This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datastorage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Ready to boost your Hadoop DataLake security on GCP? Our latest blog dives into enabling security for Uber’s modernized batch datalake on Google CloudStorage!
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free!
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise DataCloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure).
Note : CloudData warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake.
It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience. No matter the workload, Fabric stores all data on OneLake, a single, unified datalake built on the Delta Lake model.
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a DataLake implemented with cloudstorage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools.
The Cloudera platform delivers a one-stop shop that allows you to store any kind of data, process and analyze it in many different ways in a single environment, and integrate with the rest of your data infrastructure. But working with cloudstorage has often been a compromise. As a Hadoop developer, I loved that!
Datalakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloudstorage location. With these three options, which one should you use?
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? . Athena on AWS. .
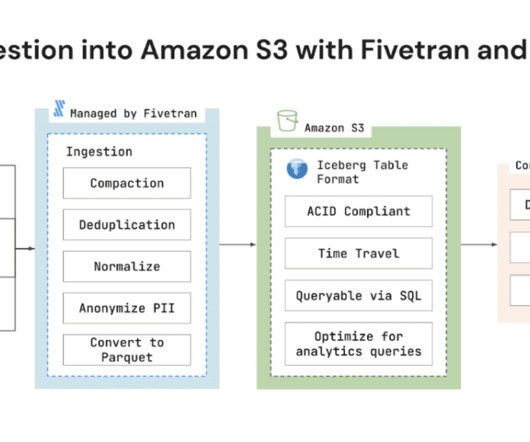
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Of high value to existing customers, Cloudera’s Data Warehouse service has a unique, separated architecture. . Separate storage. Cloudera’s Data Warehouse service allows raw data to be stored in the cloudstorage of your choice (S3, ADLSg2). Proprietary file formats mean no one else is invited in!
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. What are the mechanisms that you use for categorizing data assets?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
With the addition of Google Cloud, we deliver on our vision of providing a hybrid and multi-cloud architecture to support our customer’s analytics needs regardless of deployment platform. . You could then use an existing pipeline to run analytics on the prepared data in BigQuery. .
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public CloudDataLake. CDP DataLake cluster versions – CM 7.4.0, Configure the required ports to enable connectivity from CDH to CDP Public Cloud (see docs for details).
An open-source implementation of a DataLake with DuckDB and AWS Lambdas A duck in the cloud. Photo by László Glatz on Unsplash In this post we will show how to build a simple end-to-end application in the cloud on a serverless infrastructure. The idea is to start from a DataLake where our data are stored.
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented data warehouses and datalakes both rely on the durability and ease of use that it provides. How do you approach project governance and sustainability?
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
RK built some simple flows to pull streaming data into Google CloudStorage and Snowflake. Many developers use DataFlow to filter/enrich streams and ingest into clouddatalakes and warehouses where the ability to process and route anywhere makes DataFlow very effective.
link] Uber: Enabling Security for Hadoop DataLake on Google CloudStorage Uber writes about securing a Hadoop-based datalake on Google Cloud Platform (GCP) by replacing HDFS with Google CloudStorage (GCS) while maintaining existing security models like Kerberos-based authentication.
Cloudera Data Platform 7.2.1 introduces fine-grained authorization for access to Azure DataLakeStorage using Apache Ranger policies. Cloudera and Microsoft have been working together closely on this integration, which greatly simplifies the security administration of access to ADLS-Gen2 cloudstorage.
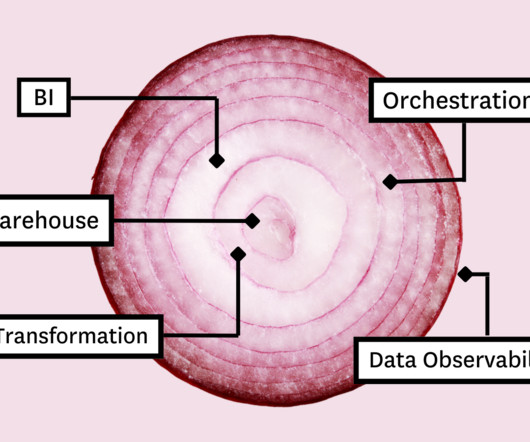
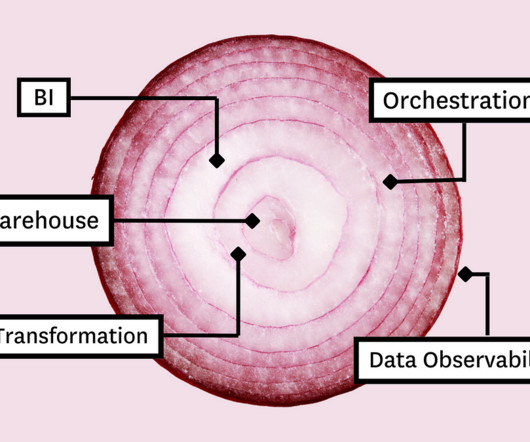
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
They make data workflows more resilient and easier to manage when things inevitably go sideways. This guide tackles the big decisions every data engineer faces: Should you clean your data before or after loading it? Datalake or warehouse? DataLakes vs. Data Warehouses: Where Should Your Data Live?
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.
Conclusion WeCloudData helped a client build a flexible data pipeline to address the needs from multiple business units requiring different sets, views and timelines of job market data.
Conclusion WeCloudData helped a client build a flexible data pipeline to address the needs from multiple business units requiring different sets, views and timelines of job market data.
Even the best of us sometimes demonize the parts of our organization whose primary goals are in the privacy and security area and conflict with our wishes to splash around in the datalake. In reality, data scientists are not always the heroes and IT and security teams are not the villains. You’re using the data, of course!
With this feature, you can efficiently manage, govern, and analyze your data irrespective of its storage location, ensuring optimal data management. This feature significantly contributes to enhancing your data management capabilities within the Snowflake ecosystem. Zero egress fees mean zero vendor lock-in.”
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. There are several widely used unstructured datastorage solutions such as datalakes (e.g., Hadoop, Apache Spark).
ADF leverages compute services like Azure HDInsight, Spark, Azure DataLake Analytics, or Machine Learning to process and analyze the data according to defined requirements. Publish: Transformed data is then published either back to on-premises sources like SQL Server or kept in cloudstorage.
Datalakes: These are large-scale datastorage systems that are designed to store and process large amounts of raw, unstructured data. Examples of technologies able to aggregate data in datalake format include Amazon S3 or Azure DataLake. Stanford's Relational Databases and SQL.
Improved support for cloudstorage systems like S3 (with S3Guard ), Microsoft Azure DataLake, and Aliyun OSS. YARN Timeline Service v2, which improves the scalability, reliability, and usability of the existing Timeline Service. See the Apache Hadoop 3.0.0 documentation for a full rundown of the changes.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
Each workspace is associated with a collection of cloud resources. In the case of CDP Public Cloud, this includes virtual networking constructs and the datalake as provided by a combination of a Cloudera Shared Data Experience (SDX) and the underlying cloudstorage.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including datalakes, databases, streaming platforms, and cloudstorage. This flexibility allows organizations to ingest data from virtually anywhere.
Snowflake’s solution to ingesting very large healthcare pricing transparency data files. In the above solution approach, the pricing transparency JSON file is hosted in a cloudstorage bucket and is referenced through an external stage on Snowflake.
Organizations find they have much more agility with analytics in the cloud and can operate at a lower cost point than has been possible with legacy on-premises solutions. Generally, instances for transient clusters need only minimal local disk space, since data processing runs directly on the data in the cloudstorage.
Also, Cloud Endpoints are used, which help speed up the development, making smoother API calls for mobile app development. DataLake using Google Cloud Platform What is a DataLake? DataLake is a centralized area or repository for datastorage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content