This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
Using Jaeger tracing, I’ve been able to answer an important question that nearly every Apache Kafka ® project that I’ve worked on posed: how is data flowing through my distributed system? Before I discuss how Kafka can make a Jaeger tracing solution in a distributed system more robust, I’d like to start by providing some context.
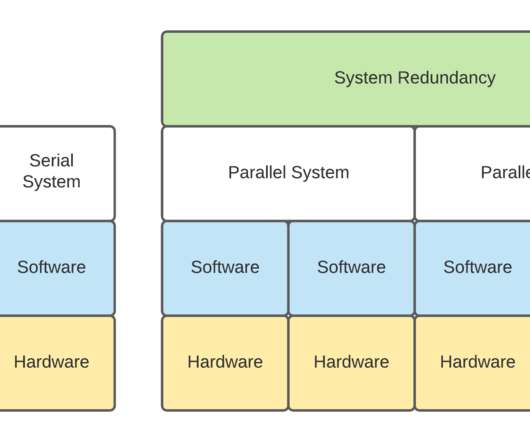
In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. . Serial and Parallel Systems Reliability . Serial Systems Reliability. Serial Systems Reliability.
By recording changes as they occur, CDC enables real-time data replication and transfer, minimizing the impact on source systems and ensuring timely consistency across downstream data stores and processing systems that depend on thisdata.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
Borg, Google's large-scale cluster management system, distributes computing resources for the Dremel tasks. Dremel tasks read data from Google's Colossus file systems through the Jupiter network, conduct various SQL operations, and provide results to the client.
In recent years, while managing Pinterests EC2 infrastructure, particularly for our essential online storage systems, we identified a significant challenge: the lack of clear insights into EC2s network performance and its direct impact on our applications reliability and performance.
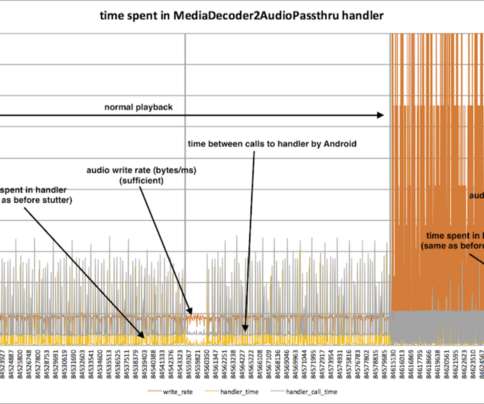
All four players involved in the device were on the call: there was the large European pay TV company (the operator) launching the device, the contractor integrating the set-top-box firmware (the integrator), the system-on-a-chip provider (the chip vendor), and myself (Netflix). Audio data is moved at about 45 bytes/ms.
The first level is a hashed string ID (the primary key), and the second level is a sorted map of a key-value pair of bytes. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs.
This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how data management systems are designed. An introduction to Velox Velox is the first project in our composable data management system program.
Migrating systems to different cryptosystems always carries some risks such as interoperability issues and security vulnerabilities. In this way, we ensure that our systems remain protected against existing attacks while also providing protection against future threats. However, the key size becomes an issue during TLS resumption.
NGAPI, the API platform for serving all first party client API requests, requires optimized system performance to ensure a high success rate of requests and allow for maximum efficiency to provide Pinners worldwide with engaging content. To the left, a glowing Pinterest P sign hovers in front of a glasswall.
But also, all build systems for larger C/C++ codebases typically compile and link in separate steps already, so this is closer to what we’ll encounter when we want to apply our learnings to a larger build system towards the end of this article. gold is a popular choice in many build systems, including Bazel. o hello.with-g.2
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS can be configured to cache objects on the local disk. Regional caching? —?Netflix
Moreover, they become much harder at Meta because of: Technical debt: Systems have been built over years and have various levels of dependencies and deep integrations with other systems. Some systems serving a smaller scale began showing signs of being insufficient for the increased demands that were placed on them.
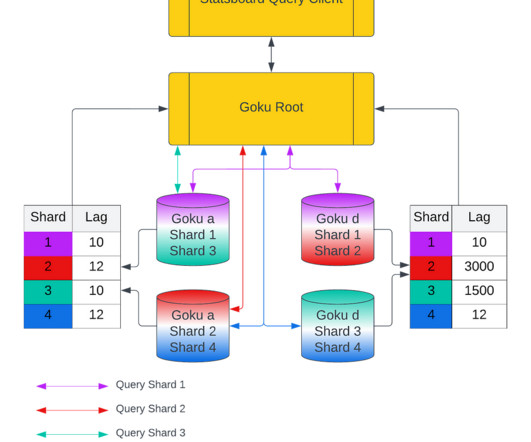
Initial Architecture For Goku Short Term Ingestion Figure 1: Old push based ingestion pipeline into GokuS At Pinterest, we have a sidecar metrics agent running on every host that logs the application system metrics time series data points (metric name, tag value pairs, timestamp and value) into dedicated kafka topics.
For example, Amazon Redshift can load static data to Spark and process it before sending it to downstream systems. In other words, developers and system administrators can focus their efforts on developing more innovative applications instead of learning, implementing, and maintaining different frameworks. pre-computed models).
For instance, in both the struct s above the largest member is a pointer of size 8 bytes. Total size of the Bucket is 16 bytes. Similarly, the total size of DuplicateNode is 24 bytes. However 12 bytes is not a valid size of Bucket , as it needs to be a multiple of 8 bytes (the size of the largest member of the struct ).
The goal is to have the compressed image look as close to the original as possible while reducing the number of bytes required. Shown below is one original source image from the Kodak dataset and the corresponding result with JPEG 444 @ 20,429 bytes and with AVIF 444 @ 19,788 bytes.
Snowflake provides data warehousing, processing, and analytical solutions that are significantly quicker, simpler to use, and more adaptable than traditional systems. Snowflake is not based on existing database systems or big data software platforms like Hadoop. Snowflake is a data warehousing platform that runs on the cloud.
It contains customizations on top of AOSP to provide the VR experience on Quest hardware, including firmware, kernel modifications, device drivers, system services, SELinux policies, and applications. As an Android variant, VROS has many of the same security features as other modern Android systems.
What makes it different from traditional RAG systems? Multimodal RAG System Applications and Use Cases Learn and Implement Multimodal RAG with ProjectPro! The system intelligently manages various data types within the context window, ensuring coherent relationships between them. But, how does it actually work?
The UDP header is fixed at 8 bytes and contains a source port, destination port, the checksum used to verify packet integrity by the receiving device, and the length of the packet which equates to the sum of the payload and header. flip () println ( s "[server] I've received ${content.limit()} bytes " + s "from ${clientAddress.toString()}!
Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. The index file keeps track of the physical location (URL) of each chunk and also keeps track of the physical location (URL + byte offset + size) of each video frame to facilitate downstream processing.
Google offers "on-demand pricing," where users are charged for each byte of requested and processed data; the first 1 TB of data per month is free. Alternatively, Redshift might give you the flexibility you need if you have system experts who can modify the architecture to your demands. The hourly rate starts at $0.25
Last time I wrote about how Python’s 1 type system and syntax is now flexible enough to represent and utilise algebraic data types ergonomically. reading and writing to a byte stream). classmethod def decode ( cls , data : bytes ) - > Self : # Implementation goes here. Ivory towers are lonely places, after all.
Apache Kafka and Flume are distributed data systems, but there is a certain difference between Kafka and Flume in terms of features, scalability, etc. For a system to support multi-tenancy, the level of logical isolation must be complete, but the level of physical integration may vary.
The Unix File System is a framework for organizing and storing large amounts of data in a manageable manner. It includes components like files, a group of connected data that can be conceptualized as a stream of bytes (or characters). In the Unix File System, a file is also the smallest storage unit. .
This decision impacts disk performance, resource allocation, and overall system efficiency. String & Binary Snowflake Data Types VARCHAR, STRING, TEXT Snowflake data types It is a variable-length character string of a maximum of 16,777,216 bytes and holds Unicode characters(UTF-8).
Hadoop Datasets: These are created from external data sources like the Hadoop Distributed File System (HDFS) , HBase, or any storage system supported by Hadoop. The following methods should be defined or inherited for a custom profiler- profile- this is identical to the system profile. dump- saves all of the profiles to a path.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional data lakes, enter the world of Databricks Delta Lake now. This results in a fast and scalable metadata handling system.
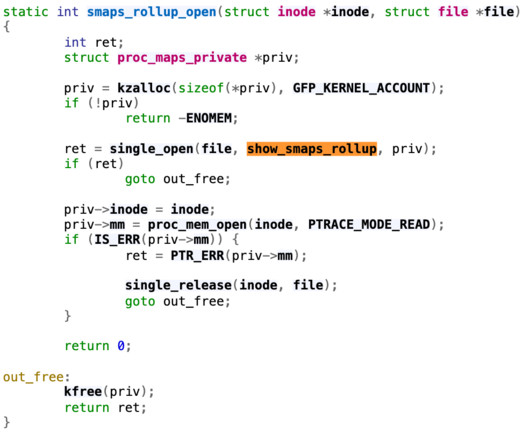
Following through the single_open function , we will find that it uses the function show_smaps_rollup for the show operation, which can translate to the read system call on the file. Let’s first focus on the handler of open syscall on this /proc/<pid>/smaps_rollup. Next, we look at the show_smaps_rollup implementation. seconds!
Designed for processing large data sets, Spark has been a popular solution, yet it is one that can be challenging to manage, especially for users who are new to big data processing or distributed systems. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool.
you can now programmatically create NiFi reporting tasks to make relevant metrics available to various third party monitoring systems. By using component_name and “Hello World Prometheus,” we’re monitoring the bytes received aggregated by the entire process group and therefore the flow. Select the nifi_amount_bytes_received metric.
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka. In our production system, we observe 10% of traffic that is sent across AZs with this topologySpreadConstraints policy. topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone
This powerful platform addresses the challenges of data ingestion, distribution, and transformation across diverse systems. NiFi supports connectivity with many systems, including databases, cloud services, and IoT devices, while emphasizing data lineage, security, and extensibility. What is Apache NiFi Used For?
quintillion bytes (or 2.5 Syncing Across Data Sources Once you import data into Big Data platforms you may also realize that data copies migrated from a wide range of sources on different rates and schedules can rapidly get out of the synchronization with the originating system. exabytes) of information is being generated every day.
Bytes, Decimals, Numerics and oh my. This is useful to get a dump of the data, but very batchy and not always so appropriate for actually integrating source database systems into the streaming world of Kafka. Bytes, Decimals, Numerics and oh my. So our DECIMAL becomes a seemingly gibberish bytes value. Introduction.
Quintillion Bytes of data per day. It is a data management system that facilitates and supports Business Intelligence. It is time-variant, meaning it has a timestamp to track the data coming into the system. As per statistics, we produce 2.5 The problem lies in the real-world data.
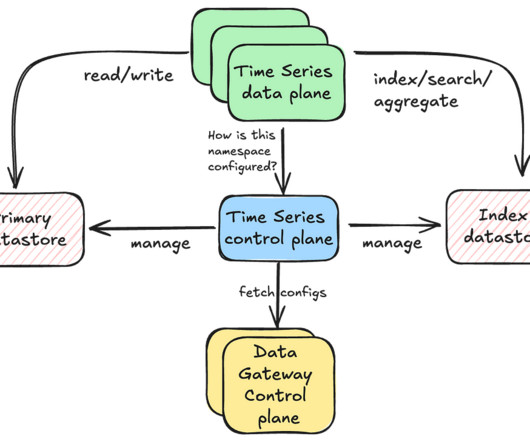
Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Those use cases are well served by the Netflix Atlas telemetry system. Effectively managing this data at scale to extract valuable insights is crucial for ensuring optimal user experiences and system reliability.
But these signals almost entirely rely on application-level instrumentation, which can leave gaps or conflicting semantics across different systems. We also have an unmarshalling function to convert the raw bytes from the kernel into our structure. Metrics, logs, and traces provide vital information about our service ecosystem.
It makes geospatial data can be searched and retrieved efficiently so that the system can provide the best experience to its users. To make it work properly, a good understanding of both the algorithm and the system requirements is required. GB to 55 MB and 7M to 260k). However, it has a cost that should be well considered in advance.
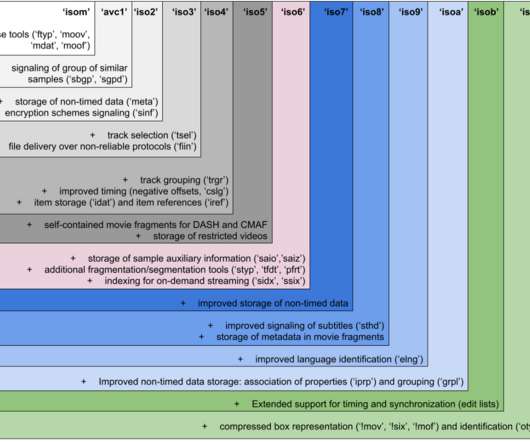
The output of an encoder is a sequence of bytes, called an elementary stream, which can only be parsed with some understanding of the elementary stream syntax. The Media Systems team at Netflix actively contributes to the development, the maintenance, and the adoption of ISOBMFF. Figure 1?—?Simplified We’re hiring!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content