This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NoSQL databases are the new-age solutions to distributed unstructured data storage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies. Table of Contents HBase vs. Cassandra - What’s the Difference?
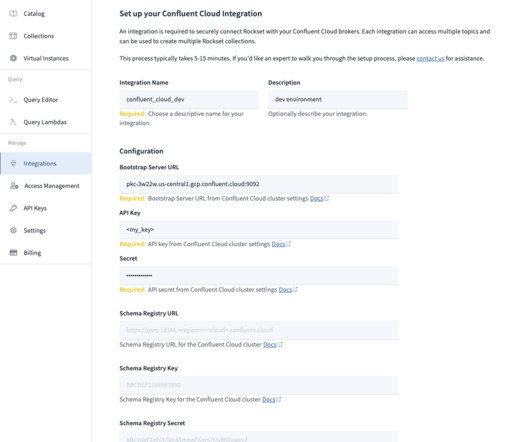
As a distributed system for collecting, storing, and processing data at scale, Apache Kafka ® comes with its own deployment complexities. To simplify all of this, different providers have emerged to offer Apache Kafka as a managed service. Before Confluent Cloud was announced , a managed service for Apache Kafka did not exist.
Why Learn Cloud Computing Skills? The job market in cloud computing is growing every day at a rapid pace. A quick search on Linkedin shows there are over 30000 freshers jobs in Cloud Computing and over 60000 senior-level cloud computing job roles. What is Cloud Computing? Thus came in the picture, Cloud Computing.
Top 10+ Tools For Data Engineers Worth Exploring in 2025 Cloud-Based Data Engineering Tools Data Engineering Tools in AWS Data Engineering Tools in Azure FAQs on Data Engineering Tools What are Data Engineering Tools? Database tools/frameworks like SQL, NoSQL , etc., Table of Contents What are Data Engineering Tools?
On September 24, 2019, Cloudera launched CDP Public Cloud (CDP-PC) as the first step in delivering the industry’s first Enterprise Data Cloud. Over the past year, we’ve not only added Azure as a supported cloud platform, but we have improved the orginal services while growing the CDP-PC family significantly: Improved Services.
Cloud computing skills, especially in Microsoft Azure, SQL , Python , and expertise in big data technologies like Apache Spark and Hadoop, are highly sought after. This project builds a comprehensive ETL and analytics pipeline, from ingestion to visualization, using Google Cloud Platform. Interactive dashboards creation in Looker.
Cloud is one of the key drivers for innovation. But to perform all this experimentation; companies cannot wait weeks or even months for IT to get them the appropriate infrastructure so they can start innovating, hence why cloud computing is becoming a standard for new developments. But cloud alone doesn’t solve all the problems.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. In this article, we’ll explain why businesses choose Kafka and what problems they face when using it. What is Kafka?
These collectors send the data to a central location, typically a message broker like Kafka. You can use data loading tools like Sqoop or Flume to transfer the data from Kafka to HDFS. Data Processing In this step, the collected data is processed in real-time to clean, transform, and enhance it.
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
This layer should support both SQL and NoSQL queries. Kafka streams, consisting of 500,000 events per second, get ingested into Upsolver and stored in AWS S3. It is also possible to use Snowflake on data stored in cloud storage from Amazon S3 or Azure Data lake for data analytics and transformation.
An ETL developer should be familiar with SQL/NoSQL databases and data mapping to understand data storage requirements and design warehouse layout. Cloud Computing Every business will eventually need to move its data-related activities to the cloud. And data engineers will likely gain the responsibility for the entire process.
In light of this, we’ll share an emerging machine-to-machine (M2M) architecture pattern in which MQTT, Apache Kafka ® , and Scylla all work together to provide an end-to-end IoT solution. Most IoT-based applications (both B2C and B2B) are typically built in the cloud as microservices and have similar characteristics. trillion by 2024.
They include relational databases like Amazon RDS for MySQL, PostgreSQL, and Oracle and NoSQL databases like Amazon DynamoDB. Database Variety: AWS provides multiple database options such as Aurora (relational), DynamoDB (NoSQL), and ElastiCache (in-memory), letting startups choose the best-fit tech for their needs.
The advantage of gaining access to data from any device with the help of the internet has become possible because of cloud computing. The birth of cloud computing has been a boon for many individuals and the whole tech industry. Such exciting benefits of cloud computing have led to its rapid adoption by various companies.
As per the surveyors, Big data (35 percent), Cloud computing (39 percent), operating systems (33 percent), and the Internet of Things (31 percent) are all expected to be impacted by open source shortly. Apache Beam Source: Google Cloud Platform Apache Beam is an advanced unified programming open-source model launched in 2016.
Is timescale compatible with systems such as Amazon RDS or Google Cloud SQL? Is timescale compatible with systems such as Amazon RDS or Google Cloud SQL? How is Timescale implemented and how has the internal architecture evolved since you first started working on it? What impact has the 10.0 What impact has the 10.0
AWS Data Engineer Interview Questions and Answers Explore AWS-focused questions and answers in this segment, encompassing data warehouse, Redshift, Glue, and overall cloud architecture, providing a comprehensive understanding of AWS services crucial for Amazon Data Engineering roles. Are you a beginner looking for Hadoop projects?
Here is a list of some of the best data warehouse tools available to help organizations harness the power of their data: Amazon Redshift Amazon Redshift is a fully managed data warehousing service provided by Amazon Web Services (AWS) - a leading cloud computing platform. Practice makes a man perfect!
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers 2. Consolidate and develop hybrid architectures in the cloud and on-premises, combining conventional, NoSQL, and Big Data. How do you model a set of entities in a NoSQL database using an optimal technique?
We implemented the data engineering/processing pipeline inside Apache Kafka producers using Java, which was responsible for sending messages to specific topics. At the same time, it is essential to understand how to deal with non-tabular data with its different types, which we call NoSQL databases. What are data engineering skills?
NoSQL databases are the new-age solutions to distributed unstructured data storage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies. Table of Contents HBase vs. Cassandra - What’s the Difference?
Cloud-Enabled Elasticity and Agility: Cloud-enabled elasticity and agility in modern data pipelines allow for dynamic resource scaling, optimizing computational efficiency and cost-effectiveness, fostering rapid experimentation, and iterative model development. It offers high throughput and fault tolerance.
If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. NoSQL databases are designed for scalability and flexibility, making them well-suited for storing big data.
It’s also a unifying idea behind the larger set of technology trends we see today, such as machine learning, IoT, ubiquitous mobile connectivity, SaaS, and cloud computing. Apache Kafka ® and its uses. Kafka is at the heart of Euronext’s next-generation stock exchange platform , processing billions of trades in the European markets.
These Apache Spark projects are mostly into link prediction, cloud hosting, data analysis, and speech analysis. Data migration from legacy systems to the cloud is a major use case in organizations that have been into relational databases. Cloud deployment saves a lot of time, cost, and resources.
One very popular platform is Apache Kafka , a powerful open-source tool used by thousands of companies. But in all likelihood, Kafka doesn’t natively connect with the applications that contain your data. In a nutshell, CDC software mines the information stored in database logs and sends it to a streaming event handler like Kafka.
The profile service will publish the changes in profiles, including address changes to an Apache Kafka ® topic, and the quote service will subscribe to the updates from the profile changes topic, calculate a new quote if needed and publish the new quota to a Kafka topic so other services can subscribe to the updated quote event.
It points to best practices for anyone writing Kafka Connect connectors. In a nutshell, the document states that sources and sinks are verified as Gold if they’re functionally equivalent to Kafka Connect connectors. Over the years, we’ve since seen wide adoption of Kafka Connect.
Google Trends shows the large-scale demand and popularity of Big Data Engineer compared with other similar roles, such as IoT Engineer, AI Programmer, and Cloud Computing Engineer. Big Data Engineer identifies the internal and external data sources to gather valid data sets and deals with multiple cloud computing environments.
Based on the complexity of data, it can be moved to the storages such as cloud data warehouses or data lakes from where business intelligence tools can access it when needed. There are quite a few modern cloud-based solutions that typically include storage, compute, and client infrastructure components. NoSQL databases.
The top companies that hire data engineers are as follows: Amazon It is the largest e-commerce company in the US founded by Jeff Bezos in 1944 and is hailed as a cloud computing business giant. It is responsible for providing software, hardware, and cloud-based services. KafkaKafka is an open-source processing software platform.
Folks have definitely tried, and while Apache Kafka® has become the standard for event-driven architectures, it still struggles to replace your everyday PostgreSQL database instance in the modern application stack. Confluent Cloud is also a great choice for storing real-time CDC events.
For input streams receiving data through networks such as Kafka , Flume, and others, the default persistence level setting is configured to achieve data replication on two nodes to achieve fault tolerance. Spark can integrate with Apache Cassandra to process data stored in this NoSQL database.
Recommended Reading: Top 50 NLP Interview Questions and Answers 100 Kafka Interview Questions and Answers 20 Linear Regression Interview Questions and Answers 50 Cloud Computing Interview Questions and Answers HBase vs Cassandra-The Battle of the Best NoSQL Databases 3) Name few other popular column oriented databases like HBase.
Apache HBase , a noSQL database on top of HDFS, is designed to store huge tables, with millions of columns and billions of rows. Alternatively, you can opt for Apache Cassandra — one more noSQL database in the family. Just for reference, Spark Streaming and Kafka combo is used by. Some components of the Hadoop ecosystem.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – data lakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. In other words, they develop, maintain, and test Big Data solutions.
Such innovations include open-source initiatives, Cloud Computing, and huge data expansion. NoSQL – This alternative kind of data storage and processing is gaining popularity. The term “NoSQL” refers to technology that is not dependent on SQL, to put it simply.
Some basic real-world examples are: Relational, SQL database: e.g. Microsoft SQL Server Document-oriented database: MongoDB (classified as NoSQL) The Basics of Data Management, Data Manipulation and Data Modeling This learning path focuses on common data formats and interfaces. You’ll learn how to load, query, and process your data.
The contemporary world experiences a huge growth in cloud implementations, consequently leading to a rise in demand for data engineers and IT professionals who are well-equipped with a wide range of application and process expertise. This can be easier when you are using existing cloud services.
Highlight the Big Data Analytics Tools and Technologies You Know The world of analytics and data science is purely skills-based and there are ample skills and technologies like Hadoop, Spark, NoSQL, Python, R, Tableau, etc. that you need to learn to pursue a lucrative career in the industry.
These tools include both open-source and commercial options, as well as offerings from major cloud providers like AWS, Azure, and Google Cloud. Database management: Data engineers should be proficient in storing and managing data and working with different databases, including relational and NoSQL databases.
has expanded its analytical database support for Apache Hadoop and Spark integration and also to enhance Apache Kafka management pipeline. Using NoSQL alternative to hadoop for use cases that require data hubs, IoT and real time analytics can save time,money and reduce risk. To compete in a field of diverse data tools, Vertica 8.0
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content