This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
They allow the definition of “interfaces for types”, where values of types which conform to that specification can be freely swapped out. reading and writing to a byte stream). classmethod def decode ( cls , data : bytes ) - > Self : # Implementation goes here. traits” in Rust and “concepts” in C++20).
Here is the entire tracer bean definition where I configure the sampler and the reporter for tracing. null) { ProducerRecord<String, byte[]> record = new ProducerRecord<>(topic, bytes); producer.send(record, (RecordMetadata recordMetadata, Exception exception) -> { if (exception !
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. Smarter Pagination We chose payload size in bytes as the limit per response page rather than the number of items because it allows us to provide predictable operation SLOs.
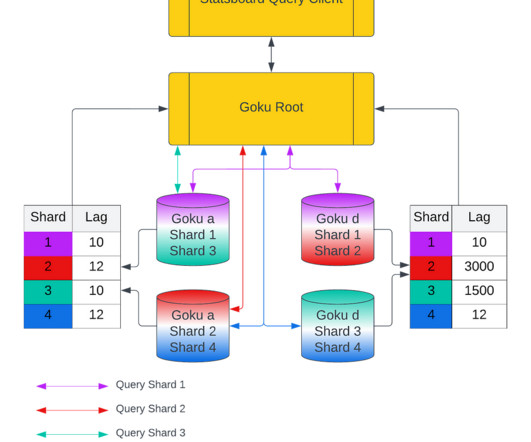
See the graph below, which shows the compaction read and write bytes on a cluster when it is bootstrapping for the first time. Figure 10: compaction read and write bytes showing non zero values as soon as host starts up. This slow bootstrap time was a definite hindrance on our move to less compute heavy instances for cost savings.
In this way, registration queries are more like regular data definition language (DDL) statements in traditional relational databases. ksql> CREATE TABLE clickstream_codes (code int , definition varchar ) with ( key = 'code' , kafka_topic = 'clickstream_codes' , value_format = 'json' ); Message. Table created. 6 objects dropped.
Chart 2: Bytes logged per second via Legacy versus Tulip. We can see that while the number of logging schemas remained roughly the same (or saw some organic growth), the bytes logged saw a significant decrease due to the change in serialization format. Chart 1: Logging schemas using Legacy versus Tulip.
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
It requires the deployment CRN, environment CRN and a JSON definition of the reporting task that we want to create. By using component_name and “Hello World Prometheus,” we’re monitoring the bytes received aggregated by the entire process group and therefore the flow. Select the nifi_amount_bytes_received metric.
quintillion bytes (or 2.5 Two, it creates a commonality of data definitions, concepts, metadata and the like. With the rise in opportunities related to Big Data, challenges are also bound to increase. Below are the 5 major Big Data challenges that enterprises face in 2024: 1. exabytes) of information is being generated every day.
By default, gRPC uses protobuf as its IDL (interface definition language) and data serialization protocol. Our protobuf message definition (.proto link] When the protobuf compiler (protoc) compiles this message definition, it creates the code in the language of your choice (Java in our example). FieldMask is a protobuf message.
This should definitely help bring down the downtime further given that all of the steps for replication, cutting the traffic over to the upgraded DB, and the rollback setup would be handled within their platform. The diff_bytes is 0 now! As of October 2023, AWS now supports blue/green deployment for Aurora Postgres.
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). Seagate Technology forecasts that enterprise data will double from approximately 1 to 2 Petabytes (one Petabyte is 10^15 bytes) between 2020 and 2022.
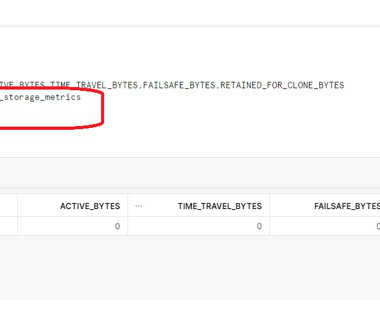
As per the definition: RETAINED_FOR_CLONE_BYTES: Bytes owned by (and billed to) this table that are retained after deletion because they are referenced by one or more clones of this table. Retained For Cloned Bytes So till the time your CLONE table is available you have to pay the storage cost even the original table is dropped.
For alert stream rates low enough such that scientists can visually inspect messages, this format can definitely be appropriate. The predominant existing astronomical alert format uses the semi-structured format XML. For alert rates of millions per night, scientists need a more structured data format for automated analysis pipelines.
jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. We can use our new DECODE() function and enjoy CASE-like functionality: ksql> select definition, decode(definition, 'Proxy authentication required','Bad', 'Page not found','Bad', 'Redirect','Good', 'Unknown') label.
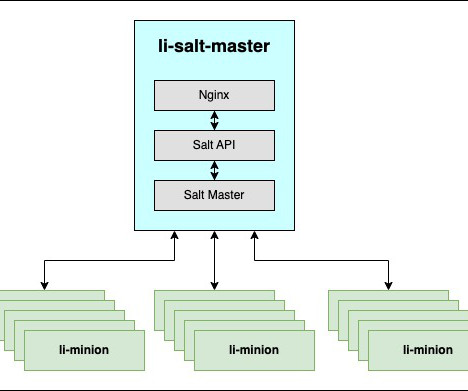
stats, this existing Salt api endpoint is expanded further by adding various new metrics around Salt master & API, Salt Auth QPS / Failures, request per sec, bytes per request, and many more. /login is modified to rely on mTLS at Nginx level. Nginx is used as a reverse proxy and mTLS is enforced via the same.
IValue is always 16 bytes, and does not allocate heap memory for integers, booleans, floating-point numbers, and short strings. Strings We handle character strings and byte strings similarly; the value of tag1 is the only difference. tag0 is usually a subtype, and the meaning of the other two fields changes depending on type.
Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation. A solution is to read the bytes that we need when we need them directly from Blob Storage. open ( "container/file.svs" ) as f : # read the first 256 bytes print ( f.
At the highest level, the definition of the Passport is as follows: message Passport { Header header = 1; UserInfo user_info = 2 ; DeviceInfo device_info = 3 ; Integrity user_integrity = 4 ; Integrity device_integrity = 5 ; } The Header element communicates the name of the service that created the Passport.
When we enabled brotli in a straightforward manner, it reduced bytes sent as expected. In the end, we decided that the brotli treatment was better mainly on the basis of sending 10% fewer bytes over the wire. Does sending fewer bytes actually drive performance? In hindsight, there was a lot of evidence that I was wrong.
We need to know network delay, round trip time, a protocol’s handshake latency, time-to-first-byte and time-to-meaningful-response. One of these metrics is time-to-first-byte. Workload definition language The workload definition language is one of the challenges we’re looking to solve. Think about monads as computation.
They are called Int for 32-bit integers Short for 16-bit integers (rarely used) Byte for 8-bit integers Long for 64-bit integers Char for single characters Boolean for true or false (these are keywords) Float for 32-bit floating-point decimals Double for 64-bit decimals Again, nothing fancy.
Given that definition, event time will never change, but processing time changes constantly for each event as it flows through the pipeline step. Triggering based on data-arriving characteristics such as counts, bytes, data punctuations, pattern matching, etc. Triggering at completion estimates such as watermarks.
One of the biggest complaints about distributed applications is the unpredictability present, due to network errors, asynchronicity and more – these ideas definitely seem like a step in the right direction. Well, Shapeless is mind-bending by definition – you can't really shrug it off that easily.
DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library.
DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library.
Definition : A namespace is a logical collection of a unique set of metric configurations/properties like rollup support, backfilling capability, TTL, etc. To summarize, the folly::IOBuf manage heap allocated byte buffers and buffer related state like size, capacity, and pointer to the next writable byte, etc.
INTEGER : The value is a signed integer, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. REAL : The value is a floating point value, stored as an 8-byte IEEE floating point number. Understanding SQLite Types SQLite only has five data types : NULL : The value is a NULL value.
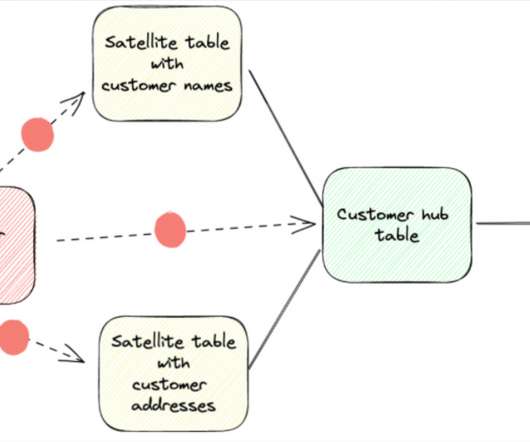
Some challenges can include: Code maintenance The ETL code for Hub, Satellite, and Link tables must follow the same rules for common column value definitions (like business and hash key definitions) to enable them to load independently. This can create data quality challenges if not addressed properly.
Therefore, the initial memory footprint of a virtual thread tends to be very small, a few hundred bytes instead of megabytes. The above is the definition of continuations. They are an alternate implementation of the java.lang.Thread type, which stores the stack frames in the heap (garbage-collected memory) instead of the stack.
However, that is not the complete definition. Data is information in the form of texts, numbers kept on paper or in bits and bytes in the memory of electronic devices or even stored in a human mind. What is Data ? Businesses today are helpless without data. This will be discussed in detail in the subsequent section.
Using compiled languages like C and C++ and interpreted languages like JavaScript and Python, the java code is compiled into byte code to make a class file. So a Java full stack developer skill set would definitely include Kotlin. The class file is interpreted by the JVM for the supporting platform.
quintillion bytes. Yes, Big Data in Machine Learning is definitely worth all the hype. Overall, Big Data is a vast resource that is usable in improving many different aspects of our lives. . There is a $274 billion market for Big Data and Analytics worldwide. Data generated every day amounts to 2.5 billion by 2028.
<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store")); wordCounts.toStream().to("WordsWithCountsTopic", Working on these apache-spark real-time projects will definitely give you better exposure to the big-data ecosystem if you work for an organization that deals with big data or aspire to work for one.
quintillion bytes of data, and the immensity of today’s data has made data engineers more important than ever. It’s Rewarding Making data scientists’ lives easier isn’t the only thing that motivates data engineers. There’s no denying that data engineers are making a significant and growing impact on the world at large. Every day, we create 2.5
A Pipeline class, combines all data marts to define the final definition for data flow, which is then supplied to Ascend SDK’s data flow supplier method for deployment. Remember, the data we manage and the pipelines we build are not just about moving and storing bytes.
For example, if you were measuring absolute table size, you would could trigger an event when: The current total size (bytes or rows) decreases to a specific volume The current total size remains the same for a specific amount of time Numeric distribution tests Is my data within an accepted range?
39 How to Prevent a Data Mutiny Key trends: modular architecture, declarative configuration, automated systems 40 Know the Value per Byte of Your Data Check if you are actually using your data 41 Know Your Latencies key questions: how old is data? If so, find a way to abstract the silos to have one way to access it all. Increase visibility.
Having knowledge of advanced Java concepts for hadoop is a plus but definitely not compulsory to learn hadoop. The choice for using Java for hadoop development was definitely a right decision made by the team with several Java intellects available in the market. Your search for the question “How much Java is required for Hadoop?”
Binary Data types It includes Variable/Fixed binary data types such as maximum length of 8000 bytes. Data Definition Language (DDL): Triggers of this type, as expected, will respond to DDL commands such as DROP, ALTER, and CREATE. Date / Time Data Types Includes DATE, DATETIME (fsp), TIMESTAMP (fsp), TIME (fsp), YEAR.
Web Development vs Programming [Head-to-Head Comparison] Here's a comparison table highlighting the key difference between programming and web development: Parameter Programming Web Development Definition The process of writing, testing, and maintaining computer programs using a programming language.
quintillion bytes. While these two processes are closely related and often done together, they are distinct enough that they deserve separate definitions in most cases: . Data is used not only for storing information but also for many other purposes like processing, analyzing, and then making effective decisions. .
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content