This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! What are topics in Apache Kafka? A stream of messages that belong to a particular category is called a topic in Kafka.
link] Gunnar Morling: What If We Could Rebuild Kafka From Scratch? KIP-1150 ("Diskless Kafka") is one of my most anticipated releases from Apache Kafka. link] Yuval Yogev: Making Sense of Apache Iceberg Statistics A rich metadata model is vital to improve query efficiency. and Lite 2.0)
Put another way, courtesy of Spencer Ruport: LISTENERS are what interfaces Kafka binds to. Apache Kafka ® is a distributed system. When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. Is anyone listening? Brokers in the cloud (e.g.,
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. This results in a fast and scalable metadata handling system.
For input streams receiving data through networks such as Kafka , Flume, and others, the default persistence level setting is configured to achieve data replication on two nodes to achieve fault tolerance. MEMORY ONLY SER: The RDD is stored as One Byte per partition serialized Java Objects.
With the release of Apache Kafka ® 2.1.0, Kafka Streams introduced the processor topology optimization framework at the Kafka Streams DSL layer. In what follows, we provide some context around how a processor topology was generated inside Kafka Streams before 2.1, Kafka Streams topology generation 101.
In part 1 , we discussed an event streaming architecture that we implemented for a customer using Apache Kafka ® , KSQL from Confluent, and Kafka Streams. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices. gradlew composeUp. The KSQL pipeline flow.
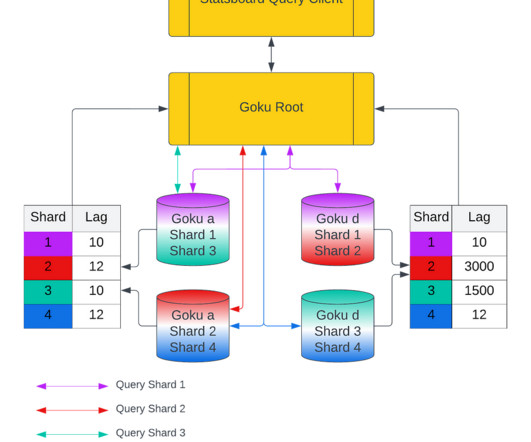
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
Jeff Xiang | Senior Software Engineer, Logging Platform; Vahid Hashemian | Staff Software Engineer, LoggingPlatform When it comes to PubSub solutions, few have achieved higher degrees of ubiquity, community support, and adoption than Apache Kafka, which has become the industry standard for data transportation at large scale.
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. To serve this need, we created kafka-delta-ingest.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
Used by more than 75% of the Fortune 500, Apache Kafka has emerged as a powerful open source data streaming platform to meet these challenges. But harnessing and integrating Kafka’s full potential into enterprise environments can be complex. This is where Confluent steps in.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! How to study for Kafka interview? What is Kafka used for? What are main APIs of Kafka?
I walk through an end to end integration of requesting data from the car, streaming it into a Kafka Topic and using Rockset to expose the data via its API to create real time visualisations in D3. Getting started with Kafka When starting with any new tool I find it best to look around and see the art of the possible.
Gokus ingestor component consumes from this Kafka topic and then produces into another kafka topic (partition corresponds to GokuSshard). GokuS consumes from this second Kafka topic and backs up the data intoS3. The GokuS cluster consumes data points from all the kafka topics (i.e. from every namespace).
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
DoorDash’s internal platform team already has built many features which come in handy, like an Asgard-based microservice, which comes with a good set of built-in features like request-metadata, logging, and dynamic-value framework integration. New input formats: Currently, the platform is supporting byte-based input.
Avro files store metadata with data and also let you specify independent schema for reading the files. If the primary NameNode goes down, the standby will take its place using the most recent metadata that it has. There is a pool of metadata which is shared by all the NameNodes. RowKey is internally regarded as a byte array.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. To define the columns, PySpark offers the pyspark.sql.types import StructField class, which has the column name (String), column type (DataType), nullable column (Boolean), and metadata (MetaData).
Avro files store metadata with data and also let you specify independent schema for reading the files. If the primary NameNode goes down, the standby will take its place using the most recent metadata that it has. There is a pool of metadata which is shared by all the NameNodes. RowKey is internally regarded as a byte array.
For a more concrete example, we are going to write a program that will parse markdown files, extract words identified as tags, and then regenerate those files with tag-related metadata injected back into them. Logs-As-A-Stream Many messaging platforms, such as Kafka, Pulsar, and/or RabbitMQ have what they advertise as Stream s.
Kafka Connect is part of Apache Kafka ® and is a powerful framework for building streaming pipelines between Kafka and other technologies. Since Apache Kafka 2.0, This is the default behavior of Kafka Connect, and it can be set explicitly with the following: errors.tolerance = none. jq -c -M '[.name,tasks[].state]'
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content