This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Unstructureddata takes many forms in an organization. From a data engineering perspective that often means things like JSON files, audio or video recordings, images, etc. What are the types of storage and datasystems that you integrate with? Can you describe how the Aparavi platform is implemented?
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Though basic and easy to use, traditional table storage formats struggle to keep up. Schema Evolution Data structures are rarely static in fast-moving environments.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
*For clarity, the scope of the current certification covers CDP-Private Cloud Base. Certification of CDP-Private Cloud Experiences will be considered in the future. The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms. Complete integration testing.
In spite of diligent digital transformation efforts, most financial services institutions still support a loose patchwork of siloed systems and repositories. The top-line benefits of a hybrid data platform include: Cost efficiency. Simplified compliance. A phased approach to modernization.
Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
Data Ingestion Data ingestion refers to the process of importing data into a system or database for storage and analysis. This can involve extracting data from various sources, such as files, operational databases, APIs or IoT data, and transforming it into a format that is suitable for storage and analysis.
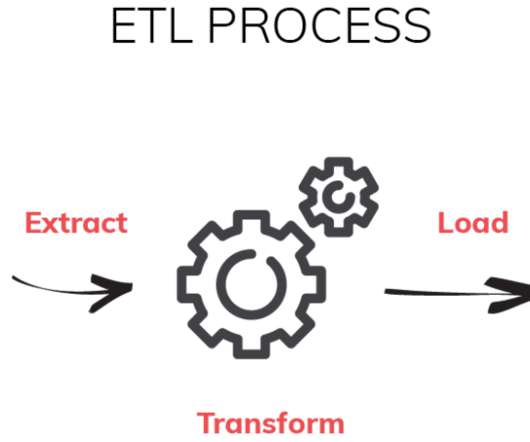
There are two main approaches : ETL (Extract, Transform, Load) ETL is the traditional methodextract data from sources, clean and structure it, then store it. Its great when data consistency is critical and compute resources are readily available. Data Lakes Data lakes store raw, unstructureddata.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Another important task is to evaluate the company’s hardware and software and identify if there is a need to replace old components and migrate data to a new system. Problem-solving skills.
Using big data, we are able to transform unstructureddata, such as customer reviews, into actionable insights, which enables businesses to better understand how and why customers prefer their products or services and to make improvements to their operations as quickly as is practically possible.
Organizations must focus on breaking down silos and integrating all relevant, critical data into on-premises or cloudstorage for AI model training and inference. Mainframe and IBM i systems remain critical parts of the modern data center and are vital to the success of these data initiatives.
This article will define in simple terms what a data warehouse is, how it’s different from a database, fundamentals of how they work, and an overview of today’s most popular data warehouses. What is a data warehouse? An ETL tool or API-based batch processing/streaming is used to pump all of this data into a data warehouse.
Most training pipelines and systems are designed to handle fairly small, sub-megapixel images. To store this data, hospitals are often equipped with on-premises infrastructure, more or less provided by the same manufacturer of the capture devices. Reading WSIs from Blob Storage The first basic challenge is to actually read the image.
Plus, we’ll explain how data engineers use Meltano, our DataOps platform, for efficient data management. What Is Data Engineering? Data engineering is the process of designing systems for collecting, storing, and analyzing large volumes of data. This is where data engineers come in.
Multi-model Databases Another innovative solution that supports many data models, including document, graph, and key-value stores, is multi-model databases. This enables businesses to utilize a single database system rather than several, streamlining data management and allowing the usage of several data models for various use cases.
Azure Data Factory (ADF) and Azure Synapse Analytics are some of the instrumental tools used when it comes to data integration and data transformation. Another element that can be identified in both services is the copy operation, with the help of which data can be transferred between different systems and formats.
Thus, clients can integrate their Customer Relationship Management (CRM) and Enterprise Resource Planning (ERP) systems with Azure and take their business operations to the next level. Apart from this, there should be adequate measures to safeguard this data from breaches and cyber-attacks.
BigQuery enables users to store data in tables, allowing them to quickly and easily access their data. It supports structured and unstructureddata, allowing users to work with various formats. BigQuery also supports many data sources, including Google CloudStorage, Google Drive, and Sheets.
Data engineering is a new and evolving field that will withstand the test of time and computing advances. Certified Azure Data Engineers are frequently hired by businesses to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
ETL was an advantage when we weren’t able to work with the size and complexity of raw data. With the advent of cloud computing, storing unstructureddata quickly without having to worry about storage or format is faster and cheaper. However, that is less and less the case. This is when ELT came in.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
Data Pipeline Tools AWS Data Pipeline Azure Data Pipeline Airflow Data Pipeline Learn to Create a Data Pipeline FAQs on Data Pipeline What is a Data Pipeline? In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline.
Source: Databricks Delta Lake is an open-source, file-based storage layer that adds reliability and functionality to existing data lakes built on Amazon S3, Google CloudStorage, Azure Data Lake Storage, Alibaba Cloud, HDFS ( Hadoop distributed file system), and others. Delta Lake integrations.
Whether you want to learn more about the benefits of real-time analytics or dive deeper into the most significant characteristics of a real-time analytics system, we’ll ensure you have a robust understanding of how real-time analytics move your business forward. Users can access this data on a dashboard, report, or another medium.
Everyone wants to leverage this technology to make their systems more reliable, robust, and therefore the best in the market. We all are aware of the wonders done by Data mining and Machine Learning. MB of data every second. By 2025, 200+ zettabytes of data will be in cloudstorage around the globe.
Recently, there’s been a lot of discussion around whether to go with open source or closed source solutions (the dialogue between Snowflake and Databricks’ marketing teams really brings this to light) when it comes to building your data platform.
Azure provides you with a multitude of tools and services, including: Virtual machines: It provides you with virtual machines that can be used to run applications and services on the cloud. Storage: With Azure, you get several storage options, including blob storage, file storage, and disk storage.
Modern CloudData Platforms The native capabilities of the cloud providers have been joined by third-party services to offload that data into separate less costly systems that are optimized for analysis of that data. Let’s take a closer look.
Many business owners and professionals are interested in harnessing the power locked in Big Data using Hadoop often pursue Big Data and Hadoop Training. What is Big Data? Big data is often denoted as three V’s: Volume, Variety and Velocity. Offers flexibility and faster data processing. Pricing : Free of cost.
Thus, as a learner, your goal should be to work on projects that help you explore structured and unstructureddata in different formats. Data Warehousing: Data warehousing utilizes and builds a warehouse for storing data. A data engineer interacts with this warehouse almost on an everyday basis.
Organizations can harness the power of the cloud, easily scaling resources up or down to meet their evolving data processing demands. Supports Structured and UnstructuredData: One of Azure Synapse's standout features is its versatility in handling a wide array of data types.
What are some popular use cases for cloud computing? Cloudstorage - Storage over the internet through a web interface turned out to be a boon. With the advent of cloudstorage, customers could only pay for the storage they used. Cloud consists of a shared pool of resources and systems.
Data Lake vs Data Warehouse - The Differences Before we closely analyse some of the key differences between a data lake and a data warehouse, it is important to have an in depth understanding of what a data warehouse and data lake is. Data Lake vs Data Warehouse - The Introduction What is a Data warehouse?
IoT examples are security systems, utilities and devices, entertainment, and health gadgets. . Organizations are experiencing a lack of skilled Cloud computing specialists due to the increase in the use of Cloud in current business models. . Real-world Example of Cloud Computing . What Is Cybersecurity? .
A Hadoop cluster is a group of computers called nodes that act as a single centralized system working on the same task. a client or edge node serves as a gateway between a Hadoop cluster and outer systems and applications. It loads data and grabs the results of the processing staying outside the master-slave hierarchy.
Data Description: You will use the Covid-19 dataset(COVID-19 Cases.csv) from data.world , for this project, which contains a few of the following attributes: people_positive_cases_count county_name case_type data_source Language Used: Python 3.7 Semi-structured Data: It is a combination of structured and unstructureddata.
Their models, data, and systems, curated for decades or centuries and fiercely protected, simply did not and could not factor in how a global pandemic would affect their customers. Using these forms of structured and unstructureddata can unlock new insights, both in isolation and in combination with each other.
Inspired by the human brain, Neuromorphic chips promise unparalleled energy efficiency and the ability to process unstructureddata locally on devices. The advancement in computing will expand AI’s role in autonomous systems and robotics.
Following that, we will examine the Microsoft Fabric Data Engineer Associate Microsoft Fabric Data Engineer Associate About the Certification This professional credential verifies your proficiency in implementing data engineering solutions using Microsoft’s unified analytics platform.
ETL (Extract, Transform, and Load) Pipeline involves data extraction from multiple sources like transaction databases, APIs, or other business systems, transforming it, and loading it into a cloud-hosted database or a clouddata warehouse for deeper analytics and business intelligence.
In this blog, we will explore the future of big data in business, its applications, and the technologies that will drive its evolution. What is Big Data? Big data refers to large amounts of data. The differentiation between data and big data becomes clear once we look at the methods of analyzing them.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content