This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Can you describe your experiences with Kafka? What are the operational challenges that you have had to overcome while working with Kafka? With Materialize, you can!
Introducing fully managed Apache Kafka® + Flink for the most robust, cloud-native data streaming platform with stream processing, integration, and streaming analytics in one.
In a previous two-part series , we dived into Uber’s multi-year project to move onto the cloud , away from operating its own data centers. But there’s no “one size fits all” strategy when it comes to deciding the right balance between utilizing the cloud and operating your infrastructure on-premises.
I spoke with Jark Wu , who leads the Fluss and Flink SQL team at Alibaba Cloud, to understand its origins and potential. It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow.
Kafka is horizontally scalable, but it's not enough. So we made Confluent Cloud 10x more elastic - 10x faster to scale up to GB/s or down to zero, easier to use, and cost-effective.
Open Source tools helped me switch to the cloud world a lot. The managed cloud services often share the same fundamentals as their Open alternatives. Today I'll focus on these differences for Amazon Kinesis service and Apache Kafka ecosystem. However, there is always something different.
As part of this, we are also supporting Snowpipe Streaming as an ingestion method for our Snowflake Connector for Kafka. Now we are able to ingest our data in near real time directly from Kafka topics to a Snowflake table, drastically reducing the cost of ingestion and improving our SLA from 15 minutes to within 60 seconds.
We are excited to announce the preview release of the fully managed Snowflake sink connector in Confluent Cloud, our fully managed event streaming service based on Apache Kafka®. Our managed […].
What we’ve done to evolve from cloudKafka to Confluent Cloud, a data streaming platform that’s 10X better than Kafka in elasticity, storage, resiliency, and more.
Extensive out-of-the-box functionality, a large user community, and up-to-date, cloud-native features make Spring and its libraries a strong option for anchoring your Apache Kafka® and Confluent Cloud based microservices architecture. […].
Within a few minutes, you provision a fully managed Apache Kafka® cluster […]. Imagine your team wants to design a data streaming architecture and you’re in charge of creating the prototype.
Less than six months ago, we announced support for Microsoft Azure in Confluent Cloud, which allows developers using Azure as a public cloud to build event streaming applications with Apache […].
Cloudera delivers an enterprise data cloud that enables companies to build end-to-end data pipelines for hybrid cloud, spanning edge devices to public or private cloud, with integrated security and governance underpinning it to protect customers data. Support Kafka connectivity to HDFS, AWS S3 and Kafka Streams.
At Zendesk, Apache Kafka® is one of our foundational services for distributing events among different internal systems. We have pods, which can be thought of as isolated cloud environments where […].
If you are taking your first steps with Apache Kafka®, looking at a test environment for your client application, or building a Kafka demo, there are two “easy button” paths […].
Low utilization and operational complexity dramatically increases Kafka costs, so we reinvented Kafka as a cloud-native and complete service to reduce costs for thousands of businesses at any scale.
Confluent has acquired WarpStream, an innovative Kafka-compatible streaming solution. Read the full statement by Jay Kreps, co-founder and CEO of Confluent.
We are thrilled to announce that Cloudera has acquired Eventador , a provider of cloud-native services for enterprise-grade stream processing. The DataFlow platform has established a leading position in the data streaming market by unlocking the combined value and synergies of Apache NiFi, Apache Kafka and Apache Flink.
At DoorDash, we rely on message queue systems based on Kafka to handle billions of real-time events. We will delve here into how we set up multi-tenancy with a messaging queue system based on Kafka. In Kafka, a test tenant processing production event can cause data inconsistencies, including outages and other incidents.
This is the third month of Project Metamorphosis, where we discuss new features in Confluent’s offerings that bring together event streams and the best characteristics of modern cloud data systems. […].
The cloud opens up exciting new opportunities for information gathering, analysis, and sharing that can make every organization’s products and services better. Thanks to the cloud and its decentralized nature, […].
Serverless offerings in the cloud are a favorite among software engineers—a prime example are object stores such as AWS S3. For the system designer, however, it is an engineering challenge […].
Confluent Cloud is now 10x faster than Apache Kafka. Read our latency benchmarking results, the innovations behind-the-scenes, and the lessons we learned.
At Confluent, we focus on the holy trinity of performance, price, and availability, with the goal of delivering a similar performance envelope for all workloads across all supported cloud providers. […].
The distributed architecture of Apache Kafka® can cause the operational burden of managing it to quickly become a limiting factor for adoption and developer agility. For this reason, it is […].
Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. 6 Spark streaming is a standalone framework.
With Snowpipe for Apache Kafka (public preview soon in AWS and Microsoft Azure), a “pull” mechanism, rather than the existing “push” connector, allows you to extract and ingest Apache Kafka events into your Snowflake account directly without hosting your own Kafka Connect cluster.
We also discuss the various systems using Kafka’s protocol. Confluent has never shied away from saying Kafka is “easy,” and I disagree. During the Kafka Summit London Keynote, the speakers said “easy” 17 times; in the Kafka Summit Bangalore Keynote, they said it 18 times. Using Confluent Cloud?
With billions of Internet of Things (IoT) devices, achieving real-time interoperability has become a major challenge. Together, Confluent, Waterstream, and MQTT are accelerating Industry 4.0 with new Industrial IoT (IIoT) […].
Although the Faust library aims to bring Kafka Streaming ideas into the Python ecosystem, it may pose challenges in terms of ease of use. Lastly, I share my experience implementing a similar pipeline on the Google Cloud Platform. A table is a distributed in-memory dictionary, backed by a Kafka changelog topic.
DoorDash’s Engineering teams revamped Kafka Topic creation by replacing a Terraform/Atlantis based approach with an in-house API, Infra Service. DoorDash’s Real-Time Streaming Platform, or RTSP, team is under the Data Platform organization and manages over 2,500 Kafka Topics across five clusters. Built atop Prometheus.
With the launch of CDP Public Cloud 7.2.14, Cloudera Streams Messaging for Data Hub deployments has gotten some powerful new features! In this release , the Streams Messaging templates in Data Hub will come with Apache Kafka 2.8 Kafka & Cruise Control Updates. Kafka Updates: Deployments with Kafka 2.5
This article show how you can offload data from on-premises transactional (OLTP) databases to cloud-based datastores, including Snowflake and Amazon S3 with Athena. I’m also going to take the opportunity […].
After the launch of Cloudera DataFlow for the Public Cloud (CDF-PC) on AWS a few months ago, we are thrilled to announce that CDF-PC is now generally available on Microsoft Azure, allowing NiFi users on Azure to run their data flows in a cloud-native runtime. . The need for a cloud-native Apache NiFi service on Microsoft Azure.
LiveStreams is a YouTube show about Confluent, real-time data streaming, and related technologies that help you maximize data in motion on any cloud. Every episode of LiveStreams will teach you […].
Last year, Confluent announced support for Infinite Storage, which fundamentally changes data retention in Apache Kafka® by allowing […]. It’s about maintaining the right data even when no one is watching.
With the release of CDP Private Cloud (PvC) Base 7.1.7, Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafka metadata and metadata lineage in the Atlas UI. Deep Dive 2: Atlas / Kafka integration. Deep Dive 1: Impala Row filtering.
A few weeks ago when we talked about our new fundraising, we also announced we’d be kicking off Project Metamorphosis. What is Project Metamorphosis? Let me try to explain. I […].
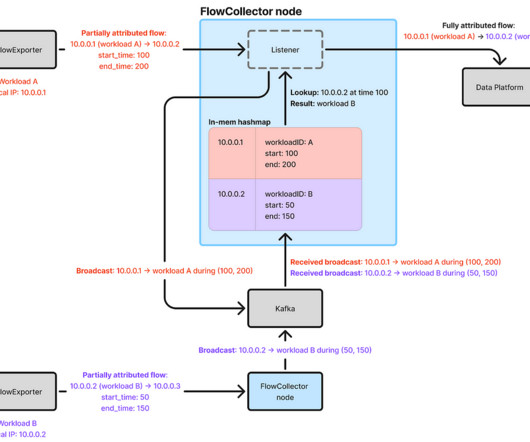
In cloud environments, IP addresses are reassigned to different workloads as workload instances are created and terminated, so IP addresses alone cannot provide insights on which workloads are communicating. We implemented a broadcasting mechanism using Kafka, where each node publishes learned time ranges to all other nodes.
How to elastically scale Kafka clusters from 0 to 100 MB/s and back with automatic cluster resizing, data rebalancing, real-time consumption optimization, and monitoring in seconds.
Are you ready to turbo-charge your data flows on the cloud for maximum speed and efficiency? Deploy, manage and monitor your standard NiFi flows running on-premises or on CDP Data Hub into cloud-native flows running on Kubernetes clusters on AWS. . NEW Cloudera DataFlow for the Public Cloud.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content