This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Faster compute: Iceberg's metadata layer is optimized for cloudstorage, allowing for advance file and partition pruning with minimal IO overhead. Building an open data lakehouse Snowflakes goal is to help organizations establish and accelerate their open lakehouse ambitions so they can unlock more impact with less complexity.
This is particularly beneficial in complex analytical queries, where processing smaller, targeted segments of data results in quicker and more efficient query execution. Additionally, the optimized query execution and data pruning features reduce the compute cost associated with querying large datasets.
Bronze, Silver, and Gold – The DataArchitecture Olympics? The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
In contrast to conventional warehouses, it keeps computation and storage apart, allowing for cost-effectiveness and dynamic scaling. It provides real multi-cloud flexibility in its operations on AWS , Azure, and Google Cloud. Its multi-cluster shared dataarchitecture is one of its primary features.
We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, and Data Council. Upcoming events include the O’Reilly AI conference, the Strata Data conference, the combined events of the DataArchitecture Summit and Graphorum, and Data Council in Barcelona.
Cloudera’s Shared Data Experience (SDX) provides all these capabilities allowing seamless data sharing across all the Data Services including CDE. A new capability called Ranger Authorization Service (RAZ) provides fine grained authorization on cloudstorage. Modernizing pipelines.
The consumption of the data should be supported through an elastic delivery layer that aligns with demand, but also provides the flexibility to present the data in a physical format that aligns with the analytic application, ranging from the more traditional data warehouse view to a graph view in support of relationship analysis.
So, you set up data systems and start filling up those tables or topics. After a few years go by you can end up with huge volumes of data. Maybe you need to scale up to a cloudstorage provider like Snowflake or AWS to keep up and make all this data accessible at the pace you need. You’re using the data, of course!
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
Integration with Azure and Data Sources Fabric is deeply integrated with Azure tools such as Synapse, Data Factory, and OneLake. This allows seamless data movement and end-to-end workflows within the same environment. Its flexibility suits advanced users creating end-to-end data solutions.
With the right technology now in place, ATB Financial is landing and curating more data than ever to bring data-driven insights to the business and its customers. Implementing a Modern DataArchitecture.
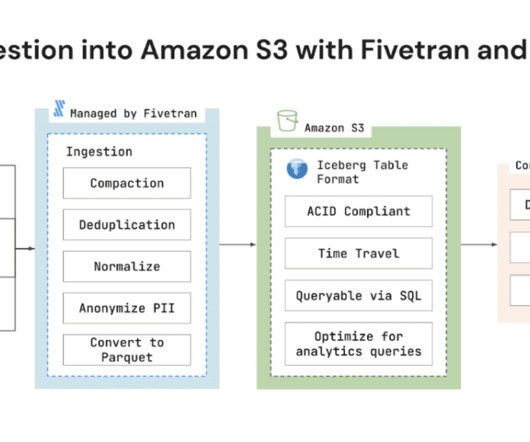
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format.
These robust security measures ensure that data is always secure and private. There are several widely used unstructured datastorage solutions such as data lakes (e.g., Amazon S3, Google CloudStorage, Microsoft Azure Blob Storage), NoSQL databases (e.g., Build dataarchitecture.
Data-in-motion is predominantly about streaming data so enterprises typically have two different ways or binary ways of looking at data. This can extend to streaming analytics capabilities into any cloud environment.
You will retain use of the following Google Cloud application deployment environments: App Engine, Kubernetes Engine, and Compute Engine. Select and use one of Google Cloud's storage solutions, which include CloudStorage, Cloud SQL, Cloud Bigtable, and Firestore.
Organizations that depend on data for their success and survival need robust, scalable dataarchitecture, typically employing a data warehouse for analytics needs. Snowflake is often their cloud-native data warehouse of choice. Snowflake provides a couple of ways to load data.
A lot of new transforms and actions have appeared, and Apache Hop integrates a lot better with existing dataarchitectures. Container and cloud support : Hop comes with a pre-built container image for long-lived (Hop Server) and short-lived (Hop Run) scenarios.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including data lakes, databases, streaming platforms, and cloudstorage. This flexibility allows organizations to ingest data from virtually anywhere.
Databricks lakehouse platform architecture. Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google CloudStorage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others.
Hadoop, MongoDB, and Kafka are popular Big Data tools and technologies a data engineer needs to be familiar with. Companies are increasingly substituting physical servers with cloud services, so data engineers need to know about cloudstorage and cloud computing.
In the dynamic world of data, many professionals are still fixated on traditional patterns of data warehousing and ETL, even while their organizations are migrating to the cloud and adopting cloud-native data services. Central to this transformation are two shifts.
They must load the raw data into a data warehouse for this analysis. There are numerous ways to import data into a data warehouse using SQL. For instance, data engineers can easily transfer the data onto a cloudstorage system and load the raw data into their data warehouse using the COPY INTO command.
What is a Big Data Pipeline? Data pipelines have evolved to manage big data, just like many other elements of dataarchitecture. Big data pipelines are data pipelines designed to support one or more of the three characteristics of big data (volume, variety, and velocity).
Gone are the days of just dumping everything into a single database; modern dataarchitectures typically use a combination of data lakes and warehouses. Think of your data lake as a vast reservoir where you store raw data in its original form—great for when you’re not quite sure how you’ll use it yet.
But with modern cloudstorage solutions and clever techniques like log compaction (where obsolete entries are removed), this is becoming less and less of an issue. The benefits of log-based approaches often far outweigh the storage costs. It’s a place where raw, unaltered customer data is stored indefinitely.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 What are the main components of a big dataarchitecture?
The world of data management is undergoing a rapid transformation. The rise of cloudstorage, coupled with the increasing demand for real-time analytics, has led to the emergence of the Data Lakehouse. This paradigm combines the flexibility of data lakes with the performance and reliability of data warehouses.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content