This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A data lake is a centralized and scalable repository storing structured and unstructureddata. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Unlock the power of scalable cloudstorage with Azure Blob Storage! This Azure Blob Storage tutorial offers everything you need to know to get started with this scalable cloudstorage solution. By 2030, the global cloudstorage market is likely to be worth USD 490.8
Summary Unstructureddata takes many forms in an organization. From a data engineering perspective that often means things like JSON files, audio or video recordings, images, etc. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder.
According to the latest report, the global market for data warehousing is likely to reach $30 billion by 2025. It is becoming difficult for organizations to select the finest technology due to the growing rise of data warehousing solutions. With it's seamless connections to AWS and Azure , BigQuery Omni offers multi-cloud analytics.
Why Learn Cloud Computing Skills? The job market in cloud computing is growing every day at a rapid pace. A quick search on Linkedin shows there are over 30000 freshers jobs in Cloud Computing and over 60000 senior-level cloud computing job roles. What is Cloud Computing? Thus came in the picture, Cloud Computing.
Want to put your cloud computing skills to the test? Dive into these innovative cloud computing projects for big data professionals and learn to master the cloud! Cloud computing has revolutionized how we store, process, and analyze big data, making it an essential skill for professionals in data science and big data.
." - Matt Glickman, VP of Product Management at Databricks Data Warehouse and its Limitations Before the introduction of Big Data, organizations primarily used data warehouses to build their business reports. Lack of unstructureddata, less data volume, and lower data flow velocity made data warehouses considerably successful.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudData warehouses like Snowflake and Big Query already have a default time travel feature.
Read Time: 2 Minute, 30 Second For instance, Consider a scenario where we have unstructureddata in our cloudstorage. However, Unstructured I assume : PDF,JPEG,JPG,Images or PNG files. Therefore, As per the requirement, Business users wants to download the files from cloudstorage.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Data Lake Architecture- Core Foundations Data lake architecture is often built on scalable storage platforms like Hadoop Distributed File System (HDFS) or cloud services like Amazon S3, Azure Data Lake, or Google CloudStorage.
Skills of a Data Engineer Apart from the existing skills of an ETL developer, one must acquire the following additional skills to become a data engineer. Cloud Computing Every business will eventually need to move its data-related activities to the cloud. How to Transition from ETL Developer to Data Engineer?
Storage Layer: This is a centralized repository where all the data loaded into the data lake is stored. HDFS is a cost-effective solution for the storage layer since it supports storage and querying of both structured and unstructureddata. Is Hadoop a data lake or data warehouse?
Cloudera and Dell/EMC are continuing our long and successful partnership of developing shared storage solutions for analytic workloads running in hybrid cloud. . Since the inception of Cloudera Data Platform (CDP), Dell / EMC PowerScale and ECS have been highly requested solutions to be certified by Cloudera.
Think of the data integration process as building a giant library where all your data's scattered notebooks are organized into chapters. You define clear paths for data to flow, from extraction (gathering structured/unstructureddata from different systems) to transformation (cleaning the raw data, processing the data, etc.)
The result was Apache Iceberg, a modern table format built to handle the scale, performance, and flexibility demands of today’s cloud-native data architectures. Data Layer What are the main use cases for Apache Iceberg? Ensure strong data governance and auditability. Let us explore more about it. Iceberg Catalog 2.
With the global clouddata warehousing market likely to be worth $10.42 billion by 2026, clouddata warehousing is now more critical than ever. Clouddata warehouses offer significant benefits to organizations, including faster real-time insights, higher scalability, and lower overhead expenses.
Many Cloudera customers are making the transition from being completely on-prem to cloud by either backing up their data in the cloud, or running multi-functional analytics on CDP Public cloud in AWS or Azure. Configure the required ports to enable connectivity from CDH to CDP Public Cloud (see docs for details).
Storage And Persistence Layer Once processed, the data is stored in this layer. Stream processing engines often have in-memory storage for temporary data, while durable storage solutions like Apache Hadoop, Amazon S3, or Google CloudStorage serve as repositories for long-term storage of processed data.
Are you looking to choose the best clouddata warehouse for your next big data project? This blog presents a detailed comparison of two of the very famous cloud warehouses - Redshift vs. BigQuery - to help you pick the right solution for your data warehousing needs. billion by 2028 from $21.18
The Data Discovery and Exploration (DDE) template in CDP Data Hub was released as Tech Preview a few weeks ago. DDE is a new template flavor within CDP Data Hub in Cloudera’s public cloud deployment option (CDP PC). data best served through Apache Solr). data best served through Apache Solr).
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. It not only consumes more memory but also slackens data transfer.
Seamless Cloud Integration (BYOC) For teams already managing their cloud infrastructure, Phidata’s "Bring Your Own Cloud" (BYOC) feature allows seamless integration of their own cloud systems. It handles unstructureddata, integrates external APIs, and manages prompt engineering workflows.
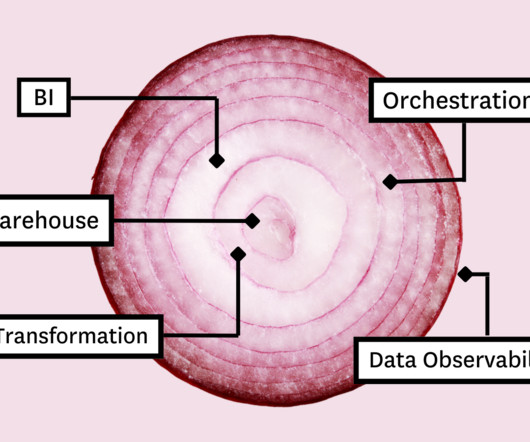
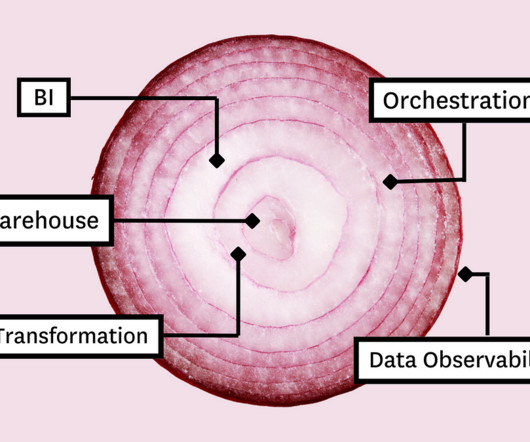
Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the data pipeline. Unlike ogres, however, the clouddata platform isn’t a fairy tale. Data transformation Okay, so your data needs to live in the cloud.
Data scientists, analysts, and line-of-business teams can use it to support business intelligence and other essential processes from this location. Extract, Load, Transform, or ELT refers to how a data pipeline duplicates data from a data source into a target location, such as a clouddata warehouse.
For example, Anaconda is a Python distribution tailored for data work. It includes a package manager and cloud hosting for sharing code notebooks and Python environments, which can help manage ETL workflows. Here are the critical components of an ETL data pipeline: Data Sources: Data sources are the starting point of an ETL pipeline.
Thankfully, cloud-based infrastructure is now an established solution which can help do this in a cost-effective way. As a simple solution, files can be stored on cloudstorage services, such as Azure Blob Storage or AWS S3, which can scale more easily than on-premises infrastructure. But as it turns out, we can’t use it.
Its powerful selection of tooling components combine to create a single synchronized and extensible data platform with each layer serving a unique function of the data pipeline. Unlike ogres, however, the clouddata platform isn’t a fairy tale. Data transformation Okay, so your data needs to live in the cloud.
A key area of focus for the symposium this year was the design and deployment of modern data platforms. Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. Ramsey International Modern Data Platform Architecture. What is a data mesh?
The characteristics of the data impact preparation costs, as well as storage and processing expenses: Structured data (like databases) is easier and cheaper to handle than unstructureddata (like text, images, or videos), as the latter requires more preprocessing. hr on Google Cloud, ~$3.06/hr
Beyond the interface, LlamaIndex allows you to choose from various storage backends to suit your needs. These backends include local file systems for on-premise storage or cloudstorage solutions like AWS S3 and Cloudflare R2 for scalability and remote access. This, in turn, will help you build impactful LLM applications.
Data preprocessing , including cleaning, normalization, and handling missing values, is thus critical in preparing data for AI models. A clear understanding of structured, semi-structured, and unstructureddata is essential to manage and process it effectively. As you move to deployment, plan carefully.
Data Analysis Tools- How does Big Data Analytics Benefit Businesses? Big data is much more than just a buzzword. 95 percent of companies agree that managing unstructureddata is challenging for their industry. Big data analysis tools are particularly useful in this scenario.
The stringent requirements imposed by regulatory compliance, coupled with the proprietary nature of most legacy systems, make it all but impossible to consolidate these resources onto a data platform hosted in the public cloud. Simplified compliance. Improved scalability and agility. Flexibility. A radically improved security posture.
The amount of data created is enormous, and with this pandemic forcing us to stay indoors, we are spending a lot of time over the internet generating massive amounts of data - In 2020, we created 1.7 MB of data every second. By 2025, 200+ zettabytes of data will be in cloudstorage around the globe.
The term "raw data" refers to a group of data (texts, photos, and database records in their raw form) that has not yet been fully processed and integrated into the system. Why is Data Wrangling important in Data Science Projects? Data wrangling is integral to any data science or data analytics project.
Hundreds of datasets are available from these two cloud services, so you may practise your analytical skills without having to scrape data from an API. Source: Use Stack Overflow Data for Analytic Purposes 4. We can clean the data, convert the data, and aggregate the data using dbt so that it is ready for analysis.
Redirect the user to the staged file in the cloudstorage service. So in case if we need to provide the access to unstructureddata for specific roles then BUILD_SCOPED_FILE_URL is being used w.r.t When users send a file URL to the REST API to access files, Snowflake performs the following actions: Authenticate the user.
With our new partnership and updated integration, Monte Carlo provides full, end-to-end coverage across data lake and lakehouse environments powered by Databricks. But remember that line from the introduction about the blurring line between data warehouses and data lakes? It works in both directions.
Banks, healthcare systems, and financial reporting often rely on ETL to maintain highly structured, trustworthy data from the start. ELT (Extract, Load, Transform) ELT flips the orderstoring raw data first and applying transformations later. Once youve figured out when to transform your data, the next question is how to move it.
Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. The data lakes store data from a wide variety of sources, including IoT devices, real-time social media streams, user data, and web application transactions.
Data Discovery: Users can find and use data more effectively because to Unity Catalog’s tagging and documentation features. Unified Governance: It offers a comprehensive governance framework by supporting notebooks, dashboards, files, machine learning models, and both organized and unstructureddata.
Why Learn Cloud Computing Skills? The job market in cloud computing is growing every day at a rapid pace. A quick search on Linkedin shows there are over 30000 freshers jobs in Cloud Computing and over 60000 senior-level cloud computing job roles. What is Cloud Computing? Thus came in the picture, Cloud Computing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content