This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
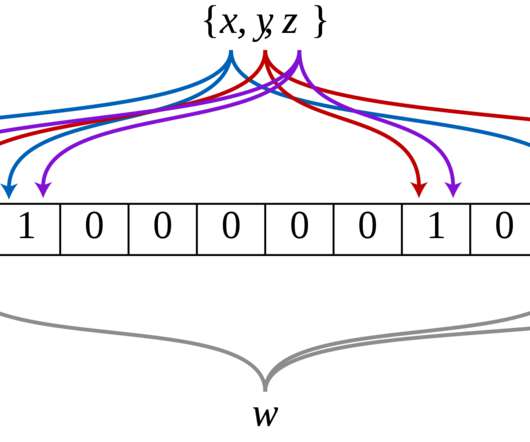
To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized. Drawing an analogy to Byte Pair Encoding (BPE) in NLP, we can think of tokenization as merging adjacent actions to form new, higher-level tokens.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. This model supports both simple and complex data models, balancing flexibility and efficiency.
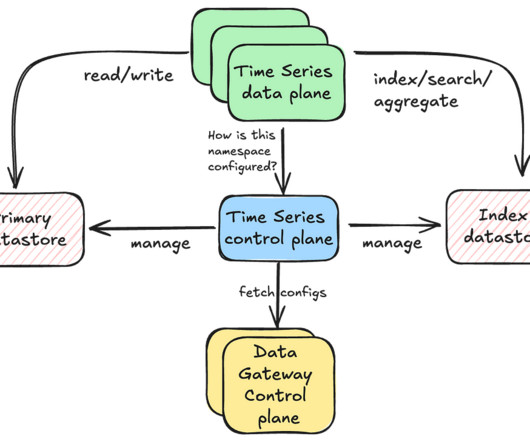
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. Building event streaming applications using KSQL is done with a series of SQL statements, as seen in this example. Introduction. KSQL primer. The KSQL pipeline flow.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Each version contains metadata (keys and values) and a data pointer. You can think of a data pointer as special metadata that points to where the actual data you published is stored. it is meant purely for data versioning and propagation.
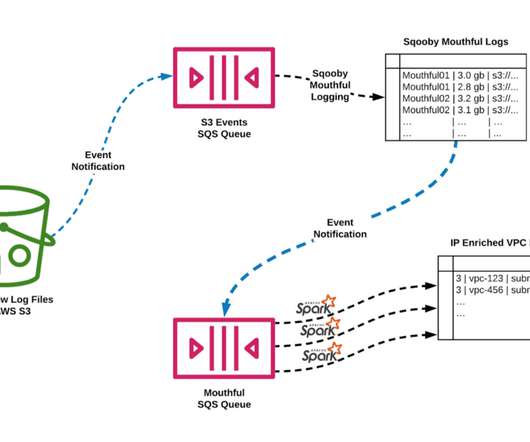
version vpc-id subnet-id instance-id interface-id account-id type srcaddr dstaddr srcport dstport pkt-srcadd r pkt-dstaddr protocol bytes packets start end action tcp-flags log-status 3 vpc-12345678 subnet-012345678 i-07890123456 eni-23456789 123456789010 IPv4 52.213.180.42 These events represent a specific cut of data from the table.
The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation. Lack of Byte String Support : It is difficult to handle binary data efficiently.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
The leader creates a replication stream and sends updates and metadata changes to follower virtual instances. Rockset uses an external strongly-consistent metadata store to perform leader election. Rockset uses an external strongly-consistent metadata store to perform leader election.
controls by domain, byte count, time of day, or IP reputation), but such controls still tend to operate based on identifiers such as a hostname, domain, or IP address. Such telemetry includes process start events, socket connections, and process end events.
If we want to scale out the number of workers handling “web_requests” we can just launch more ECS tasks with the same configuration and respond to Kafka’s rebalance events. yyyy-MM-dd) derived from the ISO 8601 ingestion timestamp of the message Other potential users of Kafka Delta Ingest may have different guidelines on how they use Kafka.
While the tight coupling approach allows the native implementation of Tiered Storage to access Kafka internal protocols and metadata for a highly coordinated design, it also comes with limitations in realizing the full potential of Tiered Storage. File system events indicate to the Segment Uploader when a log segment is finalized (i.e.
Result The scatter plot below shows the AUC (y axis) of the classifier at varying compression levels (x axis = size of the feature store in bytes in logarithmic scale). Feature "freshness", as in how quickly recent events can be reflected to the feature store is very important, as recent events tend to have high informational value.
Run models & capture lineage metadata When working with Datakin (or any other OpenLineage backend) it’s important to generate the dbt docs first. PASS=8 WARN=0 ERROR=0 SKIP=0 TOTAL=8 Emitted 16 openlineage events The models have now run, creating four tables and four views. . % dbt debug Running with dbt=0.21.0 dbt version: 0.21.0
It allows the addition of metadata to the changes, which facilitates team members in pinpointing the changes introduced in the code, why it was made, and when and who made it. Using compiled languages like C and C++ and interpreted languages like JavaScript and Python, the java code is compiled into byte code to make a class file.
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. To define the columns, PySpark offers the pyspark.sql.types import StructField class, which has the column name (String), column type (DataType), nullable column (Boolean), and metadata (MetaData).
Easily Available- Snowflake Architecture is designed to be fully distributed, covering multiple zones and regions, and is highly fault-tolerant in the event of hardware failure. This layer stores the metadata needed to optimize a query or filter data. BigQuery charges users depending on how many bytes are read or scanned.
RocksDB-Cloud replicates all the data and metadata for a RocksDB instance to S3. The write ahead log is used to recover data in the memtables in the event of process restart. We limit the number of bytes that can be written per second to all RocksDB instances assigned to a leaf node. RocksDB cannot recover from machine failures.
It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. In S3, data consists of the following components – key (name), value (data), version ID, metadata and access control lists. Data objects are stored redundantly across multiple devices in several locations.
tesla-integration" You’ll notice in the results that not only will you see the lat and long you sent to the Kafka topic but some metadata that Rockset has added too including an ID, a timestamp and some Kafka metadata, this can be seen in Fig 2. select * from commons."tesla-integration" According to Postman that returned in 0.2
Avro files store metadata with data and also let you specify independent schema for reading the files. If the primary NameNode goes down, the standby will take its place using the most recent metadata that it has. There is a pool of metadata which is shared by all the NameNodes. RowKey is internally regarded as a byte array.
As it serves the request, the web server writes a line to a log file on the filesystem that contains some metadata about the client and the request. body_bytes_sent — the number of bytes sent by the server to the client in the response body. 200 30294 "[link] "Mozilla/5.0 (X11; PingdomPageSpeed/1.0 200 95786 "[link] "Mozilla/5.0 (X11;
In the event of a failure in the leader, the data is not lost because of the presence of replicas in other servers. Message Broker: Kafka is capable of appropriate metadata handling, i.e., a large volume of similar types of messages or data, due to its high throughput value. Mention some real-world use cases of Apache Kaka.
Log files are records of events occurring inside a system that operate as a record of system activity. These records could have a lot of material, including: Timestamp: The exact time at which an event occurred. Event Information: Descriptions of actions or events, such as transactions, errors, or intrusions.
hey ( credits ) 🥹It's been a long time since I've put words down on paper or hit the keyboard to send bytes across the network. Forward data conference ⏩ I'm excited to announce that I am co-organising the Forward Data Conference , a one-day event in Paris. Looks neat.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content