This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Distributed tracing with Apache Kafka and Jaeger. Example of a Kafka project with Jaeger tracing. What does this all mean?
If you've used Kafka Streams, Kafka clients, or Schema Registry, you’ve probably felt the frustration of unknown magic bytes. Here are a few ways to fix the issue.
One of the most common integrations that people want to do with Apache Kafka ® is getting data in from a database. The existing data in a database, and any changes to that data, can be streamed into a Kafka topic. Here, I’m going to dig into one of the options available—the JDBC connector for Kafka Connect. Introduction.
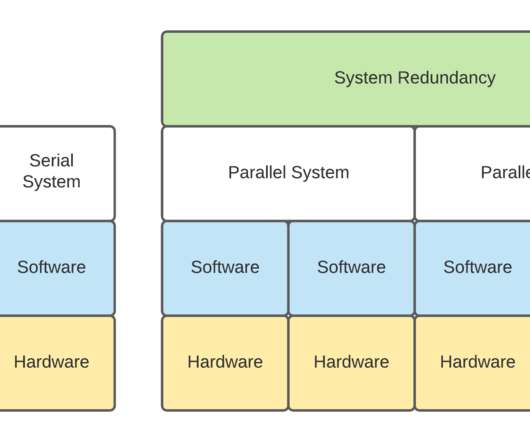
There are many ways that Apache Kafka has been deployed in the field. In our Kafka Summit 2021 presentation, we took a brief overview of many different configurations that have been observed to date. Kafka as software falls more cleanly into the Parallel Systems Reliability discussed below but some parts of it can end up Serial.
Put another way, courtesy of Spencer Ruport: LISTENERS are what interfaces Kafka binds to. Apache Kafka ® is a distributed system. You need to tell Kafka how the brokers can reach each other but also make sure that external clients (producers/consumers) can reach the broker they need to reach. Is anyone listening? on AWS, etc.)
This data pipeline is a great example of a use case for Apache Kafka ®. The case for Apache Kafka. After researching formats—and reading about Confluent’s suggestion of using Avro with Kafka —we settled on using Avro, an open source, JSON-based binary format, for serializing the data in the alert messages.
We’ll also take a look at some performance tests to see if Rust might be a viable alternative for Java applications using Apache Kafka ®. In this case, that means a command is created for a particular action, which will be assigned to a Kafka topic specific for that action. On May 15, 2015, the Core Kafka team released version 1.0
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, Kafka Streams topology generation 101.
As discussed in part 2, I created a GitHub repository with Docker Compose functionality for starting a Kafka and Confluent Platform environment, as well as the code samples mentioned below. jar Zip file size: 5849 bytes, number of entries: 5. jar Zip file size: 11405084 bytes, number of entries: 7422. Kafka Streams.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. gradlew composeUp. The KSQL pipeline flow.
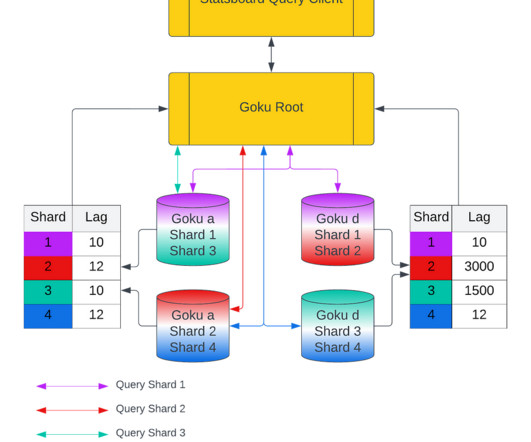
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
In this post I will demonstrate how Kafka Connect is integrated in the Cloudera Data Platform (CDP), allowing users to manage and monitor their connectors in Streams Messaging Manager while also touching on security features such as role-based access control and sensitive information handling. Kafka Connect. Streams Messaging Manager.
We can persist this to a new KSQL stream, which populates an Apache Kafka ® topic: ksql> CREATE STREAM PRODUCTS_ENRICHED AS. KSQL now has the ability to log details of processing errors to a destination such as another Kafka topic, from where they can be inspected. SELECT SKU, CASE WHEN SKU LIKE 'H%' THEN 'Homewares'.
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. To serve this need, we created kafka-delta-ingest.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
Today, nearly everyone uses standard data formats like Avro, JSON, and Protobuf to define how they will communicate information between services within an organization, either synchronously through RPC calls or asynchronously through Apache Kafka ® messages. To allow Schema Validation on write, Confluent Server must be schema aware.
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka. This led us to use a number of observability tools, including VPC flow logs , ebpf agent metrics , and Envoy networking bytes metrics to rectify the situation.
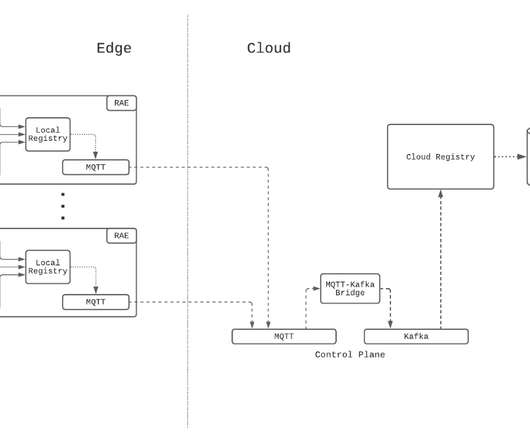
Since Kafka is a supported messaging platform at Netflix, a bridge is established between the two protocols to allow cloud-side services to communicate with the control plane. Through the bridge, MQTT messages are converted directly to Kafka records, where the record key is set to be the MQTT topic that the message was assigned to.
When there is a full GC, it leads to full halt to the data processing pipeline and causes both back-pressure for upstream kafka clusters and cascading failure for downstream TSDB. Pyoung = Seden / Ralloc where Pyoung is the period between young GC, Seden is the size of Eden and Ralloc is the rate of memory allocations (bytes per second).
When people ask me the very top-level question “why do people use Kafka,” I usually lead with the story in my last post , where I talked about how Apache Kafka ® is helping us deliver on the promises the cloud made to us a decade ago. Industry heavyweights like Capital One use event streaming on Kafka for this very task.
[link] Sophie Blee-Goldman: Kafka Streams and Rebalancing through the Ages Consumers come and go. Kafka rebalancing has come a long way since then, and the author walks back to us the memory lane of Kafka rebalancing and the advancements made ever since. Partitions, ever-present. Rebalancing, the awkward middle child.
We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. sk) { return 0; } u64 key = (u64)sk; struct source *src; src = bpf_map_lookup_elem(&socks, &key); When capturing the connection close event, we include how many bytes were sent and received over the connection.
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
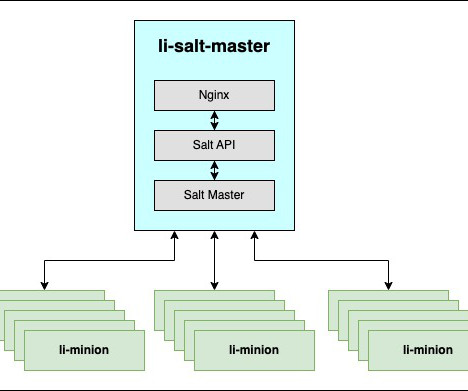
stats, this existing Salt api endpoint is expanded further by adding various new metrics around Salt master & API, Salt Auth QPS / Failures, request per sec, bytes per request, and many more. Beside all of Salt application & system metrics, all of the Master/API logs are streamed via Apache Kafka to Azure Data Explorer.
Used by more than 75% of the Fortune 500, Apache Kafka has emerged as a powerful open source data streaming platform to meet these challenges. But harnessing and integrating Kafka’s full potential into enterprise environments can be complex. This is where Confluent steps in.
RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. Of course, the main topic is data streaming.
RocksDB is a storage engine with a key/value interface, where keys and values are arbitrary byte streams written as a C++ library. Kafka: Mark KRaft as Production Ready – One of the most interesting changes to Kafka from recent years is that it now works without ZooKeeper. Of course, the main topic is data streaming.
I walk through an end to end integration of requesting data from the car, streaming it into a Kafka Topic and using Rockset to expose the data via its API to create real time visualisations in D3. Getting started with Kafka When starting with any new tool I find it best to look around and see the art of the possible.
Apache Spark Streaming Use Cases Spark Streaming Architecture: Discretized Streams Spark Streaming Example in Java Spark Streaming vs. Structured Streaming Spark Streaming Structured Streaming What is Kafka Streaming? Kafka Stream vs. Spark Streaming What is Spark streaming? What is Kafka Streaming?
Gokus ingestor component consumes from this Kafka topic and then produces into another kafka topic (partition corresponds to GokuSshard). GokuS consumes from this second Kafka topic and backs up the data intoS3. The GokuS cluster consumes data points from all the kafka topics (i.e. from every namespace).
The ML for large-scale production systems highlights the improvement made from the existing heuristic in the YouTube cache replacement algorithm with a new hybrid algorithm that combines a simple heuristic with a learned model, improving the byte miss ratio at the peak by ~9%. Streaming plus batch unified in a single platform.
I remember back in the day when you had to set up your clusters and run Hadoop and Kafka clusters on top, it was quite expensive. In the past, DBAs had to understand how many bytes a column was, because they would use that to calculate out how much space they would use within two years. Doing the pre-work is important.
39 How to Prevent a Data Mutiny Key trends: modular architecture, declarative configuration, automated systems 40 Know the Value per Byte of Your Data Check if you are actually using your data 41 Know Your Latencies key questions: how old is data? 55 Pipe Dreams Kafka was good because it had replaying of messages. Increase visibility.
I have found that thinking of data as a story over time helps to give life to these bytes of data. These events are emitted (written) directly to an event stream processing service, like Apache Kafka, which under normal circumstances enables listeners (consumers) to immediately use that event once it is written.
quintillion bytes of data, and the immensity of today’s data has made data engineers more important than ever. It’s Rewarding Making data scientists’ lives easier isn’t the only thing that motivates data engineers. There’s no denying that data engineers are making a significant and growing impact on the world at large. Every day, we create 2.5
Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day. Hadoop , Kafka , and Spark are the most popular big data tools used in the industry today. Most of these are performed by Data Engineers. Your experience in previous organizations will help develop and enhance these skills.
Recommended Reading: 100 Kafka Interview Questions and Answers 20 linear regression interview questions and answers Top 50 NLP Interview Questions and Answers Top 20 Logistic Regression Interview Questions and Answers How can you create a deep copy of the complete java object along with its state?
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
New input formats: Currently, the platform is supporting byte-based input. As we move to support use cases in which configs are updated dynamically based on order type or through ML models, however, we need better methods for storing those requests. Having separate endpoints for them will keep the blast radius limited and isolated.
Exabytes are 10006 bytes, so to put it into perspective, 463 exabytes is the same as 212,765,957 DVDs. You can practice developing Spark applications that integrate with CDP components like Hive and Kafka through hands-on practice. Why Are Data Engineering Skills In Demand?
For input streams receiving data through networks such as Kafka, Flume, and others, the default persistence level setting is configured to achieve data replication on two nodes to achieve fault tolerance. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects.
RowKey is internally regarded as a byte array. It is not possible to use Apache Kafka without Zookeeper because if the Zookeeper is down Kafka cannot serve client request. 4) Explain about ZooKeeper in Kafka Apache Kafka uses ZooKeeper to be a highly distributed and scalable system.
Franz Kafka, 1897. Load balancing and scheduling are at the heart of every distributed system, and Apache Kafka ® is no different. Kafka clients—specifically the Kafka consumer, Kafka Connect, and Kafka Streams, which are the focus in this post—have used a sophisticated, paradigmatic way of balancing resources since the very beginning.
Logs-As-A-Stream Many messaging platforms, such as Kafka, Pulsar, and/or RabbitMQ have what they advertise as Stream s. If we’re in the mindset of Kafka, a stream might mean the implication of consistent data within an offset at all times. class RealFakeInputStream [ T T ) extends InputStream { val data : Array [ Byte ] = "0123456789".
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content