

Automating product deprecation
Engineering at Meta
OCTOBER 17, 2023
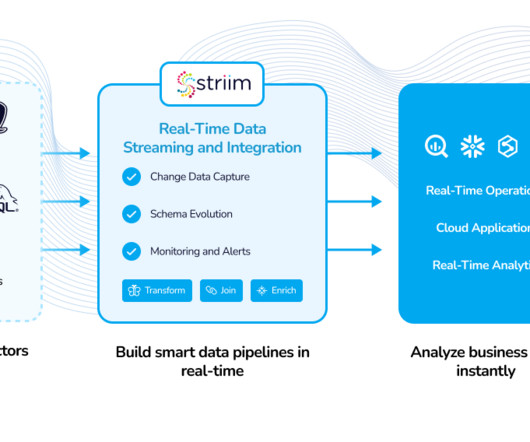
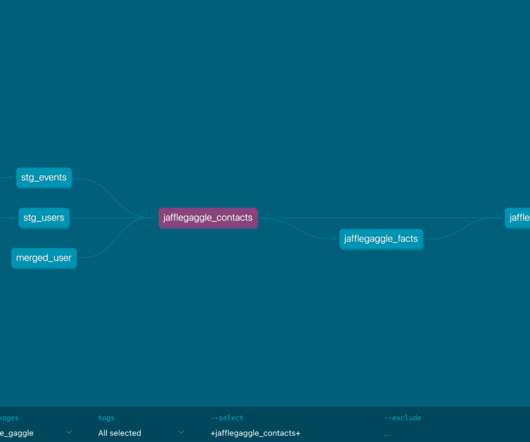
Systematic Code and Asset Removal Framework (SCARF) is Meta’s unused code and data deletion framework. So, how did we efficiently and safely remove all of the code and data related to Moments without adversely affecting Meta’s other products and services?

























Let's personalize your content