This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you’re still relying on manual processes to match, merge, and resolve data issues, then you’re spending too much time fixing errors and not enough time acting on insights. The Suite’s solution AI-powered match and merge, and metadata-driven automation.
These tools can be called by LLM systems to learn about your data and metadata. Remember, as with any AI workflows, to make sure that you are taking appropriate caution in terms of giving these access to production systems and data. No - there is functionality for both dbt Cloud and dbt Core users included in the MCP.
This growth is due to the increasing adoption of cloud-based data integration solutions such as Azure Data Factory. If you have heard about cloud computing , you would have heard about Microsoft Azure as one of the leading cloud service providers in the world, along with AWS and Google Cloud.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. How can we interoperate between the data domains ? How do we govern all these data products and domains ? It will be illustrated with our technical choices and the services we are using in the Google Cloud Platform.
Open Source Data Pipeline Tools Open-source data pipeline tools are pivotal in data engineering, offering organizations flexible and scalable solutions for managing the end-to-end dataworkflow. Pros of Google Cloud Dataflow Seamlessly processes both stream and batch data.
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked data technologies provide a means of tightly coupling metadata with raw information. Linked data technologies provide a means of tightly coupling metadata with raw information.
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your dataworkflows. Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to data management. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. Data lakes are notoriously complex. Materialize]([link] You shouldn't have to throw away the database to build with fast-changing data.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
AWS Data Pipeline AWS Data Pipeline is a cloud-based service by Amazon Web Services (AWS) that simplifies the orchestration of dataworkflows. It offers pre-built connectors for various AWS services, allowing users to seamlessly automate data movement and processing tasks within the AWS ecosystem.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud.
Thanks to its strong integration capabilities, Python works smoothly with cloud platforms, relational SQL databases, and modern orchestration tools. This makes Python a natural fit for ETL workflows across both fast-moving startups and large-scale enterprise data teams. What does the Spotify ETL Pipeline do?
Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud. Prophecy provides an easy-to-use visual interface to design & deploy data pipelines on Apache Spark & Apache Airflow. You can observe your pipelines with built in metadata search and column level lineage.
It builds your customer data warehouse and your identity graph on your data warehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. Their SDKs and plugins make event streaming easy, and their integrations with cloud applications like Salesforce and ZenDesk help you go beyond event streaming.
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps.
Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadata management , to be precise.
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
The Unity Catalog is Databricks governance solution which integrates with Databricks workspaces and provides a centralized platform for managing metadata, data access, and security. Improved Data Discovery The tagging and documentation features in Unity Catalog facilitate better data discovery.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Among solutions facilitation data management are. Apache Hadoop ecosystem.
It facilitates data synchronisation, replication, real-time analytics, and event-driven processing, empowering data-driven decision-making and operational efficiency. These additional columns store metadata like timestamps, user IDs, and change types, ensuring granular change tracking and auditability.
dbt Cloud v1.1.36 - v1.1.37 Changelog + docs located here. The new model timing dashboard in the run detail page helps you quickly assess job composition, order, and duration to optimize your workflows and cut costs? The Model Timing tab in dbt Cloud highlights models taking particularly long to run. Want to know why? (or
One is data at rest, for example in a data lake, warehouse, or cloud storage and from there they can do analytics on this data and that is predominantly around what has already happened or around how to prevent something from happening in the future.
Joel commentary - As someone who has been juggling the dbt Cloud CLI alongside dbt Core for the last couple of years, I cannot overstate how thrilled I am by this.) Obviously there's additional cloud-backed services necessary to deliver platform-specific features, such as State-Aware Orchestration. These are Apache 2.0-licensed
Disruption slows as cloud and nonrelational technology take their place beside traditional approaches , the leaders extend their lead, and distributed data approaches solidify their place as a best practice for DMSA.” Cloudera believes disruption persists around multi-cloud. Why multi-cloud?
At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files. Table formats incorporate aspects like columns, rows, data types, and relationships, but can also include information about the structure of the data itself.
Editor’s Note: The current state of the Data Catalog The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. We saw in the Data Catalog poll how far it has to go to be helpful and active within a dataworkflow.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. So, why is data orchestration a big deal? Agility and Adaptability: As businesses grow and evolve, their data needs change.
Power BI Microsoft’s Power BI is a business analytics tool that offers interactive data visualization features and business intelligence capabilities. It integrates with various tabular data sources, including Excel, SQL Server, and cloud services, allowing users to create detailed reports and dashboards.
Disadvantages of a data lake are: Can easily become a data swamp data has no versioning Same data with incompatible schemas is a problem without versioning Has no metadata associated It is difficult to join the dataData warehouse stores processed data, mostly structured data.
DataOps tools should provide a comprehensive data cataloging solution that allows organizations to create a centralized repository of their data assets, complete with metadata, data lineage information, and data samples. Genie manages and allocates resources for big data jobs.
The Basics How Azure Data Factory Works: Quick Summary Top Features of Azure Data Factory Key Components of Azure Data Factory Azure Data Factory Data Migration: Overview Azure Data Factory: Top Use Cases FAQs Conclusion What is Azure Data Factory?
As the volume and complexity of data continue to grow, organizations seek faster, more efficient, and cost-effective ways to manage and analyze data. In recent years, cloud-based data warehouses have revolutionized data processing with their advanced massively parallel processing (MPP) capabilities and SQL support.
Why Should You Get an Azure Data Engineer Certification? Becoming an Azure data engineer allows you to seamlessly blend the roles of a data analyst and a data scientist. One of the pivotal responsibilities is managing dataworkflows and pipelines, a core aspect of a data engineer's role.
One of the key elements of Azure Data Factory that permits data integration between various network environments is Integration Runtime. It offers the infrastructure needed to transfer data safely between cloud and on-site data storage. The three primary varieties are Azure, Azure-SSIS, and Self-hosted.
In the data world, this disruption manifested in the form of cloud computing with technologies such as Redshift, Snowflake, and Spark. When issues arise, there’s no need to mine and transfer diagnostic metadata or switch between tools and interfaces. Second, it enhances governance and security.
Follow Ravit on LinkedIn 5) Priya Krishnan Head of Product Management, Data and AI at IBM Priya is an innovative, customer-focused, data-driven product executive with over 16 years of experience in global product management, strategy, and GTM roles to commercialize and monetize in-demand enterprise solutions.
Here’s how Prefect , Series B startup and creator of the popular data orchestration tool, harnessed the power of data observability to preserve headcount, improve data quality and reduce time to detection and resolution for data incidents. This left Dylan’s team with a gap to fill.
Data pipeline architecture typically consisted of hardcoded pipelines that cleaned, normalized, and transformed the data prior to loading into a database using an ETL pattern. With cost and physical compute/storage limitations largely lifted, data engineers started to optimize data pipeline architecture for speed and agility.
Here’s how Gartner officially defines the category of data observability tools: “Data observability tools are software applications that enable organizations to understand the state and health of their data, data pipelines, data landscapes, data infrastructures, and the financial operational cost of the data across distributed environments.
Accessible via a unified API, these new features enhance search relevance and are available on Elastic Cloud. The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















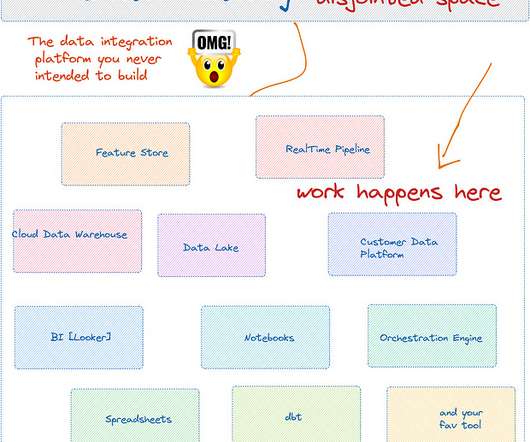


















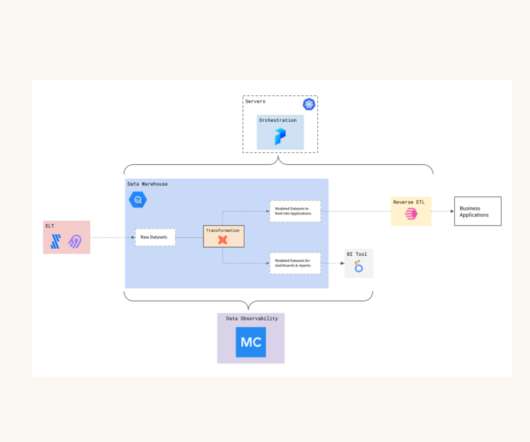









Let's personalize your content