This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Batch dataprocessing — historically known as ETL — is extremely challenging. In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. But how do we model this in a functional data warehouse without mutating data?
Since it takes so long to iterate on workflows, some ML engineers started to perform dataprocessing directly inside training jobs. This is what we commonly refer to as Last Mile DataProcessing. Last Mile processing can boost ML engineers’ velocity as they can write code in Python, directly using PyTorch.
Data Management A tutorial on how to use VDK to perform batch dataprocessing Photo by Mika Baumeister on Unsplash Versatile Data Ki t (VDK) is an open-source data ingestion and processing framework designed to simplify data management complexities.
Moreover, these steps can be combined in different ways, perhaps omitting some or changing the order of others, producing different dataprocessing pipelines tailored to a particular task at hand. Namely, dependencies are encoded in the types, allowing compile-time checking and serving as the code documentation.
The company says: “Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork. years ago, and it became the leading AI coding assistant almost overnight. It’s more a copilot.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. What are the techniques/technologies that teams might use to optimize or scale out their dataprocessing workflows? Can you describe what Bodo is and the story behind it?
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. web endpoints, data tables, AI models) used across Meta.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source Code: Stock and Twitter Data Extraction Using Python, Kafka, and Spark 2.
Snowflake AI & ML Studio for LLMs (private preview): Enable users of all technical levels to utilize AI with no-code development. Using Snowflake dataprocessing infrastructure, the service is kept up-to-date with the latest information by automating continuous refreshes as new documents are generated.
While Pandas is the library for dataprocessing in Python, it isn't really built for speed. Learn more about the new library, Modin, developed to distribute Pandas' computation to speedup your data prep.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Go to dataengineeringpodcast.com/oxylabs today and use code DEP25 to get your special discount on residential proxies.
How to improve the code quality of your dbt models with unit tests and TDD All you need to know to start unit testing your dbt SQL models Photo by Christin Hume on Unsplash If you are a data or analytics engineer, you are probably comfortable writing SQL models and testing for data quality with dbt tests. Kent Beck ?
It is a famous Scala-codeddataprocessing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time. Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011.
The company says: “Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork. years ago, and it became the leading AI coding assistant almost overnight. It’s more a copilot.
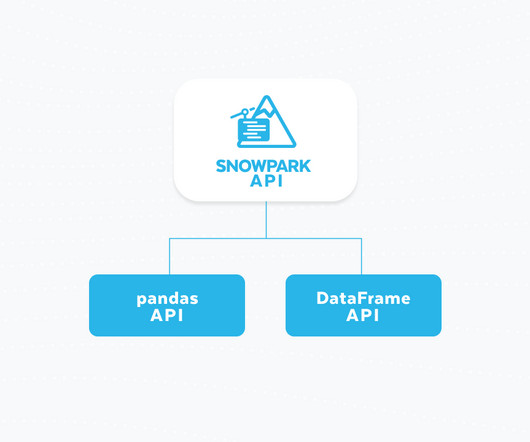
Snowflake customers are already harnessing the power of Python through Snowpark , a set of libraries and code execution environments that run Python and other programming languages next to your data in Snowflake. pandas is the go-to dataprocessing library for millions worldwide, including countless Snowflake users.
These scalable models can handle millions of records, enabling you to efficiently build high-performing NLP data pipelines. However, scaling LLM dataprocessing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex.
Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams. Atlan is a collaborative workspace for data-driven teams, like Github for engineering or Figma for design teams.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. Besides providing the end user with an instant answer in a preferred data visualization, LORE instantly learns from the users feedback.
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Search for "Code Commentst" in your podcast player or go to dataengineeringpodcast.com/codecomments today to subscribe.
Snowflake has embraced serverless since our founding in 2012, with customers providing their code to load, manage and query data and us taking care of the rest. They can easily access multiple code interfaces, including those for SQL and Python, and the Snowflake AI & ML Studio for no-code development.
Designed for processing large data sets, Spark has been a popular solution, yet it is one that can be challenging to manage, especially for users who are new to big dataprocessing or distributed systems. It provided us insights as to code compatibility and allowed us to better estimate our migration time.”
Key parts of data systems: 2.1. Data flow design 2.3. Dataprocessing design 2.5. Code organization 2.6. Data storage design 2.7. Introduction If you are trying to break into (or land a new) data engineering job, you will inevitably encounter a slew of data engineering tools. Introduction 2.
Code & Data 3. Using nested data types effectively 3.1. Using nested data types in dataprocessing 3.3.1. STRUCT enables more straightforward data schema and data access 3.3.2. Nested data types can be sorted 3.3.3. Introduction 2.
The Race For Data Quality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment.
Imagine entering a control room with complete control over your data ecosystem. You won’t have to deal with siloed systems, jump between tools, or write endless lines of code to make data useful. Welcome to Microsoft Fabric for Complete Novices, where no prior knowledge of coding or confusion is necessary.
Snowflake’s new Python API (GA soon) simplifies data pipelines and is readily available through pip install snowflake. Automate or code, the choice is yours. Finally, Tasks Backfill (PrPr) automates historical dataprocessing within Task Graphs. Interact with Snowflake objects directly in Python.
One of the main reasons this feature exists is just like with food samples, to give you “a taste” of the production quality ETL code that you could encounter inside the Netflix data ecosystem. " , country_code STRING COMMENT "Country code of the playback session." Let’s review the transformation steps below.
I like writing code and each time there is a dataprocessing job to write with some business logic I'm very happy. However, with time I've learned to appreciate the Open Source contributions enhancing my daily work. Mack library, the topic of this blog post, is one of those projects discovered recently.
Among the various tools available for data integration, Informatica and Talend stand out as popular choices, each with its strengths and capabilities. However, migrating from one platform to another can be a daunting task, especially when it involves converting existing code. Customizable: Tailors to specific project needs and rules.
Examples include “reduce dataprocessing time by 30%” or “minimize manual data entry errors by 50%.” It aims to streamline and automate data workflows, enhance collaboration and improve the agility of data teams. How effective are your current data workflows?
Cortex AI delivers exceptional quality across a wide range of unstructured dataprocessing tasks through models and specialized functions tailored for different tasks. In addition, Cortex AI Translate effectively handles noisy text, code-mixing, and extended context with coherence. Visit our documentation page to learn more.
The architecture of Microsoft Fabric is based on several essential elements that work together to simplify dataprocesses: 1. OneLake Data Lake OneLake provides a centralized data repository and is the fundamental storage layer of Microsoft Fabric. It is developed for real-time insights from streaming data.
Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. Today’s episode is Sponsored by Prophecy.io – the low-codedata engineering platform for the cloud. What are some of the utility features that you have found most helpful for dataprocessing?
To access real-time data, organizations are turning to stream processing. There are two main dataprocessing paradigms: batch processing and stream processing. Your electric consumption is collected during a month and then processed and billed at the end of that period.
Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities. The evaluation process includes over 4,000 automated tests, measuring the percentage of passing unit tests, similarity to known passing states, and token usage. Automate Airflow deploys with built-in CI/CD.
This relationship is particularly important in SAP® environments, where data and processes must work together seamlessly at scale. To achieve true transformation, you need an aligned approach where both processes and data management evolve together.
On the dataprocessing side there is Polars, a DataFrame library that could replace pandas. df = pl.read_csv("lost-objects-stations.csv", sep=";") Then you can use the same code as pandas to select the data (head, ["col"], etc.). With this release you can really mix Python and SQL code.
Commonly, purpose limitation can rely on “point checking” controls at the point of dataprocessing. This approach involves using simple if statements in code (“code assets”) or access control mechanisms for datasets (“data assets”) in data systems.
KAWA combines analytics, automation and AI agents to help enterprises build data apps and AI workflows quickly and achieve their digital transformation goals. It connects structured and unstructured databases across sources and uses a no-code UI or Python for advanced and predictive analytics.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. The article highlights Nuage 3.0's
To prevent this issue, we built verification in the post-processing stage to ensure that the user ID column in the data matches the identifier for the user whose logs we are generating. Finally, once content has been reviewed, it can be implemented in code using the renderers we described above.
Databricks Delta Live Tables (DLT) radically simplifies the development of the robust dataprocessing pipelines by decreasing the amount of code that data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content