This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Independently create data-driven solutions that are accurate and informative. Interact with the data scientists team and assist them in providing suitable datasets for analysis. Leverage various big data engineering tools and cloud service providing platforms to create data extractions and storage pipelines.
In 2024, the data engineering job market is flourishing, with roles like database administrators and architects projected to grow by 8% and salaries averaging $153,000 annually in the US (as per Glassdoor ). These trends underscore the growing demand and significance of data engineering in driving innovation across industries.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Another category of unstructured data that every business deals with is PDFs, Word documents, workstation backups, and countless other types of information. In this episode Rod Christensen shares the story behind Aparavi and how you can use it to cut costs and gain value for the long tail of your unstructured data.
Setting up the cloud to store data to ensure high availability is one of the most critical tasks for big data specialists. Due to this, knowledge of cloud computing platforms and tools is now essential for data engineers working with big data.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
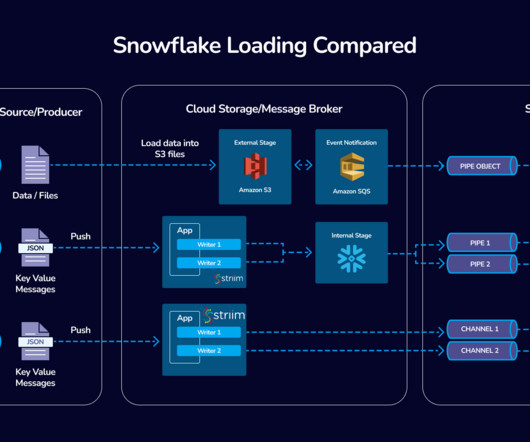
Introduction In the fast-evolving world of data integration, Striim’s collaboration with Snowflake stands as a beacon of innovation and efficiency. Snowpipe Streaming: Unleashing Real-Time Data Integration and AI Snowpipe Streaming, when teamed up with Striim, is kind of like a superhero for real-time data needs.
AWS (Amazon Web Services) is the leading global cloud platform, offering over 200 fully featured services from data centers worldwide. With over 1 million active enterprise customers and a thriving ecosystem of partners and third-party software products, AWS is at the forefront of cloud computing.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Experts predict that by 2025, the global big data and data engineering market will reach $125.89 billion, and those with skills in cloud-based ETL tools and distributed systems will be in the highest demand. As more organizations shift to the cloud, the demand for ETL engineers with expertise in these platforms is soaring.
In this episode Nick Schrock discusses the importance of orchestration and a central location for managing data systems, the road to Dagster’s 1.0 release, and the new features coming with Dagster Cloud’s general availability. Data teams are increasingly under pressure to deliver. and cloud to GA?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5% Why migrate?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
In this episode Purvi Shah, the VP of Enterprise Big Data Platforms at American Express, explains how they have invested in the cloud to power this visibility and the complex suite of integrations they have built and maintained across legacy and modern systems to make it possible. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Introduction Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time analytics is a challenge for many teams. Elasticsearch was designed for log analytics where data is not frequently changing, posing additional challenges when dealing with transactional data.
Offloading analytics from MongoDB establishes clear isolation between write-intensive and read-intensive operations. In most scenarios, MongoDB can be used as the primary data storage for write-only operations and as support for quick dataingestion. Monstache is also available as a sync daemon and a container.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
Consequently, data engineers implement checkpoints so that no event is missed or processed twice. It not only consumes more memory but also slackens data transfer. Modern cloud-based data pipelines are agile and elastic to automatically scale compute and storage resources. ADF does not store any data on its own.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. In fact, while only 3.5%
We built Rockset with the mission to make real-time analytics easy and affordable in the cloud. We put our users first and obsess about helping our users achieve speed, scale and simplicity in their modern real-time data stack (some of which I discuss in depth below). Change data capture streams. The problem?
Traditional data tools cannot handle this massive volume of complex data, so several unique Big Data software tools and architectural solutions have been developed to handle this task. Big Data Tools extract and process data from multiple data sources. Why Are Big Data Tools Valuable to Data Professionals?
Modern Snack-Sized Sales Training At ConveYour , we provide automated sales training via the cloud. Technical Challenges Our original data infrastructure was built around an on-premises MongoDB database that ingested and stored all user transaction data. First is its speed at dataingestion.
Types of AWS Databases AWS provides various database services, such as Relational Databases Non-Relational or NoSQL Databases Other Cloud Databases ( In-memory and Graph Databases). Relational Databases Relational databases form the backbone of modern data storage and management systems, powering various applications across industries.
There are three steps involved in the deployment of a big data model: DataIngestion: This is the first step in deploying a big data model - Dataingestion, i.e., extracting data from multiple data sources. When to use MapReduce with Big Data. For example – MongoDB.
Our goal is to help data scientists better manage their models deployments or work more effectively with their data engineering counterparts, ensuring their models are deployed and maintained in a robust and reliable way. AWS Glue: A fully managed data orchestrator service offered by Amazon Web Services (AWS).
Data Collection & Preprocessing Gather historical sales data, product demand reports, and macroeconomic indicators. Clean and preprocess raw data, handle missing values and seasonality trends. Data Collection & Preprocessing Aggregate historical sales, suppliers, and warehouse raw data.
As you’ll see by taking a look at this data pipeline example, the complexity and design of a pipeline varies depending on intended use. For instance, Macy’s streams change data from on-premises databases to Google Cloud. Another excellent data pipeline example is American Airlines’ work with Striim.
A loose schema allows for some data structure flexibility while maintaining a general organization. Semi-structured data is typically stored in NoSQL databases, such as MongoDB, Cassandra, and Couchbase, following hierarchical or graph data models. MongoDB, Cassandra), and big data processing frameworks (e.g.,
Big Data analytics encompasses the processes of collecting, processing, filtering/cleansing, and analyzing extensive datasets so that organizations can use them to develop, grow, and produce better products. Big Data analytics processes and tools. Dataingestion. Data storage and processing.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content