This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., Before we get started, let’s be clear…when using cloudstorage, it is usually not recommended to work with files that are particularly large. here , here , and here ). CPU cores and TCP connections).
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Adopting an Open Table Format architecture is becoming indispensable for modern data systems.
And that’s the target of today’s post — We’ll be developing a data pipeline using Apache Spark, Google CloudStorage, and Google Big Query (using the free tier) not sponsored. Google CloudStorage (GCS) is Google’s blob storage. Create a new bucket in the Google CloudStorage named censo-ensino-superior 4.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Faster compute: Iceberg's metadata layer is optimized for cloudstorage, allowing for advance file and partition pruning with minimal IO overhead.
Powered by Apache HBase and Apache Phoenix, COD ships out of the box with Cloudera Data Platform (CDP) in the public cloud. It’s also multi-cloud ready to meet your business where it is today, whether AWS, Microsoft Azure, or GCP. We tested for two cloudstorages, AWS S3 and Azure ABFS. runtime version.
What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems? What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems? Email hosts@dataengineeringpodcast.com ) with your story.
But one thing is for sure, tech enthusiasts like us will never stop hunting for the best free online cloudstorage platforms to upgrade our unlimited free cloudstorage game. What is CloudStorage? Cloudstorage provides you with cost-effective, scalable storage. What is the need for it?
This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs. By storing data in its native state in cloudstorage solutions such as AWS S3, Google CloudStorage, or Azure ADLS, the Bronze layer preserves the full fidelity of the data.
But before data can be transformed and served or shared, it must be ingested from source systems. Rather than streaming data from source into cloud object stores then copying it to Snowflake, data is ingested directly into a Snowflake table to reduce architectural complexity and reduce end-to-end latency. Why Snowpipe Streaming?
Further research We struggled to find more official information about how object storage is implemented and measured, so we decided to look at an object storagesystem that could be deployed locally called MinIO. This was something that the Cloud Carbon Footprint methodology already takes into account.
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a Data Lake implemented with cloudstorage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools. AWS Redshift, GCP Big Query, or Azure Synapse work well, too.
We jumped from HDFS to CloudStorage (S3, GCS) for storage and from Hadoop, Spark to Cloud warehouses (Redshift, BigQuery, Snowflake) for processing. When you are a data engineer you're getting paid to build systems that people can rely on. But there was a big problem: it was hard to manage. Something boring.
Object storage solutions like Amazon S3 or Google CloudStorage are perfect for this. This layer is also crucial for AI systems using Retrieval-Augmented Generation (RAG), where processed data serves as a knowledge base for large language models to generate more accurate, contextualized responses.
While cloud computing is pushing the boundaries of science and innovation into a new realm, it is also laying the foundation for a new wave of business start ups. 5 Reasons Your Startup Should Switch To CloudStorage Immediately 1) Cost-effective Probably the strongest argument in cloud’s favor I is the cost-effectiveness that it offers.
Event driven pipelines Lambda function to trigger spark jobs Setup and run Monitoring and logging Teardown Conclusion Further reading References Event driven pipelines Event driven systems represent a software design pattern where a logic is executed in response to an event.
Amazon Elastic File System (EFS) is a service that Amazon Web Services ( AWS ) provides. It is intended to deliver serverless, fully-elastic file storage that enables you to share data independently of capacity and performance. What features does AWS Elastic File System offer? What is Amazon EFS? Key features include: 1.
After the inspection stage, we leverage the cloud scaling functionality to slice the video into chunks for the encoding to expedite this computationally intensive process (more details in High Quality Video Encoding at Scale ) with parallel chunk encoding in multiple cloud instances. For write operations, those challenges do not apply.
What are the types of storage and data systems that you integrate with? How do the trends in cloudstorage and data systems influence the ways that you evolve the system? What are the types of storage and data systems that you integrate with?
Some data warehousing solutions such as appliances and engineered systems have attempted to overcome these problems, but with limited success. . Recently, cloud-native data warehouses changed the data warehousing and business intelligence landscape. Its existing data warehousing service is a 40-node system and is quite static.
Stream processing: data is continuously collected and processed and dispersed to downstream systems. This includes the use of intermediate topics on a persistent messaging system such as Kafka. Your electric consumption is collected during a month and then processed and billed at the end of that period.
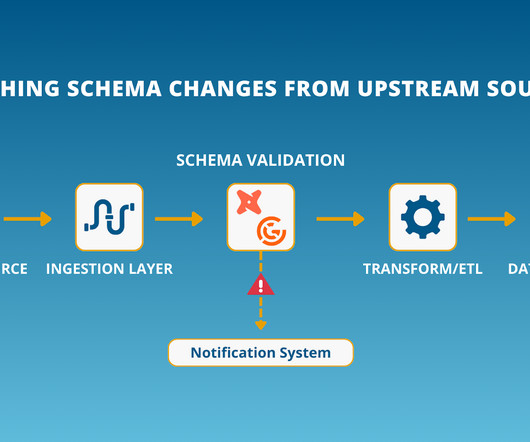
If youre done with quick fixes that dont hold up, its time to build a system using data validation techniques that actually workone that stops issues before they spiral. A last-minute schema check isnt proactiveits just more noise in an already chaotic system.
However, AI-assisted editing tools are transforming the systems that are capable of eliminating tough jobs from the editing process. AI systems can automate the bulk of this operation and produce complex and realistic animations, effects, and scenes in comparatively less time.
Some of the systems make data immutable, once ingested, to get around this issue – but real world data streams such as CDC streams have inserts, updates and deletes and not just inserts. Whether these are Elasticsearch’s data nodes or Apache Druid’s data servers or Apache Pinot’s real-time servers, the story is pretty much the same.
Links Alooma Convert Media Data Integration ESB (Enterprise Service Bus) Tibco Mulesoft ETL (Extract, Transform, Load) Informatica Microsoft SSIS OLAP Cube S3 Azure CloudStorage Snowflake DB Redshift BigQuery Salesforce Hubspot Zendesk Spark The Log: What every software engineer should know about real-time data’s unifying abstraction by Jay (..)
Your host is Tobias Macey and today I’m interviewing Anand Babu Periasamy about MinIO, the neutral, open source, enterprise grade object storagesystem. What benefits does object storage provide as compared to distributed file systems? Can you describe how MinIO is implemented and the overall system design?
Cybersecurity is a common domain for DataFlow deployments due to the need for timely access to data across systems, tools, and protocols. RK built some simple flows to pull streaming data into Google CloudStorage and Snowflake. Congratulations Vince! Runner up Ramakrishna Sanikommu was our runner up.
Android Local Train Ticketing System Developing an Android Local Train Ticketing System with Java, Android Studio, and SQLite. Developing a local train ticketing system for Android can be a challenging yet rewarding project idea for Software developer.
Designed for processing large data sets, Spark has been a popular solution, yet it is one that can be challenging to manage, especially for users who are new to big data processing or distributed systems. Batch Processing Pipelines : Large volumes of data can be processed on schedule using the tool.
Deliver the most relevant results Cortex Search is a fully managed service that includes integrated embedding generation and vector management, making it a critical component of enterprise-grade RAG systems. The size of each chunk directly impacts how well the system retrieves data. Striking the right balance is essential.
Should system resources such as CPU or system memory become constrained, this ops team is responsible to correct. Hardware (compute and storage) : As with PaaS data lakehouses, the CDP One data lakehouse resides in the cloud and uses virtualized compute. To the user, it is a serverless experience.
However, the hybrid cloud is not going away anytime soon. In fact, the hybrid cloud will likely become even more common as businesses move more of their workloads to the cloud. So what will be the future of cloudstorage and security? As a result, Cloud technology will soon necessitate advanced system thinking.
BigQuery separates storage and compute with Google’s Jupiter network in-between to utilize 1 Petabit/sec of total bisection bandwidth. The storagesystem is using Capacitor, a proprietary columnar storage format by Google for semi-structured data and the file system underneath is Colossus, the distributed file system by Google.
*For clarity, the scope of the current certification covers CDP-Private Cloud Base. Certification of CDP-Private Cloud Experiences will be considered in the future. The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms. Complete integration testing.
The Ranger Authorization Service (RAZ) is a new service added to help provide fine-grained access control (FGAC) for cloudstorage. RAZ for S3 and RAZ for ADLS introduce FGAC and Audit on CDP’s access to files and directories in cloudstorage making it consistent with the rest of the SDX data entities. Conclusion.
We recently completed a project with IMAX, where we learned that they had developed a way to simplify and optimize the process of integrating Google CloudStorage (GCS) with Bazel. rules_gcs is a Bazel ruleset that facilitates the downloading of files from Google CloudStorage. What is rules_gcs ?
Data storage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloudstoragesystems. What are the Different Storage Layers Available in Snowflake? They are flexible, secure, and provide exceptional performance.
But working with cloudstorage has often been a compromise. Enterprises started moving to the cloud expecting infinite scalability and simultaneous cost savings, but the reality has often turned out to be more nuanced. The introduction of ADLS Gen1 was exciting because it was cloudstorage that behaved like HDFS.
Look for AWS Cloud Practitioner Essentials Training online to learn the fundamentals of AWS Cloud Computing and become an expert in handling the AWS Cloud platform. Chef Chef is used to configure virtual systems and automate manual work in Cloud environments. and more 2.
The Security Angle If we take the security-forward perspective, on the other hand, we have to admit that the larger the quantities of data we have — particularly if there are multiple systems of storage or processes influencing the data — the larger the risk of data breach. This isn’t sustainable, though — not forever anyway.
We store photos and personal information on our computers and in the cloud. Cybersecurity is the practice of protecting computer systems and networks from unauthorized access or attack. Cybersecurity helps to protect our data and systems from these threats. Some of the most common cyberattacks include: 1.
see “data pipeline” Intro The problem of managing scheduled workflows and their assets is as old as the use of cron daemon in early Unix operating systems. The design of a cron job is simple, you take some system command, you pick the schedule to run it on and you are done. Manually constructed continuous delivery system.
You can use SELECT statements to query data of all sizes across numerous different systems. This course teaches general skills that apply to all of these systems, but the emphasis is on distributed SQL engines like Hive and Impala that can query extremely large datasets.
In terms of data analysis, as soon as the front-end visualization or BI tool starts accessing the data, the CDW Hive virtual warehouse will spin up cloud computing resources to combine the persisted historical data from the cloudstorage with the latest incremental data from Kafka into a transparent real-time view for the users.
Netflix Drive relies on a data store that will be the persistent storage layer for assets, and a metadata store which will provide a relevant mapping from the file system hierarchy to the data store entities. 2 , are the file system interface, the API interface, and the metadata and data stores.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content