This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. Key insights from this shiftinclude: A Data-Centric Approach : Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one.
Dagster Components is now here Components provides a modular architecture that enables data practitioners to self-serve while maintaining engineering quality. Understanding this fact will help data tools break new ground with the advancement of AI agents. and Lite 2.0) to pinpoint drop-offs and high retention sections.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. Delta Lake is a game-changer for big data.
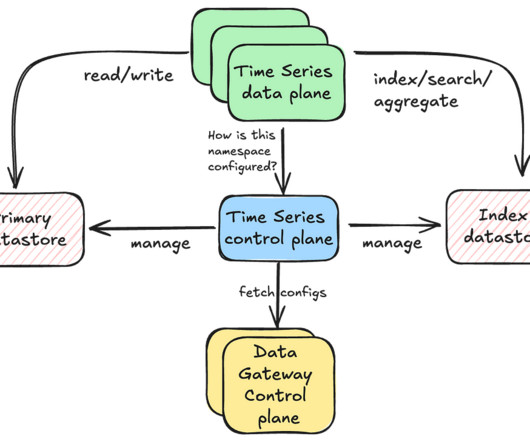
Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. Data Model At its core, the KV abstraction is built around a two-level map architecture.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Resilient Distributed Datasets (RDDs) are the fundamental data structure in Apache Spark.
However, we found that many of our workloads were bottlenecked by reading multiple terabytes of input data. To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. Avro serializes or deserializes data based on data types provided in the schema.
We’ve partnered with Voltron Data and the Arrow community to align and converge Apache Arrow with Velox , Meta’s open source execution engine. This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable.
As the demand for big data grows, an increasing number of businesses are turning to cloud data warehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
Make the most out of your BigQuery usage, burn data rather than money to create real value with some practical techniques. · ? Introduction In the field of data warehousing, there’s a universal truth: managing data can be costly. But let me give you a magical spell to appease the dragon: burn data, not money!
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
The year 2024 saw some enthralling changes in volume and variety of data across businesses worldwide. The surge in data generation is only going to continue. Foresighted enterprises are the ones who will be able to leverage this data for maximum profitability through data processing and handling techniques.
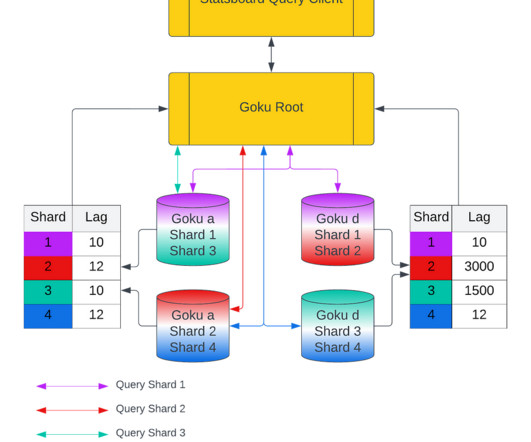
Goku is our in-house time series database providing cost efficient and low latency storage for metrics data. In the first blog, we will share a short summary on the GokuS and GokuL architecture, data format for Goku Long Term, and how we improved the bootstrap time for our storage and serving components.
As described by the white paper Apple ProRes ( link ), the target data rate of the Apple ProRes HQ for 1920x1080 at 29.97 The inspection stage examines the input media for compliance with Netflix’s delivery specifications and generates rich metadata. Uploading and downloading data always come with a penalty, namely latency.
RAG (Retrieval-Augmented Generation) changed the game for AI by enhancing text-based retrieval and generation, enabling more relevant and contextual responses with real-time data. The system intelligently manages various data types within the context window, ensuring coherent relationships between them. FAQs What is Multimodal RAG?
In addition to improving download speed, this is useful for cutting down on cross-region transfer costs when many workers will be processing the same data?—?we during a typical week at Netflix, MezzFS performs ~100 million mounts for dozens of different use cases and streams about ~25 petabytes of data. This file includes: Metadata ?—?This
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. JPEG can ingest RGB data and transform it to a luma-chroma representation before performing lossy compression. Given the image-heavy nature of the UI, compressing these images well is of primary importance.
The Big Data industry will be $77 billion worth by 2023. According to a survey, big data engineering job interviews increased by 40% in 2020 compared to only a 10% rise in Data science job interviews. Table of Contents Big Data Engineer - The Market Demand Who is a Big Data Engineer? Who is a Big Data Engineer?
If you're looking to break into the exciting field of big data or advance your big data career, being well-prepared for big data interview questions is essential. Get ready to expand your knowledge and take your big data career to the next level! “Data analytics is the future, and the future is NOW!
Netflix, and particularly Studio applications (and Studio in the Cloud) produce petabytes of data backed by billions of media assets. To support such use cases, access control at the user workspace and project workspace granularity is extremely important for presenting a globally consistent view of pertinent data to these artists.
Data is read from and written to the leader for a given partition, which could be on any of the brokers in a cluster. When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. This is the metadata that’s passed back to clients.
HBase provides real-time read or write access to data in HDFS. Data can be stored in HDFS directly or through HBase. Master node manages the cluster and region servers in HBase store portions of the HBase tables and perform data model operations. Delete Method- To delete the data from HBase tables.
Get ready to supercharge your data processing capabilities with Python Ray! ​​Imagine you're a data scientist working with massive amounts of data, and you need to train complex machine learning models that can take days or even weeks to complete. This is where Python Ray comes in.
Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! In that case, this blog on the most popular 100+ Apache Kafka interview questions and answers will help you nail your next big data job interview. Consumers read data from the brokers.
Introduction: Encryption of Data at Rest is a highly desirable or sometimes mandatory requirement for data platforms in a range of industry verticals including HealthCare, Financial & Government organizations. HDFS Encryption prevents access to clear text data. Each HDFS file is encrypted using an encryption key.
We have several frameworks that periodically refresh large amounts of on-heap data to avoid external service calls for efficiency. These periodic refreshes of on-heap data are great at taking G1 by surprise, resulting in pause time outliers well beyond the default pause time goal.
It is also possible to simulate transient bad blocks that can return correct data after a while or after a restart. . Randomly injecting a failure and hoping to catch race conditions and possible data corruption may not always be fruitful. A failure action is either a delay, an error code or corrupt data chunks.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. consumers subscribe to data and are updated to the latest versions when they are published. Each version of the dataset is immutable and represents a complete view of the data?—?there there is no dependency on previous versions of data.
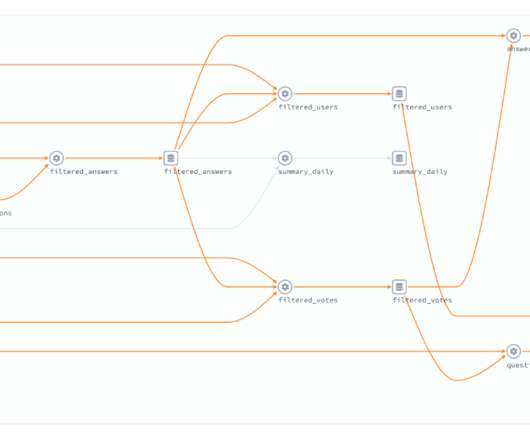
In this way, registration queries are more like regular data definition language (DDL) statements in traditional relational databases. If you consider the clickstream data example from the kafka-examples repository, our event streaming process looks something like this: Figure 1. Managing KSQL dependencies. The KSQL pipeline flow.
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? Without the right tools and frameworks, developers often struggle with inefficient data validation, scalability issues, and managing complex workflows. and pip installed.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your data pipelines. Python is undeniably becoming the de facto language for data practitioners. link] Dani: Apache Iceberg: The Hadoop of the Modern Data Stack?
Organizations face increasing demands for real-time processing and analysis of large volumes of data. Used by more than 75% of the Fortune 500, Apache Kafka has emerged as a powerful open source data streaming platform to meet these challenges. This is where Confluent steps in. This is where Confluent steps in.
I’ll offer my impressions of recent developments in the data engineering space and highlight new ideas from the wider community. Here’s what’s happening in the world of data engineering right now. DataHub 0.8.36 – Metadata management is a big and complicated topic. There are several solutions. version on GitHub.
I’ll offer my impressions of recent developments in the data engineering space and highlight new ideas from the wider community. Here’s what’s happening in the world of data engineering right now. DataHub 0.8.36 – Metadata management is a big and complicated topic. There are several solutions. version on GitHub.
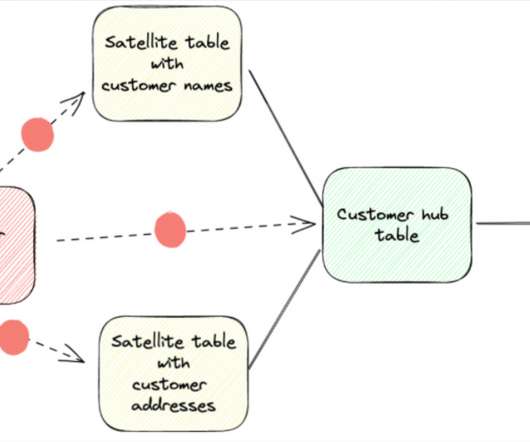
Over the past several years, data warehouses have evolved dramatically, but that doesn’t mean the fundamentals underpinning sound data architecture needs to be thrown out the window. While data vault has many benefits, it is a sophisticated and complex methodology that can present challenges to data quality.
Adopting a cloud data warehouse like Snowflake is an important investment for any organization that wants to get the most value out of their data. When data quality is neglected, data teams end up spending valuable time responding to broken dashboards and unreliable reports. Data can be stale or duplicative.
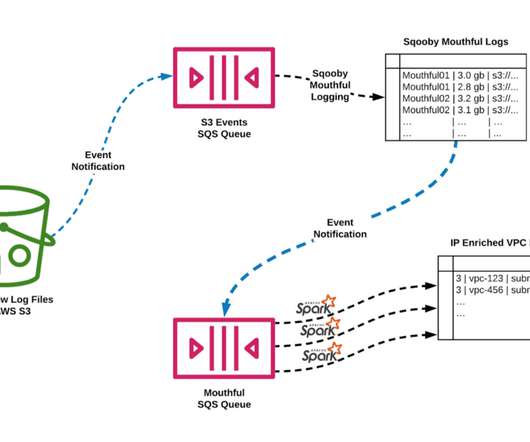
By collecting, accessing and analyzing network data from a variety of sources like VPC Flow Logs, ELB Access Logs, Custom Exporter Agents, etc, we can provide Network Insight to users through multiple data visualization techniques like Lumen , Atlas , etc. At Netflix we publish the Flow Log data to Amazon S3.
It was a fun experience and I think we made a good choice by picking 97 Things Every Data Engineer Should Know. This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams.
Introduction Apache Iceberg has recently grown in popularity because it adds data warehouse-like capabilities to your data lake making it easier to analyze all your data — structured and unstructured. Expiring snapshots is a relatively cheap operation and uses metadata to determine newly unreachable files.
In this blog post, I will explain the underlying technical challenges and share the solution that we helped implement at kaiko.ai , a MedTech startup in Amsterdam that is building a Data Platform to support AI research in hospitals. OpenSlide test data: CMU-1.tiff But as it turns out, we can’t use it.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
With compute-compute separation in the cloud, users can allocate multiple, isolated clusters for ingest compute or query compute while sharing the same real-time data. This enables users to avoid overprovisioning to handle bursty workloads Supporting multiple applications on shared real-time data. How does Rockset solve the problem?
dbt is an amazing way to transform data within a data warehouse. Data lineage is super powerful like that. It is based on a pre-built sample project – a study of the Stack Overflow public data set – but you can apply this approach to a dbt project of your own. . % This view combines data from several tables.
When it comes to partnerships at Monte Carlo, it’s always been our aim to double-down on the technologies we believe will shape the future of the modern data stack. In fact, according to Mordor Intelligence , the data lake market is expected to grow from $3.74 Data observability isn’t just helping customers at the storage layer either.
Goku is our in-house time series database that provides cost efficient and low latency storage for metrics data. GokuS consumes from this second Kafka topic and backs up the data intoS3. From S3, the Goku Shuffler and Compactor create the long term data ready to be ingested byGokuL.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content