This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Drawing an analogy to Byte Pair Encoding (BPE) in NLP, we can think of tokenization as merging adjacent actions to form new, higher-level tokens. For example, new title embeddings can be initialized by adding slight random noise to existing average embeddings or by using a weighted combination of similar titles embeddings based on metadata.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. Chunked data can be written by staging chunks and then committing them with appropriate metadata (e.g. This model supports both simple and complex data models, balancing flexibility and efficiency.
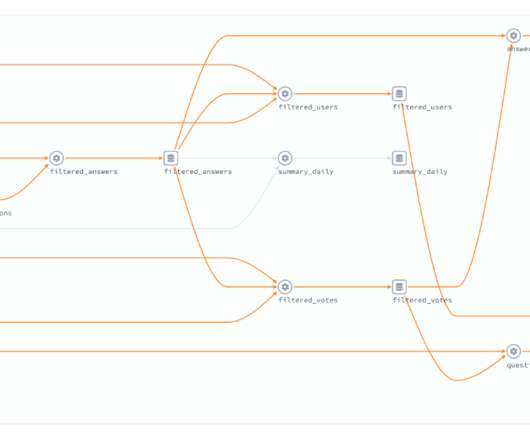
An Avro file is formatted with the following bytes: Figure 1: Avro file and data block byte layout The Avro file consists of four “magic” bytes, file metadata (including a schema, which all objects in this file must conform to), a 16-byte file-specific sync marker, and a sequence of data blocks separated by the file’s sync marker.
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
The inspection stage examines the input media for compliance with Netflix’s delivery specifications and generates rich metadata. The index file keeps track of the physical location (URL) of each chunk and also keeps track of the physical location (URL + byte offset + size) of each video frame to facilitate downstream processing.
In the new representation , the first four bytes of the view object always contain the string size. Otherwise, a prefix of the string is stored in the next four bytes, followed by the buffer ID (StringViews can contain multiple data buffers) and the offset in that data buffer. first writing StringView at position 2, then 0 and 1).
The bucket in itself is actually nothing but a collection of SST files holding all the time series data and metadata for the corresponding bucket size. See the graph below, which shows the compaction read and write bytes on a cluster when it is bootstrapping for the first time. The bucket id is unix time divided by bucket size.
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Further, since the HEIF format borrows learnings from next-generation video compression, the format allows for preserving metadata such as color gamut and high dynamic range (HDR) information.
This file includes: Metadata ?—?This That is, all mounted files that were opened and every single byte range read that MezzFS received. Finally, MezzFS will record various statistics about the mount, including: total bytes downloaded, total bytes read, total time spent reading, etc. File operations ?—?All Actions ?—?MezzFS
When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. The key thing is that when you run a client, the broker you pass to it is just where it’s going to go and get the metadata about brokers in the cluster from. The default is 0.0.0.0,
quintillion bytes (or 2.5 Two, it creates a commonality of data definitions, concepts, metadata and the like. With the rise in opportunities related to Big Data, challenges are also bound to increase. Below are the 5 major Big Data challenges that enterprises face in 2024: 1. exabytes) of information is being generated every day.
Cost Efficiency : Reducing the cost per byte and per operation to optimize long-term retention while minimizing infrastructure expenses, which can amount to millions of dollars for Netflix. Metadata table : This table stores information about how each time slice is configured per namespace.
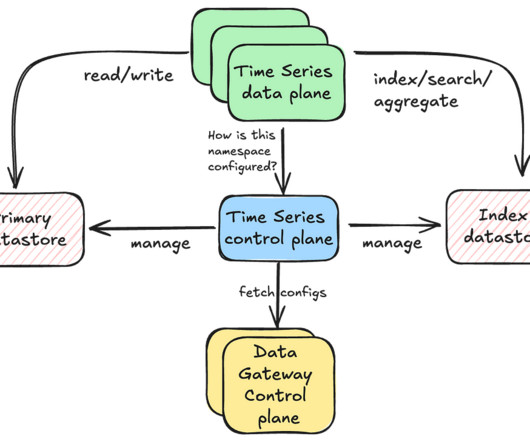
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. The major pieces, as shown in Fig.
One key part of the fault injection service is a very lightweight passthrough fuse file system that is used by Ozone for storing all its persistent data and metadata. The APIs are generic enough that we could target both Ozone data and metadata for failure/corruption/delays. NetFilter Extension.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Each version contains metadata (keys and values) and a data pointer. You can think of a data pointer as special metadata that points to where the actual data you published is stored. Direct data pointers are automatically replicated globally.
Half of all services required for streaming video use our Hollow library for on-heap metadata. We paid particular attention to deallocation of direct byte buffers, but we haven’t seen any impact thus far. In the worst case we evaluated, non-generational ZGC caused 36% more CPU utilization than G1 for the same workload.
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. sent 11,286 bytes received 172 bytes 2,546.22 keytrustee ccycloud-3.cdpvcb.root.hwx.site:/var/lib/keytrustee/.
A bloated metadata.json file could increase both read/write times because a large metadata file needs to be read/written every time. Regularly expiring snapshots is recommended to delete data files that are no longer needed, and to keep the size of table metadata small.
Customize the Replication Script: Use the scripting language provided by Precisely to define variables, specify metadata replication preferences, and map Cobol copybook descriptions for VSAM files.
The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation. Lack of Byte String Support : It is difficult to handle binary data efficiently.
This query will fetch a list of all tables within a database, along with helpful metadata about their settings. Use this query to extract table schema , then use this query to extract view and external table metadata. Use this query to pull how many bytes and rows tables have , as well as the time they were most recently updated.
Whether displaying it on a screen or feeding it to a neural network, it is fundamental to have a tool to turn the stored bytes into a meaningful representation. A solution is to read the bytes that we need when we need them directly from Blob Storage. open ( "container/file.svs" ) as f : # read the first 256 bytes print ( f.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
The leader creates a replication stream and sends updates and metadata changes to follower virtual instances. Rockset uses an external strongly-consistent metadata store to perform leader election. Rockset uses an external strongly-consistent metadata store to perform leader election.
architecture (with some minor deviations) to achieve their data integration objectives around scalability and use of metadata. “A The other advantage is because we follow a standard design, we are able to generate a lot of our code using code templates and metadata. Presentation Layer – Reporting layer for the vast majority of users.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
Unity Catalog As the name implies, the unity catalog brings unity to individual metastores and catalogs and serves as a central metadata repository for Databricks users. The Unity Catalog unifies metastores, catalogs, and metadata within Databricks. The Unity Catalog unifies metastores, catalogs, and metadata within Databricks.
yyyy-MM-dd) derived from the ISO 8601 ingestion timestamp of the message Other potential users of Kafka Delta Ingest may have different guidelines on how they use Kafka. yyyy-MM-dd) derived from the ISO 8601 ingestion timestamp of the message Other potential users of Kafka Delta Ingest may have different guidelines on how they use Kafka.
DoorDash’s internal platform team already has built many features which come in handy, like an Asgard-based microservice, which comes with a good set of built-in features like request-metadata, logging, and dynamic-value framework integration. New input formats: Currently, the platform is supporting byte-based input.
While the tight coupling approach allows the native implementation of Tiered Storage to access Kafka internal protocols and metadata for a highly coordinated design, it also comes with limitations in realizing the full potential of Tiered Storage. Decoupling from theBroker The native Tiered Storage offering in Apache Kafka 3.6.0+
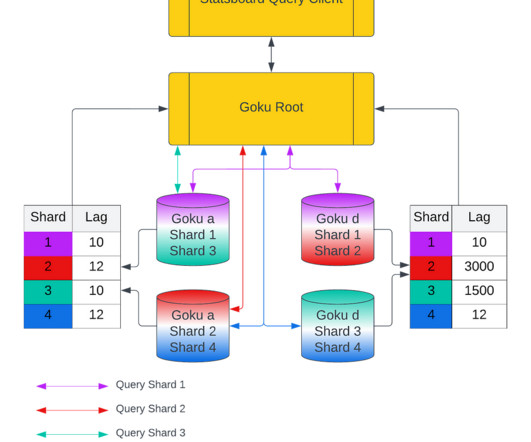
Indexing Improvements for Metric Name(GokuS) A time series metadata or key consists of the following Multiple hosts can emit time series for a unique metric name (e.g. To summarize, the folly::IOBuf manage heap allocated byte buffers and buffer related state like size, capacity, and pointer to the next writable byte, etc.
Here’s how to do that with Snowflake: This query will fetch a list of all tables along with helpful metadata about their settings. Since data can break literally anywhere in your pipeline, you will need a way to pull metrics and metadata from not just your warehouse, but other assets too.
Run models & capture lineage metadata When working with Datakin (or any other OpenLineage backend) it’s important to generate the dbt docs first. Our schema has changed, and we want Datakin to have the latest metadata about tables and columns. % . % dbt debug Running with dbt=0.21.0 dbt version: 0.21.0 python version: 3.9.7
controls by domain, byte count, time of day, or IP reputation), but such controls still tend to operate based on identifiers such as a hostname, domain, or IP address. Some networking solutions build out their feature set with controls that go beyond basic port / IP ingress & egress (e.g.,
It allows the addition of metadata to the changes, which facilitates team members in pinpointing the changes introduced in the code, why it was made, and when and who made it. Using compiled languages like C and C++ and interpreted languages like JavaScript and Python, the java code is compiled into byte code to make a class file.
For this specific case, when the StreamBuilder#build() method is called, Streams will “push up” the repartitioning phase of the logical plan based on the captured metadata before compiling it to the processor topology. With the topology optimization framework added to the Streams DSL layer in Kafka 2.1,
Adding files to RocksDB is a cheap operation since it involves only a metadata update. Conclusion With these optimizations, we can load a dataset of 200GB uncompressed physical bytes (80GB with LZ4 compression) in 52 minutes (70 MB/s) while using 18 cores. In the current version, each write thread builds one SST file.
This layer stores the metadata needed to optimize a query or filter data. To enable and keep table maintenance simpler, all DML functions (such as DELETE and UPDATE) make use of the underlying micro-partition metadata. For instance, only a small number of operations, such as deleting all of the records from a table, are metadata-only.
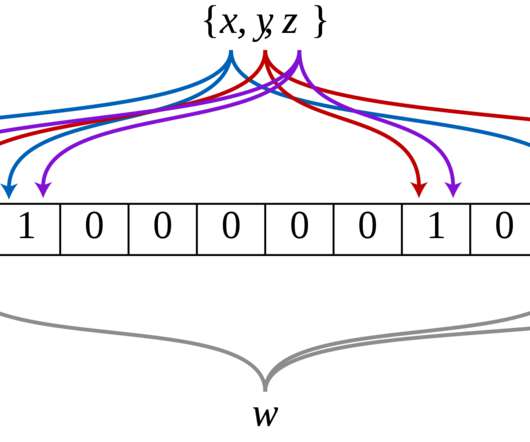
The key can be a fixed-length sequence of bits or bytes. By encrypting specific regions or metadata within images, investigators can ensure that the crucial details remain tamper-proof and secure, providing reliable evidence in legal proceedings. Key Generation: A secret encryption key is generated.
Result The scatter plot below shows the AUC (y axis) of the classifier at varying compression levels (x axis = size of the feature store in bytes in logarithmic scale). With key-value-store-based feature stores, the additional cost of storing some metadata (like event timestamps) is relatively minor. Uncompressed).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content