38 How to Build Your Data Platform like a Product PM your data with business. Increase visibility. how fast are queries?
Strings are important in the process of parsing and extraction of information in dataprocessing and analysis. It is for this reason that value is put on techniques applied to natural language processing with regard to the manipulation of strings.
Apache Hadoop solves big dataprocessing challenges using distributed parallel processing in a novel way. Hadoop Java MapReduce Programming Model Component- Java based system tool HDFS is the virtual file system component of Hadoop that splits a huge data file into smaller files to be processed by different processors.
This blog covers the most valuable data engineering certifications worth paying attention to in 2023 if you plan to land a successful job in the data engineering domain. Why Are Data Engineering Skills In Demand? The World Economic Forum predicts that by 2025, 463 exabytes of data will be produced daily across the world.
Amazon S3 Amazon S3 is an object storage service which allows users to store and retrieve data from anywhere using the internet. It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. Data objects are stored redundantly across multiple devices in several locations. wherever necessary.
These operations should ensure that your data is: In the correct format. Foundational encoding, whether it is ASCII or another byte-level code, is delimited correctly into fields or columns and packaged correctly into JSON, parquet, or other file system. They are foundational, and without them, the subsequent stages will fail.
It is intended to process enormous amounts of data, including tables with hundreds of millions of rows. 14) What are Azure Databricks, and how are they unique from standard data bricks? An open-source big dataprocessing platform is Apache Spark in its Azure version. However, there are some distinctions.
The desire to save every bit and byte of data for future use, to make data-driven decisions is the key to staying ahead in the competitive world of business operations. For the same cost, organizations can now store 50 times as much data as in a Hadoop data lake than in a data warehouse.
Confused over which framework to choose for big dataprocessing - Hadoop MapReduce vs. Apache Spark. This blog helps you understand the critical differences between two popular big data frameworks. Hadoop and Spark are popular apache projects in the big data ecosystem. It allows you to process just a batch of stored data.
Author : Zachary Ennenga Airbnb’s new office building, 650 Townsend Background At Airbnb, our offline dataprocessing ecosystem contains many mission-critical, time-sensitive jobs — it is essential for us to maximize the stability and efficiency of our data pipeline infrastructure. How does this even happen?
Data Storage: The next step after data ingestion is to store it in HDFS or a NoSQL database such as HBase. HBase storage is ideal for random read/write operations, whereas HDFS is designed for sequential processes. DataProcessing: This is the final step in deploying a big data model. How to avoid the same.
Log compaction ensures that any consumer processing the log from the start can view the final state of all records in the original order they were written. Quotas are byte-rate thresholds that are defined per client-id. Apache Storm is a distributed real-time processing system that allows the processing of very large amounts of data.
MapReduce Apache Spark Only batch-wise dataprocessing is done using MapReduce. Apache Spark can handle data in both real-time and batch mode. The data is stored in HDFS (Hadoop Distributed File System), which takes a long time to retrieve. PySpark Data Science Interview Questions Q1.
Big Data Hadoop Interview Questions and Answers These are Hadoop Basic Interview Questions and Answers for freshers and experienced. Hadoop vs RDBMS Criteria Hadoop RDBMS Datatypes Processes semi-structured and unstructured data. Processes structured data. RowKey is internally regarded as a byte array.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content