This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Before I discuss how Kafka can make a Jaeger tracing solution in a distributed system more robust, I’d like to start by providing some context.
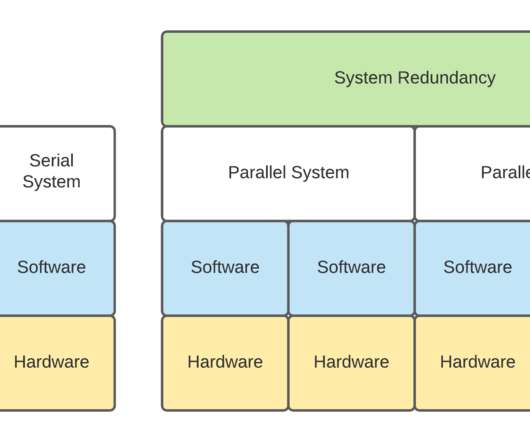
In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. . Serial and Parallel Systems Reliability . Serial Systems Reliability. Serial Systems Reliability.
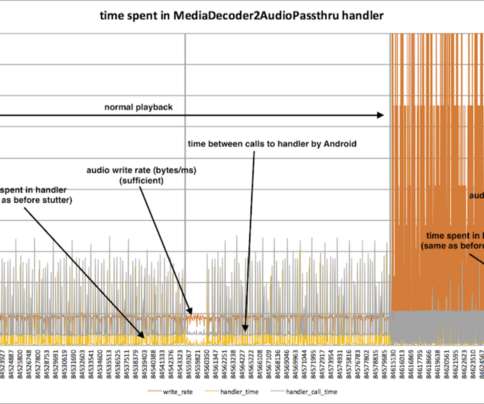
All four players involved in the device were on the call: there was the large European pay TV company (the operator) launching the device, the contractor integrating the set-top-box firmware (the integrator), the system-on-a-chip provider (the chip vendor), and myself (Netflix). Audio data is moved at about 45 bytes/ms.
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
Migrating systems to different cryptosystems always carries some risks such as interoperability issues and security vulnerabilities. In this way, we ensure that our systems remain protected against existing attacks while also providing protection against future threats. However, the key size becomes an issue during TLS resumption.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs.
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
But also, all build systems for larger C/C++ codebases typically compile and link in separate steps already, so this is closer to what we’ll encounter when we want to apply our learnings to a larger build system towards the end of this article. gold is a popular choice in many build systems, including Bazel. o hello.with-g.2
This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how data management systems are designed. An introduction to Velox Velox is the first project in our composable data management system program.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix
For instance, in both the struct s above the largest member is a pointer of size 8 bytes. Total size of the Bucket is 16 bytes. Similarly, the total size of DuplicateNode is 24 bytes. However 12 bytes is not a valid size of Bucket , as it needs to be a multiple of 8 bytes (the size of the largest member of the struct ).
Moreover, they become much harder at Meta because of: Technical debt: Systems have been built over years and have various levels of dependencies and deep integrations with other systems. Some systems serving a smaller scale began showing signs of being insufficient for the increased demands that were placed on them.
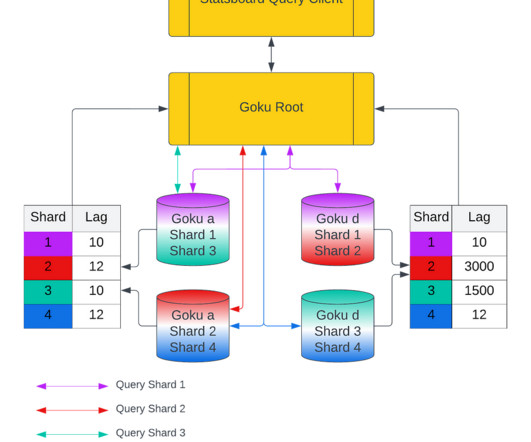
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Shown below is one original source image from the Kodak dataset and the corresponding result with JPEG 444 @ 20,429 bytes and with AVIF 444 @ 19,788 bytes.
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
It contains customizations on top of AOSP to provide the VR experience on Quest hardware, including firmware, kernel modifications, device drivers, system services, SELinux policies, and applications. As an Android variant, VROS has many of the same security features as other modern Android systems.
Last time I wrote about how Python’s 1 type system and syntax is now flexible enough to represent and utilise algebraic data types ergonomically. reading and writing to a byte stream). classmethod def decode ( cls , data : bytes ) - > Self : # Implementation goes here. Ivory towers are lonely places, after all.
Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. The index file keeps track of the physical location (URL) of each chunk and also keeps track of the physical location (URL + byte offset + size) of each video frame to facilitate downstream processing.
The Unix File System is a framework for organizing and storing large amounts of data in a manageable manner. It includes components like files, a group of connected data that can be conceptualized as a stream of bytes (or characters). In the Unix File System, a file is also the smallest storage unit. .
Designed for processing large data sets, Spark has been a popular solution, yet it is one that can be challenging to manage, especially for users who are new to big data processing or distributed systems. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool.
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka. In our production system, we observe 10% of traffic that is sent across AZs with this topologySpreadConstraints policy. topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone
quintillion bytes (or 2.5 Syncing Across Data Sources Once you import data into Big Data platforms you may also realize that data copies migrated from a wide range of sources on different rates and schedules can rapidly get out of the synchronization with the originating system. exabytes) of information is being generated every day.
you can now programmatically create NiFi reporting tasks to make relevant metrics available to various third party monitoring systems. By using component_name and “Hello World Prometheus,” we’re monitoring the bytes received aggregated by the entire process group and therefore the flow. Select the nifi_amount_bytes_received metric.
Bytes, Decimals, Numerics and oh my. This is useful to get a dump of the data, but very batchy and not always so appropriate for actually integrating source database systems into the streaming world of Kafka. Bytes, Decimals, Numerics and oh my. So our DECIMAL becomes a seemingly gibberish bytes value. Introduction.
But these signals almost entirely rely on application-level instrumentation, which can leave gaps or conflicting semantics across different systems. We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. Metrics, logs, and traces provide vital information about our service ecosystem.
It makes geospatial data can be searched and retrieved efficiently so that the system can provide the best experience to its users. To make it work properly, a good understanding of both the algorithm and the system requirements is required. GB to 55 MB and 7M to 260k). However, it has a cost that should be well considered in advance.
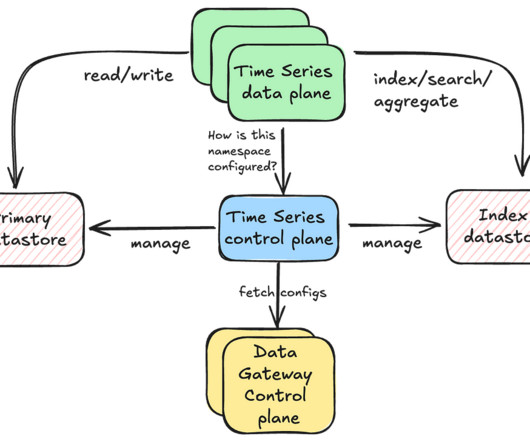
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Those use cases are well served by the Netflix Atlas telemetry system. Effectively managing this data at scale to extract valuable insights is crucial for ensuring optimal user experiences and system reliability.
END AS DEPARTMENT, PRODUCT FROM PRODUCTS; ksql> DESCRIBE PRODUCTS_ENRICHED; Name : PRODUCTS_ENRICHED Field | Type - ROWTIME | BIGINT (system) ROWKEY | VARCHAR(STRING) (system) SKU | VARCHAR(STRING) DEPARTMENT | VARCHAR(STRING) PRODUCT | VARCHAR(STRING). WHEN SKU LIKE 'F%' THEN 'Food'. ELSE 'Unknown'. 5476133448908187392.KsqlTopic.source.deserializer","time":1552564841423,"message":{"type":0,"deserializationError":{"errorMessage":"Converting
Observational astronomers study many different types of objects, from asteroids in our own solar system to galaxies that are billions of lightyears away. The technology underlying the ZTF system should be a prototype that reliably scales to LSST needs. Alert data pipeline and system design. Astronomy in real time.
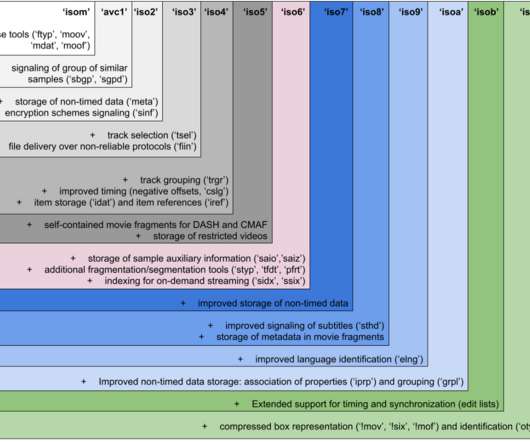
The output of an encoder is a sequence of bytes, called an elementary stream, which can only be parsed with some understanding of the elementary stream syntax. The Media Systems team at Netflix actively contributes to the development, the maintenance, and the adoption of ISOBMFF. Figure 1?—?Simplified We’re hiring!
The customer experience and marketing teams primarily use this to accelerate the acquisition of every byte of customer data from appropriate channels, devices, and platforms and its transformation into a unified customer profile. Companies frequently use CDP Software as the sole source of consumer information.
One of the key challenges of building an enterprise-class robust scalable storage system is to validate the system under duress and failing system components. This includes, but is not limited to: failed networks, failed or failing disks, arbitrary delays in the network or IO path, network partitions, and unresponsive systems.
Data retention: Many legacy SIEMS delete activity logs, transaction records, and other details from their systems after a few days, weeks or months. In the cloud, computing can be measured in various ways, like bytes scanned or CPU cycles. With Snowflake, security teams don’t have to work around these data retention windows.
Alternatively, you can get money into the system by simply depositing money with the push of a button. The events are handled by the command handler, which is the part of the system that has been ported to Rust. Make sure it is indeed an ID and that the Value matches the expected type Fixed , with 16 bytes. The bank application.
Pinterest metrics system Goku-Ingestor has been running and evolving for close to a decade. Reliability Issues In the initial months of 2023, certain problems arose as a result of Goku-Ingestor’s performance, leading to some instances where data loss occurred within the metrics system for a brief duration of time.
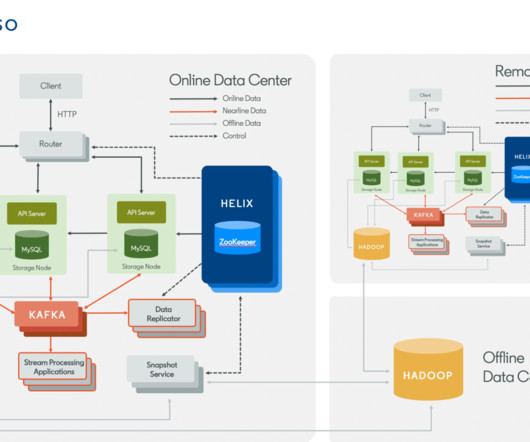
In this post, we will explain how we solved these challenges and improved system performance. Espresso System Overview Figure 1 is a high-level overview of the Espresso ecosystem, which includes the online operation section of Espresso (the main focus of this blog post). This delay can significantly affect the system's response time.
MySQL wanted to ensure that its index files could fit within a single page block on older file systems. However, the the most popular text encoding ( Latin1 or utf8 ) on the most popular MySQL database engine ( innodb ) assumed that 3 bytes was enough to store every character 2 , and once utf8mb4 came along with characters like ?
When a user tries to perform a transaction or action on a system, he or she will present some credentials like an email or a phone number. The system will send a temporary secure PIN-code or token to the user by email or phone number valid for only that session. generate ( 512 ))) } private val secret : Array [ Byte ] = user.
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores. The major pieces, as shown in Fig.
AWS, for example, offers services such as Amazon FSx and Amazon EFS for mirroring your data in a high-performance file system in the cloud. Here we show how to download specific byte-ranges of the file using the Boto3 get_object data streaming API. For these use cases, downloading the entire file can be extremely wasteful.
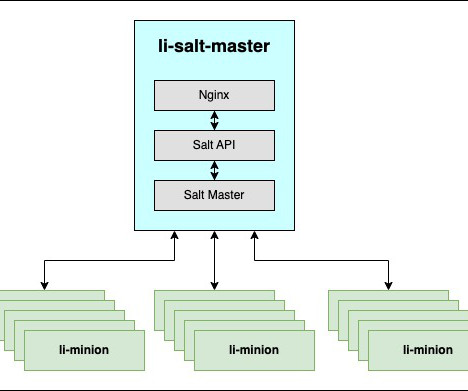
Minion (an agent on host) sees jobs and results by subscribing to events published on the event bus by master service, It uses ZMQ (ZeroMQ) to achieve high-speed, asynchronous communication between connected systems. Targeted minions execute the job on the host and return to master. login is modified to rely on mTLS at Nginx level.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content