

Getting started with the MongoDB Connector for Apache Kafka and MongoDB
Confluent
JULY 17, 2019
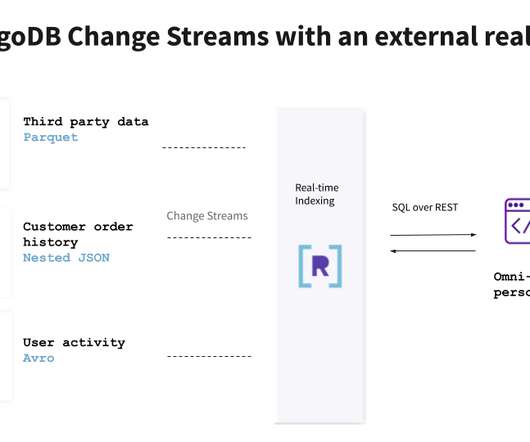
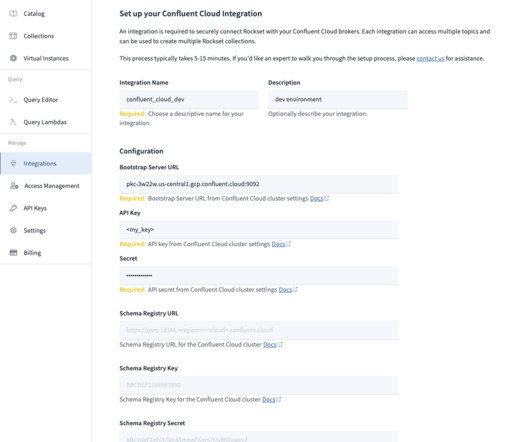
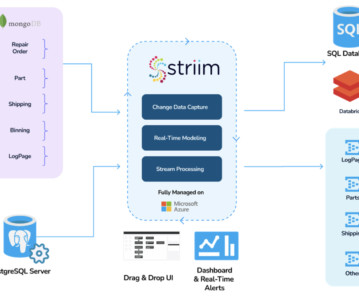
Together, MongoDB and Apache Kafka ® make up the heart of many modern data architectures today. Integrating Kafka with external systems like MongoDB is best done though the use of Kafka Connect. The official MongoDB Connector for Apache Kafka is developed and supported by MongoDB engineers.









































Let's personalize your content