This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This would be the right way to go for data analyst teams that are not familiar with coding. Indeed, why would we build a data connector from scratch if it already exists and is being managed in the cloud? There are many other tools with more specific applications, i.e. extracting data from web pages (PyQuery, BeautifulSoup, etc.)
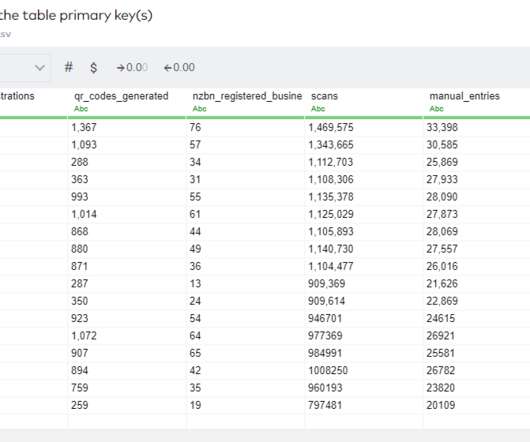
The dbt docs suggest using seeds for “files that contain business-specific logic, for example, a list of country codes or user IDs of employees.” Below is a summary table highlighting the core benefits and drawbacks of certain ETLtooling options for getting spreadsheet data in your data warehouse.
After trying all options existing on the market — from messaging systems to ETLtools — in-house data engineers decided to design a totally new solution for metrics monitoring and user activity tracking which would handle billions of messages a day. How Apache Kafka streams relate to Franz Kafka’s books. Large user community.
Their tasks include: Designing systems for collecting and storing data Testing various parts of the infrastructure to reduce errors and increase productivity Integrating data platforms with relevant tools Optimizing data pipelines Using automation to streamline data management processes Ensuring data security standards are met When it comes to skills (..)
Services like AWS Glue , Databricks , and Dataproc have powerful data lake capabilities, where code-heavy processes and agile workflows can transform data into many different forms. There are a range of tools dedicated to just the extraction (“E”) function to land data in any type of data warehouse or data lake.
Publish: Transformed data is then published either back to on-premises sources like SQL Server or kept in cloudstorage. This makes the data ready for consumption by BI tools, analytics applications, or other systems. ADF can pass parameters from your ADF pipeline straight into your Databricks code.
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google CloudStorage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. Databricks lakehouse platform architecture.
From the Airflow side A client has 100 data pipelines running via a cron job in a GCP (Google Cloud Platform) virtual machine, every day at 8am. In a Google CloudStorage bucket. And that common interface is configured in code + version-controlled. Where can I view history in a table format?”
An ETLtool or API-based batch processing/streaming is used to pump all of this data into a data warehouse. Transformation tools like dbt are also very popular low-code, no-code alternatives to build data models and consolidate data so that it is ready to be consumed.
ETL (extract, transform, and load) techniques move data from databases and other systems into a single hub, such as a data warehouse. Get familiar with popular ETLtools like Xplenty, Stitch, Alooma, etc. Hadoop, MongoDB, and Kafka are popular Big Data tools and technologies a data engineer needs to be familiar with.
In other words, you will write codes to carry out one step at a time and then feed the desired data into machine learning models for training sentimental analysis models or evaluating sentiments of reviews, depending on the use case. You can use big-data processing tools like Apache Spark , Kafka , and more to create such pipelines.
NET) Java, JavaScript, Node.js, and Python are hosted on-prem and in the cloud. Monitoring is enabled for both backend and frontend codes. Pricing is expensive compared to other Azure etltools. Logging and managing storage resources is effortless, making this tool popular among competitors.
It’s like having the source code of your customer’s behavior – with enough time and processing power, you can recreate any view of your customer base. But with modern cloudstorage solutions and clever techniques like log compaction (where obsolete entries are removed), this is becoming less and less of an issue.
For example, address data may have misspelled street names, incorrect zip codes, etc., or mobile numbers may have special symbols and country codes appended before them. Cloudstorage is the best option for storing all the processed data, and it is secure and easily accessible, and no infrastructure is required.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content