
Setting up Data Lake on GCP using Cloud Storage and BigQuery
Analytics Vidhya
FEBRUARY 25, 2023
The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.

Analytics Vidhya
FEBRUARY 25, 2023
The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.

DataKitchen
NOVEMBER 5, 2024
The Bronze layer is the initial landing zone for all incoming raw data, capturing it in its unprocessed, original form. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

ProjectPro
JUNE 6, 2025
Most of us have observed that data scientist is usually labeled the hottest job of the 21st century, but is it the only most desirable job? No, that is not the only job in the data world. Store the data in in Google Cloud Storage to ensure scalability and reliability. Data transformation and cleaning techniques.

ProjectPro
JUNE 6, 2025
However, the modern data ecosystem encompasses a mix of unstructured and semi-structured data—spanning text, images, videos, IoT streams, and more—these legacy systems fall short in terms of scalability, flexibility, and cost efficiency. That’s where data lakes come in.

ProjectPro
JUNE 6, 2025
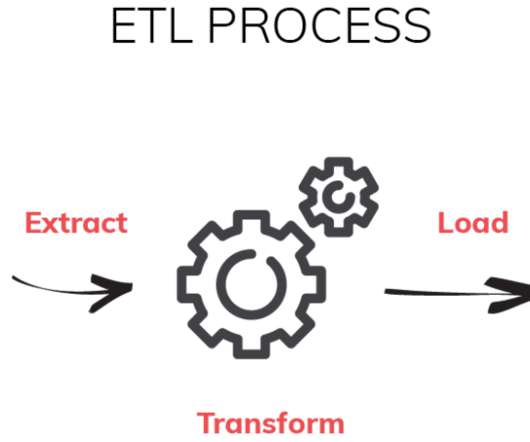
Think of the data integration process as building a giant library where all your data's scattered notebooks are organized into chapters. You define clear paths for data to flow, from extraction (gathering structured/unstructured data from different systems) to transformation (cleaning the raw data, processing the data, etc.)

ProjectPro
JUNE 6, 2025
Top 3 Azure Databricks Delta Lake Project Ideas for Practice The following are a few projects involving Delta lake: ETL on Movies data This project involves ingesting data from Kafka and building Medallion architecture ( bronze, silver, and gold layers) Data Lakehouse. What format does Delta lake use for storing data?

ProjectPro
JUNE 6, 2025
ELT involves three core stages- Extract- Importing data from the source server is the initial stage in this process. Load- The pipeline copies data from the source into the destination system, which could be a data warehouse or a data lake. Scalability ELT can be highly adaptable when using raw data.

Expert insights. Personalized for you.


































Let's personalize your content