This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Riccardo is a proud alumnus of Rock the JVM, now a senior engineer working on critical systems written in Java, Scala and Kotlin. Version 19 of Java came at the end of 2022, bringing us a lot of exciting stuff. First, we need to use a version of Java that is at least 19. Another tour de force by Riccardo Cardin.
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Before I discuss how Kafka can make a Jaeger tracing solution in a distributed system more robust, I’d like to start by providing some context.
Java, as the language of digital technology, is one of the most popular and robust of all software programming languages. Java, like Python or JavaScript, is a coding language that is highly in demand. Java, like Python or JavaScript, is a coding language that is highly in demand. Who is a Java Full Stack Developer?
This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how data management systems are designed. An introduction to Velox Velox is the first project in our composable data management system program.
Java-enabled general-purpose computers, mobile devices, and other handheld gadgets are a part of everyone’s daily life now. As a result, we can see that Java is one of the most widely used programming languages today. Therefore, our Java for beginners tutorial is here to educate the audience en masse. . Advantages of Java .
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. The schemas are also useful for generating specific Java classes. The bank application.
Bytes, Decimals, Numerics and oh my. Standard locations for this folder are: Confluent CLI: share/java/kafka-connect-jdbc/ relative to the folder where you downloaded Confluent Platform. Docker, DEB/RPM installs: /usr/share/java/kafka-connect-jdbc/. For example: CLASSPATH=/u01/jdbc-drivers/mysql-connector-java-8.0.13.jar./bin/connect-distributed./etc/kafka/connect-distributed.properties.
HOTP scala implementation HOTP generation is quite tedious, therefore for simplicity, we will use a java library, otp-java by Bastiaan Jansen. TOTP scala implementation Otp-java also provides an implementation for TOTP token generation: import java.time.Duration val secret = SecretGenerator. val ZxingVersion = "3.5.1"
Meta is introducing Velox, an open source unified execution engine aimed at accelerating data management systems and streamlining their development. Experimental results from our paper published at the International Conference on Very Large Data Bases (VLDB) 2022 show how Velox improves efficiency and consistency in data management systems.
For most professionals who are from various backgrounds like - Java, PHP,net, mainframes, data warehousing, DBAs, data analytics - and want to get into a career in Hadoop and Big Data, this is the first question they ask themselves and their peers. Your search for the question “How much Java is required for Hadoop?”
In this document, the option of “Installing KTS as a service inside the cluster” is chosen since additional nodes to create a dedicated cluster of KTS servers is not available in our demo system. yum install rng-tools # For Centos/RHEL 6, 7+ systems. apt-get install rng-tools # For Debian systems. For Centos/RHEL 7+ systems.
Hiring managers agree that “Java is one of the most in-demand and essential skill for Hadoop jobs. But how do you get one of those hot java hadoop jobs ? You have to ace those pesky java hadoop job interviews artfully. To demonstrate your java and hadoop skills at an interview, preparation is vital.
We used Groovy instead of Java to write our UDFs, so we’ve applied the groovy plugin. The Groovy compiler accepts Java as well as Groovy, and Gradle automatically adds the java plugin with the groovy plugin and compiles all Java and Groovy code together into the same JAR. jar Archive: functions/build/libs/functions-1.0.0.jar
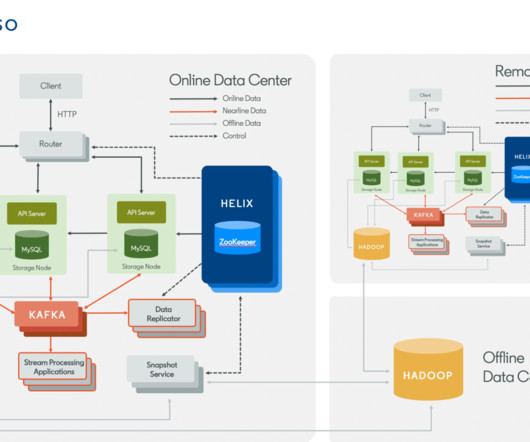
In this post, we will explain how we solved these challenges and improved system performance. Espresso System Overview Figure 1 is a high-level overview of the Espresso ecosystem, which includes the online operation section of Espresso (the main focus of this blog post). This delay can significantly affect the system's response time.
quintillion bytes of data are created every single day, and it’s only going to grow from there. To store and process even only a fraction of this amount of data, we need Big Data frameworks as traditional Databases would not be able to store so much data nor traditional processing systems would be able to process this data quickly.
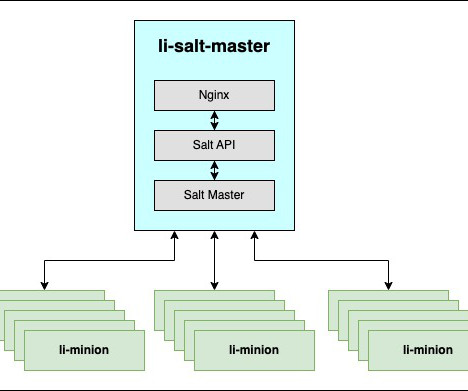
Minion (an agent on host) sees jobs and results by subscribing to events published on the event bus by master service, It uses ZMQ (ZeroMQ) to achieve high-speed, asynchronous communication between connected systems. java or go lang, simple curl examples are documented. Targeted minions execute the job on the host and return to master.
Pinterest metrics system Goku-Ingestor has been running and evolving for close to a decade. Reliability Issues In the initial months of 2023, certain problems arose as a result of Goku-Ingestor’s performance, leading to some instances where data loss occurred within the metrics system for a brief duration of time.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Dataset propagation At Netflix we use an in-house dataset pub/sub system called Gutenberg. An important point to note is that Gutenberg is not designed as an eventing system?—?it system behavior. for example to train machine-learned models.
For the JDK, we’ll do great with a long-term support Java version. Scala or Java), this naming convention is probably second nature to you. Types are the same as regular Java types but capitalized. The closest analogous expression in the C family (including Java) would be the ternary aCondition ?
The whole system was quite complex, and starting to become brittle. The API server orchestrates backend systems to authenticate the user. Upstream systems had to reopen the tokens to identify the user logging in and potentially manage multiple parallel identity data structures, which could easily get out of sync.
Snowpark’s key benefit is its ability to support coding in languages other than SQL—such as Scala, Java, and Python—without moving data out of Snowflake and, therefore , take full advantage of its powerful capabilities through code. This paves the way for new interactions and capabilities.
The processing system must also be simple and flexible to adapt to the business’s complexity. They also require a system that can handle global-scale data since the Internet allows companies to reach more customers than ever. Usually, the system uses time notions to organize data into the window (e.g.,
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? For example, Amazon Redshift can load static data to Spark and process it before sending it to downstream systems.
I find there is a lot of good work making the Java Virtual Machine very efficient and very fast, utilizing the underlying infrastructure well. I liked Java. It was a simple enough service, accepting bytes from the customer device (using a REST API) and writing them to disk. Unfortunately, we couldn't scale up.
As technology has become more integrated into our lives, so have the skill sets required to help create and maintain these systems. Programming languages such as Python, Ruby, and Java are used to write code that can be executed by a computer. Server-side languages such as PHP, Python, Ruby, and Java may also be used.
If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub! Pulsar Manager 0.3.0 – Lots of enterprise systems lack a nice management interface. This means that the Impala authors had to go above and beyond to integrate it with different Java/Python-oriented systems.
If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub! Pulsar Manager 0.3.0 – Lots of enterprise systems lack a nice management interface. This means that the Impala authors had to go above and beyond to integrate it with different Java/Python-oriented systems.
In the main concepts and features of Java, strings are one of the possible data structures used to describe a series of characters - usually contiguous - in memory locations. Java: Java uses the `String` class to declare and manipulate strings. Strings in Java are objects. What is String Data Structure?
Such libraries use the advanced type system of the Scala language (and/or some macro magic for some specific information not provided by types alone) to generate code and compile-time that otherwise would have to be written by hand or by using reflection – and no-one wants to write those JsObjects by hand.
These skilled professionals play a vital role in developing intelligent systems that can decipher and interpret human communication like never before. LPA Pune Light Information Systems 7.4 LPA Pune Light Information Systems 7.4 NLP engineers make systems and tools that can comprehend human language. LPA Cosmic Strands 3.5
How to manage huge data - Servers With Internet Of Things in boom, Information is overflowing with a huge amount of data; handling tremendous data needs more system resources which means more Dedicated server s are needed. High latency as all the VMs have to pass through the OS layer to access the system resources.
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. Build an Awesome Job Winning Data Engineering Projects Portfoli o Technical Skills Required to Become a Big Data Engineer Database Systems: Data is the primary asset handled, processed, and managed by a Big Data Engineer.
quintillion bytes of data today, and unless that data is organized properly, it is useless. APACHE Hadoop Big data is being processed and stored using this Java-based open-source platform, and data can be processed efficiently and in parallel thanks to the cluster system. A global data explosion is generating almost 2.5
Moreover, developers frequently prefer dynamic programming languages, so interacting with the strict type system of SQL is a barrier. We'll walk you through our motivations, a few examples, and some interesting technical challenges that we discovered while building our system. Contrast with Java and C, which are statically typed.
What is Apache Spark - The User-Friendly Face of Hadoop Spark is a fast cluster computing system developed by the contributions of nearly 250 developers from 50 companies in UC Berkeley's AMP Lab to make data analytics more rapid and easier to write and run. Hadoop MapReduce - Why spark is faster than Mapreduce?
Partitioning in memory (DataFrame) and partitioning on disc (File system) are both supported by PySpark. The data is stored in HDFS (Hadoop Distributed File System), which takes a long time to retrieve. All worker nodes must copy the files, or a separate network-mounted file-sharing system must be installed.
Apache Kafka and Flume are distributed data systems, but there is a certain difference between Kafka and Flume in terms of features, scalability, etc. To run Kafka, remember that your local environment must have Java 8+ installed on it. Mention some of the system tools available in Apache Kafka. config/server.properties 25.
RDBMS is a part of system software used to create and manage databases based on the relational model. FSCK stands for File System Check, used by HDFS. FSCK generates a summary report that covers the file system's overall health. Reliability: The entire system does not collapse if a single node or a few systems fail.
Snowflake provides data warehousing, processing, and analytical solutions that are significantly quicker, simpler to use, and more adaptable than traditional systems. Snowflake is not based on existing database systems or big data software platforms like Hadoop. Snowflake is a data warehousing platform that runs on the cloud.
HBase system consists of tables with rows and columns just like a traditional RDBMS. Partition Tolerance – System continues to work even if there is failure of part of the system or intermittent message loss. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
The key can be a fixed-length sequence of bits or bytes. Although it is an outdated standard, it is still used in legacy systems and for accomplishing image encryption project work. Jsteg JSteg is an open-source Java-based tool for steganography and encryption. Key Generation: A secret encryption key is generated.
Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. The certification gives you the technical know-how to work with cloud computing systems. Expertise in creating scalable and efficient data processing architectures and also, monitor data processing systems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content