This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data lakes provide a way to store and process large amounts of raw data in its original format, […] The post Setting up Data Lake on GCP using CloudStorage and BigQuery appeared first on Analytics Vidhya. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Before we get started, let’s be clear…when using cloudstorage, it is usually not recommended to work with files that are particularly large. here , here , and here ). CPU cores and TCP connections).
The rush towards cloudstorage means that the cloud has to offer a valuable proposition to businesses. Let’s explore why businesses regardless of their size should consider moving to the cloud.
And that’s the target of today’s post — We’ll be developing a data pipeline using Apache Spark, Google CloudStorage, and Google Big Query (using the free tier) not sponsored. Google CloudStorage (GCS) is Google’s blob storage. Create a new bucket in the Google CloudStorage named censo-ensino-superior 4.
Our latest blog dives into enabling security for Uber’s modernized batch data lake on Google CloudStorage! Ready to boost your Hadoop Data Lake security on GCP?
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure).
Faster compute: Iceberg's metadata layer is optimized for cloudstorage, allowing for advance file and partition pruning with minimal IO overhead. Get started: Begin activating data stored in a cloudstorage provider, without lock-in, by creating Iceberg tables directly from existing Parquet files in Snowflake.
Powered by Apache HBase and Apache Phoenix, COD ships out of the box with Cloudera Data Platform (CDP) in the public cloud. It’s also multi-cloud ready to meet your business where it is today, whether AWS, Microsoft Azure, or GCP. We tested for two cloudstorages, AWS S3 and Azure ABFS. runtime version.
But one thing is for sure, tech enthusiasts like us will never stop hunting for the best free online cloudstorage platforms to upgrade our unlimited free cloudstorage game. What is CloudStorage? Cloudstorage provides you with cost-effective, scalable storage. What is the need for it?
Process => CloudStorage => Data Warehouse 2. CloudStorage => process => Data Warehouse Conclusion Further Reading Introduction Loading data into a data warehouse is a key component of most data pipelines. Introduction Patterns 1. Batch Data Pipelines 1.1 Process => Data Warehouse 1.2
If you've learned something or tried out a project from the show then tell us about it! Email hosts@dataengineeringpodcast.com ) with your story. If you've learned something or tried out a project from the show then tell us about it! Email hosts@dataengineeringpodcast.com ) with your story.
We started to consider breaking the components down into different plugins, which could be used for more than just cloudstorage. Adding further plugins So first we took the cloud specific aspects and put them into a cloud-storage-metadata plugin, which would retrieve the replication factor based on the vendor and service being used.
Introduction If you are looking for a simple, cheap data pipeline to pull small amounts of data from a stable API and store it in a cloudstorage, then serverless functions are a good choice.
Cost Efficiency and Scalability Open Table Formats are designed to work with cloudstorage solutions like Amazon S3, Google CloudStorage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions. Amazon S3, Azure Data Lake, or Google CloudStorage).
Rather than streaming data from source into cloud object stores then copying it to Snowflake, data is ingested directly into a Snowflake table to reduce architectural complexity and reduce end-to-end latency.
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloudstorage location. With these three options, which one should you use?
By storing data in its native state in cloudstorage solutions such as AWS S3, Google CloudStorage, or Azure ADLS, the Bronze layer preserves the full fidelity of the data. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
While cloud computing is pushing the boundaries of science and innovation into a new realm, it is also laying the foundation for a new wave of business start ups. 5 Reasons Your Startup Should Switch To CloudStorage Immediately 1) Cost-effective Probably the strongest argument in cloud’s favor I is the cost-effectiveness that it offers.
A common use case is to process a file after it lands on a cloudstorage system. This event can be a file creation on S3, a new database row, API call, etc.
Learn about the capabilities and benefits of NOS WRITE -- the latest offering within the Native Object Store feature, which was released in early 2020.
From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloudstorage and then downloaded by the next processing step. Since not all projects are terabytes projects, allocating the largest cloudstorage to all packager instances is not an efficient use of cloud resources.
CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloudstorage, machine learning (ML), streaming analytics, and enterprise grade security built-in. What if you could access all your data and execute all your analytics in one workflow, quickly with only a small IT team?
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a Data Lake implemented with cloudstorage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools. AWS Redshift, GCP Big Query, or Azure Synapse work well, too.
For example, you can create a custom cluster today that includes both NiFi and Spark; this will allow you to use the extensive library of NiFi processors to easily ingest data into Google CloudStorage, use Spark for processing and preparing the data for analytics, all in one cluster.
What are the types of storage and data systems that you integrate with? How do the trends in cloudstorage and data systems influence the ways that you evolve the system? What are the types of storage and data systems that you integrate with? Can you describe how the Aparavi platform is implemented?
A TPC-DS 10TB dataset was generated in ACID ORC format and stored on the ADLS Gen 2 cloudstorage. A few metastore configuration parameters had to be added to allow queries against large partitioned tables. . Both CDW and HDInsight had all 10 nodes running LLAP daemons with SSD cache ON. Cloudera Data Warehouse vs HDInsight.
Separate storage. Cloudera’s Data Warehouse service allows raw data to be stored in the cloudstorage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. Get your data in place. S3 bucket).
Contact Info LinkedIn @yairwein on Twitter Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? Contact Info LinkedIn @yairwein on Twitter Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today?
Additionally, it offers genuine multi-cloud flexibility by integrating easily with AWS, Azure, and GCP. JSON, Avro, Parquet, and other structured and semi-structured data types are supported by the natively optimized proprietary format used by the cloudstorage layer.
RK built some simple flows to pull streaming data into Google CloudStorage and Snowflake. Many developers use DataFlow to filter/enrich streams and ingest into cloud data lakes and warehouses where the ability to process and route anywhere makes DataFlow very effective. Congratulations Vince!
There was a strong requirement to seamlessly migrate hundreds of users, roles, and other account-level objects, including compute resources and cloudstorage integrations. Additionally, Magnite’s Snowflake account was integrated with an identity provider for Single Sign-On (SSO).
Step 1: Separate Compute and Storage One of the ways we first extended RocksDB to run in the cloud was by building RocksDB Cloud , in which the SST files created upon a memtable flush are also backed into cloudstorage such as Amazon S3.
Striim customers often utilize a single streaming source for delivery into Kafka, Cloud Data Warehouses, and cloudstorage, simultaneously and in real-time. Building streaming data pipelines shouldnt require custom coding Building data pipelines and working with streaming data should not require custom coding.
YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS or cloudstorage like S3 and ADLS. You need to configure the backup repository in solr xml to point to your cloudstorage location (in this example your S3 bucket). Prerequisites.
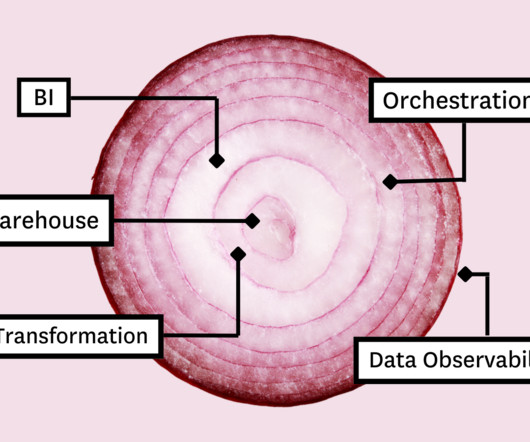
Those tools include: Cloudstorage and compute Data transformation Business intelligence Data observability And orchestration And we won’t mention ogres or bean dip again. Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up. Let’s dive into it.
we officially made Tiered Storage generally available. At launch, we supported two major cloud-specific object stores: Amazon S3 and Google CloudStorage. With the release of Confluent Platform 6.0, Today, […].
Our experience so far reveals firms are still in the early stages of understanding the operational model and the total cost of ownership related to data platforms deployed in the cloud compared to on-premise deployments. In some cases, firms are surprised by cloudstorage costs and looking to repatriate data.
Conclusion Media and entertainment are witnessing a notable transformation, with AI and cloud computing emerging as the new pioneers in enabling faster production and providing enhanced capabilities while reducing costs.
The Ranger Authorization Service (RAZ) is a new service added to help provide fine-grained access control (FGAC) for cloudstorage. RAZ for S3 and RAZ for ADLS introduce FGAC and Audit on CDP’s access to files and directories in cloudstorage making it consistent with the rest of the SDX data entities. Conclusion.
Ingestion Pipelines : Handling data from cloudstorage and dealing with different formats can be efficiently managed with the accelerator. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool. This is ideal for tasks such as data aggregation, reporting or batch predictions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content