This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Navigating the complexities of data engineering can be daunting, often leaving data engineers grappling with real-time dataingestion challenges. Our comprehensive guide will explore the real-time dataingestion process, enabling you to overcome these hurdles and transform your data into actionable insights.
To address this challenge, we are happy to announce the public preview of Snowpipe Streaming as the latest addition to our Snowflake ingestion offerings. As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. How does Snowpipe Streaming work?
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Looking for the ultimate guide on mastering Apache Kafka in 2024? The ultimate hands-on learning guide with secrets on how you can learn Kafka by doing. Discover the key resources to help you master the art of real-time data streaming and building robust data pipelines with Apache Kafka. Here it is!
Cloudera delivers an enterprise datacloud that enables companies to build end-to-end data pipelines for hybrid cloud, spanning edge devices to public or private cloud, with integrated security and governance underpinning it to protect customers data. The customer is a heavy user of Kafka for dataingestion.
Apache Airflow Project Ideas Build an ETL Pipeline with DBT, Snowflake and Airflow End-to-End ML Model Monitoring using Airflow and Docker AWS Snowflake Data Pipeline Example using Kinesis and Airflow 2. Apache Kafka offers a robust solution for permanent data storage in a distributed, durable, and fault-tolerant cluster.
Ingestdata more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
Table of Contents What are Data Engineering Tools? Top 10+ Tools For Data Engineers Worth Exploring in 2025 Cloud-Based Data Engineering Tools Data Engineering Tools in AWS Data Engineering Tools in Azure FAQs on Data Engineering Tools What are Data Engineering Tools?
In the early days, many companies simply used Apache Kafka ® for dataingestion into Hadoop or another data lake. However, Apache Kafka is more than just messaging. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js
After the launch of Cloudera DataFlow for the Public Cloud (CDF-PC) on AWS a few months ago, we are thrilled to announce that CDF-PC is now generally available on Microsoft Azure, allowing NiFi users on Azure to run their data flows in a cloud-native runtime. . The need for a cloud-native Apache NiFi service on Microsoft Azure.
A key challenge, however, is integrating devices and machines to process the data in real time and at scale. Apache Kafka ® and its surrounding ecosystem, which includes Kafka Connect, Kafka Streams, and KSQL, have become the technology of choice for integrating and processing these kinds of datasets. Example: Audi.
CDP Public Cloud is now available on Google Cloud. The addition of support for Google Cloud enables Cloudera to deliver on its promise to offer its enterprise data platform at a global scale. CDP Public Cloud is already available on Amazon Web Services and Microsoft Azure.
Data Lake Architecture- Core Foundations Data lake architecture is often built on scalable storage platforms like Hadoop Distributed File System (HDFS) or cloud services like Amazon S3, Azure Data Lake, or Google Cloud Storage. Tools like Apache Kafka or AWS Glue are typically used for seamless dataingestion.
Trains are an excellent source of streaming data—their movements around the network are an unbounded series of events. Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. As with any real system, the data has “character.”
Today’s customers have a growing need for a faster end to end dataingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
At the heart of every data-driven decision is a deceptively simple question: How do you get the right data to the right place at the right time? The growing field of dataingestion tools offers a range of answers, each with implications to ponder. Fivetran Image courtesy of Fivetran.
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI DataCloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like data warehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
Consequently, data engineers implement checkpoints so that no event is missed or processed twice. It not only consumes more memory but also slackens data transfer. Modern cloud-based data pipelines are agile and elastic to automatically scale compute and storage resources.
A dataingestion architecture is the technical blueprint that ensures that every pulse of your organization’s data ecosystem brings critical information to where it’s needed most. A typical dataingestion flow. Popular DataIngestion Tools Choosing the right ingestion technology is key to a successful architecture.
An end-to-end Data Science pipeline starts from business discussion to delivering the product to the customers. One of the key components of this pipeline is Dataingestion. It helps in integrating data from multiple sources such as IoT, SaaS, on-premises, etc., What is DataIngestion?
With the ability to handle streaming dataingestion rates of up to millions of events per second, Amazon Kinesis has become a popular choice for high-volume data processing applications. Ready to take your data streaming to the next level? For Kinesis Firehose, AWS charges based on the amount of dataingested.
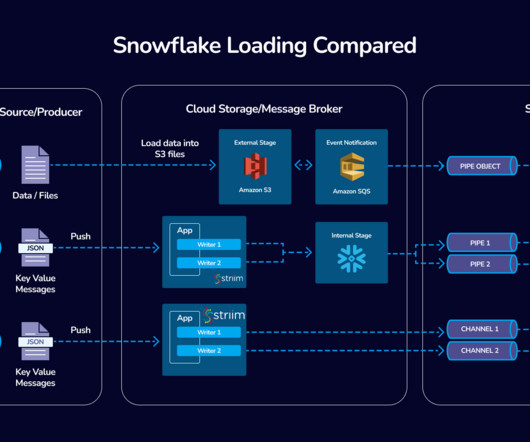
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Snowpipe Streaming: Unleashing Real-Time Data Integration and AI Snowpipe Streaming, when teamed up with Striim, is kind of like a superhero for real-time data needs.
In scenarios involving analytics on massive data streams, we’re often asked the maximum throughput and lowest data latency Rockset can achieve and how it stacks up to other databases. For this benchmark, we evaluated Rockset and Elasticsearch ingestion performance on throughput and data latency.
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI DataCloud by migrating their data warehousing workloads to the platform. The company migrated from its outdated Teradata appliance to the Snowflake AI DataCloud to resolve performance issues and meet growing data demands.
This is where real-time dataingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time dataingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.
As per the surveyors, Big data (35 percent), Cloud computing (39 percent), operating systems (33 percent), and the Internet of Things (31 percent) are all expected to be impacted by open source shortly. Following these statistics, big data is set to get bigger with the evolution of open-source projects.
The Snowflake DataCloud gives you the flexibility to build a modern architecture of choice to unlock value from your data. Snowflake was built from the ground up in the cloud. With Snowflake’s Kafka connector, the technology team can ingest tokenized data as JSON into tables as VARIANT.
Dataingestion is the process of collecting data from various sources and moving it to your data warehouse or lake for processing and analysis. It is the first step in modern data management workflows. Table of Contents What is DataIngestion? Decision making would be slower and less accurate.
In light of this, we’ll share an emerging machine-to-machine (M2M) architecture pattern in which MQTT, Apache Kafka ® , and Scylla all work together to provide an end-to-end IoT solution. Most IoT-based applications (both B2C and B2B) are typically built in the cloud as microservices and have similar characteristics. trillion by 2024.
Traditional data tools cannot handle this massive volume of complex data, so several unique Big Data software tools and architectural solutions have been developed to handle this task. Big Data Tools extract and process data from multiple data sources. Why Are Big Data Tools Valuable to Data Professionals?
A modern streaming architecture consists of critical components that provide dataingestion, security and governance, and real-time analytics. The three fundamental parts of the architecture are: Dataingestion that acquires the data from different streaming sources and orchestrates and augments the data from other sources.
Here is a list of some of the best data warehouse tools available to help organizations harness the power of their data: Amazon Redshift Amazon Redshift is a fully managed data warehousing service provided by Amazon Web Services (AWS) - a leading cloud computing platform. Practice makes a man perfect!
Elasticsearch was designed for log analytics where data is not frequently changing, posing additional challenges when dealing with transactional data. Rockset, on the other hand, is a cloud-native database, removing a lot of the tooling and overhead required to get data into the system.
Supporting open storage architectures The AI DataCloud is a single platform for processing and collaborating on data in a variety of formats, structures and storage locations, including data stored in open file and table formats. Getting dataingested now only takes a few clicks, and the data is encrypted.
Data scientists, analysts, and line-of-business teams can use it to support business intelligence and other essential processes from this location. Extract, Load, Transform, or ELT refers to how a data pipeline duplicates data from a data source into a target location, such as a clouddata warehouse.
CDF has pioneered as a data-in-motion platform since its inception at Hortonworks several years ago. Today, it offers the breadth of products for managing data-in-motion from the edge to the cloud (or the enterprise).
How to run dbt with BigQuery in GitHub Actions — When you're starting with dbt you don't need any orchestrator or dbt Cloud, a CI/CD do it for sure. Ensuring Data Consistency Across Replicas — Mixpanel details how they ensure that different zones Kafka consumers are writing the data in the same manner.
Source: N ifi.apache.org Apache NiFi is an open-source data integration tool designed to seamlessly and intuitively manage, automate, and distribute data flows. This powerful platform addresses the challenges of dataingestion, distribution, and transformation across diverse systems. What is NiFi vs Kafka?
Continuous, Extensible Data Processing: A robust data science pipeline ensures continuous, extensible data processing for real-time or near-real-time analysis, enabling rapid adaptation to evolving data needs and seamless integration of new data sources for dynamic insights and decision-making.
Skills of a Data Engineer Apart from the existing skills of an ETL developer, one must acquire the following additional skills to become a data engineer. Cloud Computing Every business will eventually need to move its data-related activities to the cloud. How to Transition from ETL Developer to Data Engineer?
In 2015, Cloudera became one of the first vendors to provide enterprise support for Apache Kafka, which marked the genesis of the Cloudera Stream Processing (CSP) offering. Today, CSP is powered by Apache Flink and Kafka and provides a complete, enterprise-grade stream management and stateful processing solution. Who is affected?
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content