This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
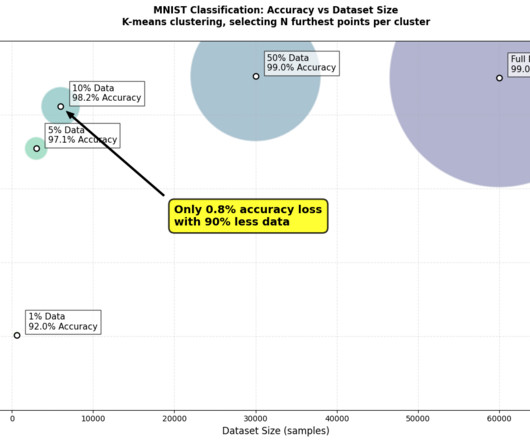
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. Full code and results available here onGitHub. Moving experiment configs to a YAML, automatically saving results to a file, and having o1 write my visualization code made life mucheasier. MNIST handwritten digit database.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team.
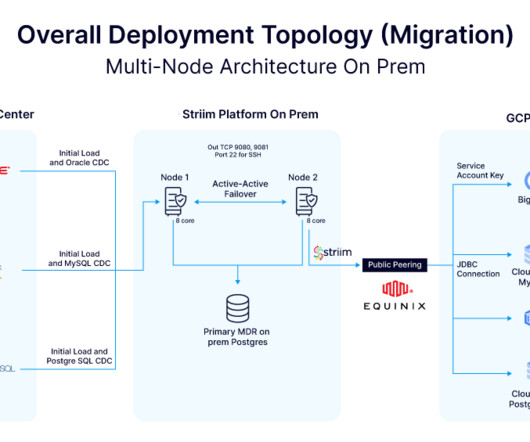
Known for its customer-centric approach and expansive product offerings, the company has maintained its leadership position in the industry for decades. After evaluating options, the retailer partnered with Striim to leverage its real-time data streaming and low-code/no-code integration capabilities.
I like testing people on their practical knowledge rather than artificial coding challenges. Adopting LLM in SQL-centric workflow is particularly interesting since companies increasingly try text-2-SQL to boost data usage. Log-as-the-Database (P2): Sending only write-ahead logs to the storage side upon transaction commit.
A decade ago, Picnic set out to reinvent grocery shopping with a tech-first, customer-centric approach. For instance, we built self-service tools for all our engineers that allow them to handle tasks like environment setup, database management, or feature deployment effectively.
Bronze layers can also be the raw database tables. If you can modify or control the ingestion code, data quality tests, and validation checks should ideally be integrated directly into the process. Alternatively, suppose you do not control the ingestion code. Bronze layers should be immutable.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Apache Kafka ® and its uses.
Like data scientists, data engineers write code. There’s a multitude of reasons why complex pieces of software are not developed using drag and drop tools: it’s that ultimately code is the best abstraction there is for software. blobs: modern databases have a growing support for blobs through native types and functions.
For those reasons, it is not surprising that it has taken over most of the modern data stack: infrastructure, databases, orchestration, data processing, AI/ML and beyond. That’s without mentioning the fact that for a cloud-native company, Tableau’s Windows-centric approach at the time didn’t work well for the team.
Our customers are some of the most innovative, engineering-centric businesses on the planet, and helping them do great work will continue to be our focus.” On that same day, the threat actor downloaded data from another database that stores pipeline-level config vars for Review Apps and Heroku CI.
In this post, we’re going to share how Hamilton , an open source framework, can help you write modular and maintainable code for your large language model (LLM) application stack. The example we’ll walk you through will mirror a typical LLM application workflow you’d run to populate a vector database with some text knowledge.
To illustrate that, let’s take Cloud SQL from the Google Cloud Platform that is a “Fully managed relational database service for MySQL, PostgreSQL, and SQL Server” It looks like this when you want to create an instance. You are starting to be an operation or technology centric data team.
But this article is not about the pricing which can be very subjective depending on the context—what is 1200$ for dev tooling when you pay them more than $150k per year, yes it's US-centric but relevant. But before sending your code to production you still want to validate some stuff, static or not, in the CI/CD pipelines.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. Today, Microsoft announces new low-code capabilities for Power Query in order to do "data preparation" from multiple sources. I hope he will fill the gaps. In the first part he treats about the history of modeling and the main concepts.
At the same time Maxime Beauchemin wrote a post about Entity-Centric data modeling. Today, Microsoft announces new low-code capabilities for Power Query in order to do "data preparation" from multiple sources. I hope he will fill the gaps. In the first part he treats about the history of modeling and the main concepts.
Structured data can be defined as data that can be stored in relational databases, and unstructured data as everything else. Examples of unstructured data, on the other hand, include media (video, images, audio), text files (email, tweets), business productivity files (Microsoft Office documents, Github code repositories, etc.) .
Data Engineers are skilled professionals who lay the foundation of databases and architecture. Using database tools, they create a robust architecture and later implement the process to develop the database from zero. Data engineers who focus on databases work with data warehouses and develop different table schemas.
For a data engineer that has already built their Spark code on their laptop, we have made deployment of jobs one click away. Airflow allows defining pipelines using python code that are represented as entities called DAGs. Each DAG is defined using python code. Job Deployment Made Simple. Automation APIs.
Ranorex Webtestit: A lightweight IDE optimized for building UI web tests with Selenium or Protractor It generates native Selenium and Protractor code in Java and Typescript respectively. Despite the technical coding knowledge and relevant experience, around 20% of professionals use this automation testing tool.
When it comes to writing a connector, there are two things you need to know how to do: how to write the code itself, and helping the world know about your new connector. This documentation is brand new and represents some of the most informative, developer-centric documentation on writing a connector to date.
Data engineers who previously worked only with relational database management systems and SQL queries need training to take advantage of Hadoop. They have to know Java to go deep in Hadoop coding and effectively use features available via Java APIs. Spark SQL creates a communication layer between RDDs and relational databases.
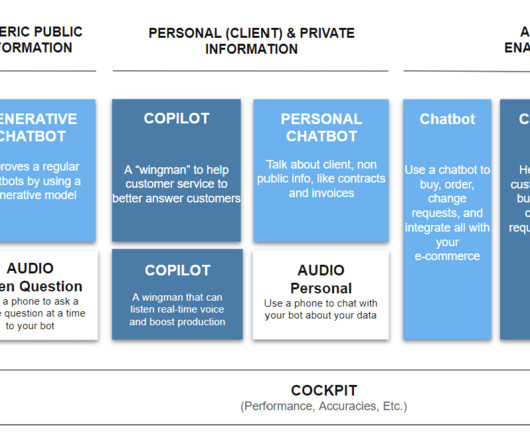
At DareData Engineering, we believe in a human-centric approach, where AI agents work together with humans to achieve faster and more efficient results. At its core, RAG harnesses the power of large language models and vector databases to augment pre-trained models (such as GPT 3.5 ).
The National Association of REALTORS ® clearly understands this challenge, which is why it built RPR (Realtors Property Resource), the nation’s largest parcel-centricdatabase, exclusively for REALTORS ®. Plus, things change – ZIP Codes are added, neighborhoods are constructed – so RPR is constantly looking to improve its match rates.
SQL – A database may be used to build data warehousing, combine it with other technologies, and analyze the data for commercial reasons with the help of strong SQL abilities. Pipeline-centric: Pipeline-centric Data Engineers collaborate with data researchers to maximize the use of the info they gather.
All you need to know for a quick start with Domain DrivenDesign Created using DALLE In todays fast-paced development environment, organising code effectively is critical for building scalable, maintainable, and testable applications. At its core, Hexagonal Architecture is a domain-centric approach.
Monolithic structure : Since Reloaded modules were often co-located in the same repository, it was easy to overlook code-isolation rules and there was quite a bit of unintended reuse of code across what should have been strong boundaries. The results are saved to a database so they can be reused. 264, AV1, etc.).
With One Lake serving as a primary multi-cloud repository, Fabric is designed with an open, lake-centric architecture. Mirroring (a data replication capability) : Access and manage any database or warehouse from Fabric without switching database clients; Mirroring will be available for Azure Cosmos DB, Azure SQL DB, Snowflake, and Mongo DB.
Looking for a position to test my skills in implementing data-centric solutions for complicated business challenges. Sound knowledge of developing web portals, e-commerce applications, and code authoring. Seeking to provide coding and scripting competencies to the company's IT dept. An entry-level graduate with B.S.
In the fast-paced world of software development, the efficiency of build processes plays a crucial role in maintaining productivity and code quality. The parser used advanced regular expressions and parsing techniques to extract critical data, such as build duration, failure points, and related code changes.
typically represents several objects and functions accessible to JavaScript code. JavaScript code can now execute outside of the browser, thanks to Node.js. The API frequently changes, which causes challenges for developers because they'll have to make adjustments to their existing code base to stay compatible. What is Node.js?
He compared the SQL + Jinja approach to the early PHP era… […] “If you take the dataframe-centric approach, you have much more “proper” objects, and programmatic abstractions and semantics around datasets, columns, and transformations.
In large organizations, data engineers concentrate on analytical databases, operate data warehouses that span multiple databases, and are responsible for developing table schemas. Data engineering builds data pipelines for core professionals like data scientists, consumers, and data-centric applications.
New revenue stream through a persona-based database can be monetized through co-marketing efforts. Season Pass Holder Database . Demographic centric marketing. QR code app on smartphone. Rationalization of marketing and advertising spend producing the highest ROI. New Profit Steams – . Pricing Optimization –
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. Lets dig into one way that you can use that geocoded data.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization We have come a long way, but have we been able to harness the full power of Big Data analytics in healthcare ? Big Trends in Healthcare Industry 50 years back healthcare services were mostly physician centric.
Immediate Execution: Python code runs directly through the interpreter, eliminating the need for a separate compilation step. Platform Independence: With an interpreter for a specific platform, Python code can typically run without changes. It's specialized for database querying. Compiled, targeting the JVM.
In this post, we’ll look at the historical reasons for the 191 character limit as a default in most relational databases. The first question you might ask is why limit the length of the strings you can store in a database at all? Why varchar and not text ? s fault 255 makes a lot more sense than 191. How did we get to 191?
These backend tools cover a wide range of features, such as deployment utilities, frameworks, libraries, and databases. Better Data Management: Database management solutions offered by backend tools enable developers to quickly store, retrieve, and alter data.
Making decisions in the database space requires deciding between RDBMS (Relational Database Management System) and NoSQL, each of which has unique features. Come with me on this adventure to learn the main differences and parallels between two well-known database solutions, i.e., RDBMS vs NoSQL. What is RDBMS? What is NoSQL?
Code-free Data Flow Mapping Data Flows in Azure Data Factory allows non-developers to build complex data transformations, plus clean, filter, and manipulate the data on the fly without writing a single line of code. For online sources, ADF offers numerous built-in connectors for APIs, cloud services, and databases.
It offers a wide range of services, including computing, storage, databases, machine learning, and analytics, making it a versatile choice for businesses looking to harness the power of the cloud. This cloud-centric approach ensures scalability, flexibility, and cost-efficiency for your data workloads.
Data modernization is an umbrella term for the many ways businesses upgrade their data infrastructure, typically with cloud-centric solutions like the Snowflake Data Cloud. The cloud also democratizes access to data, whereas on-premises databases tend to restrict access and create silos.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
Having a GitHub pull request template is one of the most important and frequently overlooked aspects of creating an efficient and scalable dbt-centric analytics workflow. For the reviewer, it lets them know what it is they are reviewing before laying eyes on any code. Let's explore how to use each section and its benefits.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content