
Setting up Data Lake on GCP using Cloud Storage and BigQuery
Analytics Vidhya
FEBRUARY 25, 2023
The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.

Analytics Vidhya
FEBRUARY 25, 2023
The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.

Snowflake
APRIL 2, 2025
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Edureka
APRIL 22, 2025
The alternative, however, provides more multi-cloud flexibility and strong performance on structured data. Its multi-cluster shared data architecture is one of its primary features. Additionally, it offers genuine multi-cloud flexibility by integrating easily with AWS, Azure, and GCP.
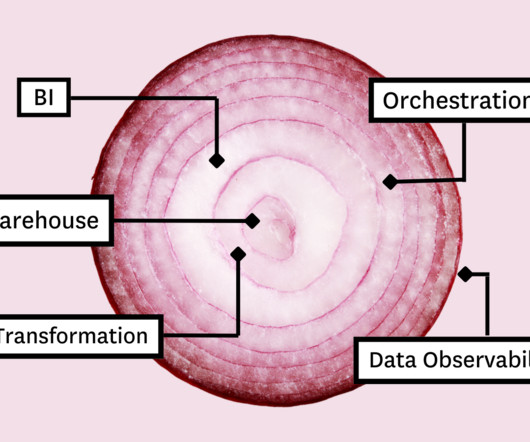
Monte Carlo
JULY 19, 2023
In this article, we’ll present you with the Five Layer Data Stack—a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.

Cloudera
JUNE 25, 2021
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structured data and files/unstructured data to the CDP cloud of their choice easily. Understanding Sentry permissions on CDH cluster.

Edureka
APRIL 14, 2025
It also supports various sources, including cloud storage, on-prem databases, and third-party platforms, making it highly versatile for hybrid ecosystems. However, it leans more toward transforming and presenting cleaned data rather than processing raw datasets.
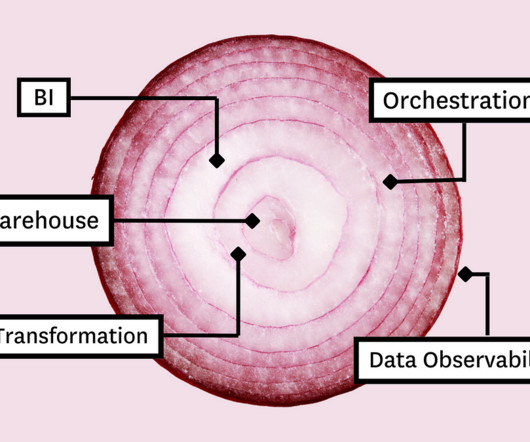
Towards Data Science
JULY 21, 2023
In this article, we’ll present you with the Five Layer Data Stack — a model for platform development consisting of five critical tools that will not only allow you to maximize impact but empower you to grow with the needs of your organization. Before you can model the data for your stakeholders, you need a place to collect and store it.

Expert insights. Personalized for you.


































Let's personalize your content