This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs. . "persistence_configuration":[
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how data management systems are designed. An introduction to Velox Velox is the first project in our composable data management system program.
The inspection stage examines the input media for compliance with Netflix’s delivery specifications and generates rich metadata. Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. For write operations, those challenges do not apply.
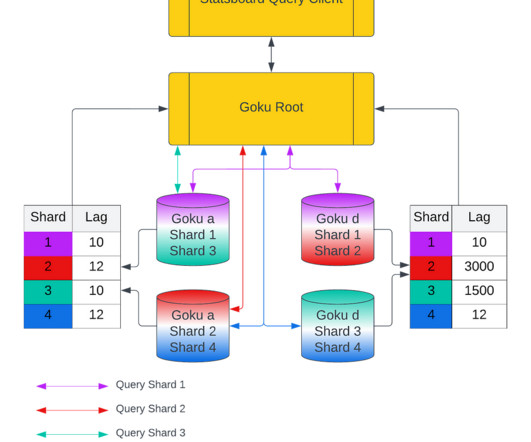
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
quintillion bytes (or 2.5 Syncing Across Data Sources Once you import data into Big Data platforms you may also realize that data copies migrated from a wide range of sources on different rates and schedules can rapidly get out of the synchronization with the originating system. exabytes) of information is being generated every day.
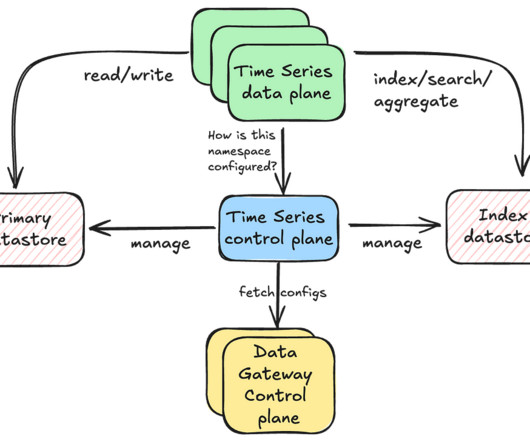
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Those use cases are well served by the Netflix Atlas telemetry system. Effectively managing this data at scale to extract valuable insights is crucial for ensuring optimal user experiences and system reliability.
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores.
Apache Kafka ® is a distributed system. When a client (producer/consumer) starts, it will request metadata about which broker is the leader for a partition—and it can do this from any broker. This is the metadata that’s passed back to clients. Using -L , you can see the metadata for the listener to which you connected.
One of the key challenges of building an enterprise-class robust scalable storage system is to validate the system under duress and failing system components. This includes, but is not limited to: failed networks, failed or failing disks, arbitrary delays in the network or IO path, network partitions, and unresponsive systems.
Datasets themselves are of varying size, from a few bytes to multiple gigabytes. Dataset propagation At Netflix we use an in-house dataset pub/sub system called Gutenberg. Each version contains metadata (keys and values) and a data pointer. An important point to note is that Gutenberg is not designed as an eventing system?—?it
To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. Each file will have an EDEK which is stored in the file’s metadata. yum install rng-tools # For Centos/RHEL 6, 7+ systems. For Centos/RHEL 7+ systems.
With real-time update streaming, Precisely solutions make data from legacy systems like the mainframe available to Confluent and, ultimately, a wide array of targets. Monitor, Push, and Explore Data: Monitor the pipelines running, track the bytes captured, and push data from the mainframe side to see it move to Confluent.
The tool leverages a multi-agent system built on LangChain and LangGraph, incorporating strategies like quality table metadata, personalized retrieval, knowledge graphs, and Large Language Models (LLMs) for accurate query generation. Lack of Byte String Support : It is difficult to handle binary data efficiently.
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
DataHub 0.8.36 – Metadata management is a big and complicated topic. DataHub is a completely independent product by LinkedIn, and the folks there definitely know what metadata is and how important it is. If you haven’t found your perfect metadata management system just yet, maybe it’s time to try DataHub!
Most training pipelines and systems are designed to handle fairly small, sub-megapixel images. These decades-old systems were tailored to support doctors in their traditional tasks, like displaying a WSI for manual analysis. A solution is to read the bytes that we need when we need them directly from Blob Storage.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
architecture (with some minor deviations) to achieve their data integration objectives around scalability and use of metadata. “A The other advantage is because we follow a standard design, we are able to generate a lot of our code using code templates and metadata. Curation Layer – Organizes the raw data. methodology.
This type of developer works with the Full stack of a software application, beginning with Front end development and going through back-end development, Database, Server, API, and version controlling systems. Git is an open source version control system that a developer/ development companies use to manage projects.
Unity Catalog As the name implies, the unity catalog brings unity to individual metastores and catalogs and serves as a central metadata repository for Databricks users. The Unity Catalog unifies metastores, catalogs, and metadata within Databricks.
Although that process started with a limited set of configurations, the old system struggled to keep up with DoorDash’s growth across new verticals. Additionally, the current system operates with a limited set of features, reducing the speed with which new capabilities and experiments can be launched.
This query will fetch a list of all tables within a database, along with helpful metadata about their settings. Use this query to extract table schema , then use this query to extract view and external table metadata. Use this query to pull how many bytes and rows tables have , as well as the time they were most recently updated.
Rockset uses RocksDB’s pluggable file system to create a disaggregated storage layer. The leader creates a replication stream and sends updates and metadata changes to follower virtual instances. Rockset uses an external strongly-consistent metadata store to perform leader election.
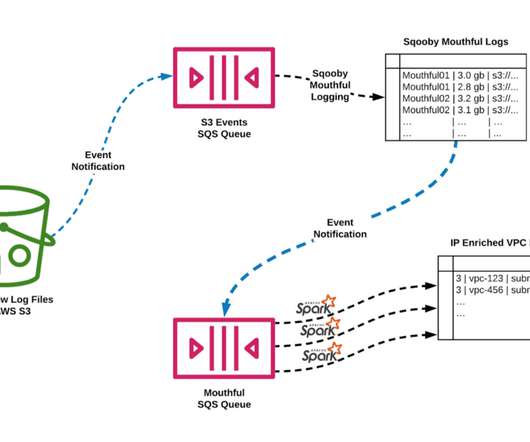
At Pinterest, petabytes of data are transported through PubSub pipelines every day, powering foundational systems such as AI training, content safety and relevance, and real-time ad bidding, bringing inspiration to hundreds of millions of Pinners worldwide. Lets dive into how this monitoring mechanism works.
The CMS system also lacked a workflow to propose and review drafts. Jinja is a popular templating system, it's used in Zalando Open Source and I use it in my own OSS projects. ms , 38.382 ms , 59.958 ms , 244.094 ms Bytes In [ total, mean ] 51441000 , 17147.00 Bytes Out [ total, mean ] 0 , 0.00 validate-content.py
This framework opens the door for various optimization techniques from the existing data stream management system (DSMS) and data stream processing literature. addSink(" SinkProcessor" , "output" , "MappingProcessor" ); System. build(properties); System. With the release of Apache Kafka ® 2.1.0, println(builder.
The following sections focus on these improvements which were made primarily to reduce system resource consumption through which one can cut capacity (pack more in less) and hence reducecost. It also facilitates sharing (ref-cnt) of byte buffers between different IOBuf objects. cpu,memory,disk usage or some application metric).
The problem When building Machine Learning (ML) applications - such as recommender systems - there is often a need to provide a "feature store" which can enrich the request to the system with additional ML features. These data are usually stored in key-value stores like Redis, using the user ID as the key, and the features as value.
Snowflake provides data warehousing, processing, and analytical solutions that are significantly quicker, simpler to use, and more adaptable than traditional systems. Snowflake is not based on existing database systems or big data software platforms like Hadoop. Snowflake is a data warehousing platform that runs on the cloud.
Here’s how to do that with Snowflake: This query will fetch a list of all tables along with helpful metadata about their settings. Since data can break literally anywhere in your pipeline, you will need a way to pull metrics and metadata from not just your warehouse, but other assets too.
For a more concrete example, we are going to write a program that will parse markdown files, extract words identified as tags, and then regenerate those files with tag-related metadata injected back into them. In push-based systems, elements would be “pushed through the stream” to the sink. collectAll [ String ]. run ( sink ).
Data is also increasingly relied upon to pinpoint problems in business, systems, products, and infrastructure. Stage 1: Validate Your Data In this framework, validation is a series of operations that can be performed as data is drawn from its source systems. No one wants to be caught chasing ghosts. In a valid schema.
HBase system consists of tables with rows and columns just like a traditional RDBMS. Partition Tolerance – System continues to work even if there is failure of part of the system or intermittent message loss. To iterate through these values in reverse order-the bytes of the actual value should be written twice.
The key can be a fixed-length sequence of bits or bytes. Although it is an outdated standard, it is still used in legacy systems and for accomplishing image encryption project work. Metadata and Steganography : Image encryption may not protect metadata associated with the images, such as timestamps, file sizes, or camera details.
It is infinitely scalable, and individuals can upload files ranging from 0 bytes to 5 TB. In S3, data consists of the following components – key (name), value (data), version ID, metadata and access control lists. However, to gain access to the underlying operating system, individuals can use Amazon RDS Custom.
RDBMS is a part of system software used to create and manage databases based on the relational model. FSCK stands for File System Check, used by HDFS. FSCK generates a summary report that covers the file system's overall health. Reliability: The entire system does not collapse if a single node or a few systems fail.
StructType is a collection of StructField objects that determines column name, column data type, field nullability, and metadata. To define the columns, PySpark offers the pyspark.sql.types import StructField class, which has the column name (String), column type (DataType), nullable column (Boolean), and metadata (MetaData).
Let me quickly describe where the RocksDB storage nodes fall in the overall system architecture. RocksDB-Cloud replicates all the data and metadata for a RocksDB instance to S3. We limit the number of bytes that can be written per second to all RocksDB instances assigned to a leaf node.
Becoming a Big Data Engineer - The Next Steps Big Data Engineer - The Market Demand An organization’s data science capabilities require data warehousing and mining, modeling, data infrastructure, and metadata management. Industries generate 2,000,000,000,000,000,000 bytes of data across the globe in a single day.
Apache Kafka and Flume are distributed data systems, but there is a certain difference between Kafka and Flume in terms of features, scalability, etc. For a system to support multi-tenancy, the level of logical isolation must be complete, but the level of physical integration may vary. Mention some real-world use cases of Apache Kaka.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content