This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Document analysis is crucial for efficiently extracting insights from large volumes of text. For example, cancer researchers can use document analysis to quickly understand the key findings of thousands of research papers on a certain type of cancer, helping them identify trends and knowledge gaps needed to set new research priorities.
MongoDB stores data in collections of JSON documents in a human-readable format. It is also compatible with IDEs like Studio3T, JetBrains (DataGrip), and VS Code. MongoDB’s scale-out architecture allows you to shard data to handle fast querying and documentation of massive datasets. Link to the source code.
for the simulation engine Go on the backend PostgreSQL for the data layer React and TypeScript on the frontend Prometheus and Grafana for monitoring and observability And if you were wondering how all of this was built, Juraj documented his process in an incredible, 34-part blog series. Documenting the steps. You can read this here.
Instead of generating answers from parameters, the RAG can collect relevant information from the document. A retriever is used to collect relevant information from the document. Thanks to this retriever, instead of looking at the entire document, RAG will only search the relevant part. What is a retriever? Let’s consider this.
” They write the specification, code, tests it, and write the documentation. Edits documentation the chief programmer writes, and makes it production-ready. Code reviews reduce the need to pair while working on a task, allowing engineers to keep up with changes and learn from each other. The copilot. The editor.
Downloading files for months until your desktop or downloads folder becomes an archaeological dig site of documents, images, and videos. Features to include: Auto-categorization by file type (documents, images, videos, etc.) She enjoys reading, writing, coding, and coffee!
With building conversational agents over documents, for example, we measured quality average across several Q&A benchmarks. Figure 1 Figure 2 For document understanding, Agent Bricks builds higher quality and lower cost systems, compared to prompt optimized proprietary LLMs (Figure 2). Agent Bricks is now available in beta.
Conversational apps: Creating reliable, engaging responses for user questions is now simpler, opening the door to powerful use cases such as self-service analytics and document search via chatbots. For instance, if your documents are in multiple languages, an LLM with strong multilingual capabilities is key.
Click here to view a list of 50+ solved, end-to-end Big Data and Machine Learning Project Solutions (reusable code + videos) PyTorch 1.8 has introduced better features for code optimization, compilation, and front-ned apis for scientific computing. vs Tensorflow 2.x x in 2021 What's New in TensorFlow 2.x
What would you do if you learned your company is up to something illegal like stealing customer funds, or you’re asked to make code changes that will enable something illegal to happen, like misleading investors, or defrauding customers? Sign up to The Pragmatic Engineer to get articles like this earlier in your inbox.
Source Code: E-commerce product reviews - Pairwise ranking and sentiment analysis. Source Code: Chatbot example application using python - text classification using nltk. The task is to have a document and use relevant algorithms to label the document with an appropriate topic.
However, Martin had not written a line of production code for the last four years, as he’s taken on the role of CEO, and heads up observability scaleup Chronosphere – at more than 250 people and growing. From learning to code in Australia, to working in Silicon Valley How did I learn to code?
Since DuckDB is an embedded database engine with no server requirements or external dependencies, setup typically takes just a few lines of code. You can find the complete installation guide in the official DuckDB documentation. You can go check the full code on the following GitHub repository.
That type of volume can easily put a strain on the doctors, who not only serve the patients but also need to document each visit carefully — from summaries to diagnoses to medication orders. Its emergency departments get nearly 2 million visits per year, which amounts to more than 5,000 a day.
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. You can produce code, discover the data schema, and modify it. Users can schedule ETL jobs, and they can also choose the events that will trigger them.
Claude's advanced language models will further enhance how developers can build agents that can run ad hoc analytics, extract answers from documents and other knowledge bases and execute other multistep workflows. Here is an example of what that looks like: Get started: Build a RAG-based document search app Claude 3.5 With Sonnet 3.5
a macro — a macro is a Jinja function that either do something or return SQL or partial SQL code. ref / source macros — ref and source macros are the most important macros you'll use. ℹ️ I want to mention that the dbt documentation is one of the best tools documentation out there.
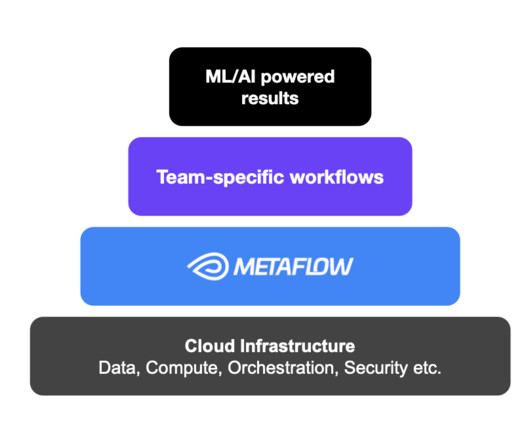
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization Machine Learning Project Ideas on Computer Vision Face Recognition Face recognition is a non-trivial computer vision problem that recognises faces and clusters them under appropriate classes.
Once the basic game is built, the Code Reviewer Agent steps in with granular control—checking for clean code, syntax issues, and best practices using integrated linting tools. Agents collaborate via shared memory and access external tools like Serper to fetch documentation or code examples on the fly.
By incorporating Knowledge Graphs, RAG systems can overcome the limitations of data retrieval from multiple documents. Step 2: Creating a Knowledge Graph with LangChain and Neo4j The code snippet below demonstrates how to build a basic knowledge graph using sample data. These objects are added to the Neo4j database.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. Besides providing the end user with an instant answer in a preferred data visualization, LORE instantly learns from the users feedback.
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
Natural language processing is a field of data science where problems involve working with text data, such as document classification, topic modeling , or next-word prediction. Next, use the code below to load data for both labels into a Pandas DataFrame. FAQs on Python NLTK What is NLTK in Machine Learning?
1] Snowpark now offers enhanced capabilities for bringing code to data securely and efficiently across languages, with expanded support across data integration, package management and secure connectivity. Users can ingest only the relevant parts of an XML document and receive structured tabular output for downstream processing.
It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
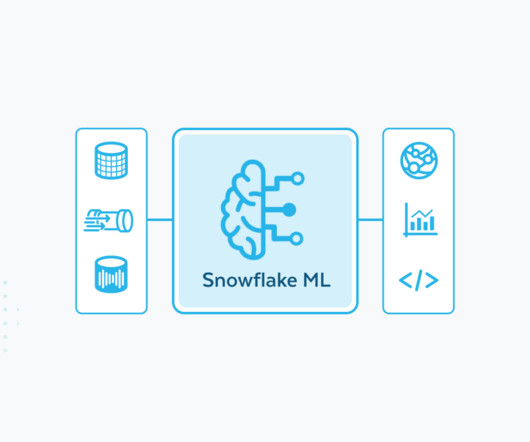
Snowflake has embraced serverless since our founding in 2012, with customers providing their code to load, manage and query data and us taking care of the rest. They can easily access multiple code interfaces, including those for SQL and Python, and the Snowflake AI & ML Studio for no-code development.
Its Snowflake Native App, Digityze AI, is an AI-powered document intelligence platform that transforms unstructured biomanufacturing documentation into structured, actionable data and manages the document lifecycle.
LLMs deployed as internal enterprise-specific agents can help employees find internal documentation, data, and other company information to help organizations easily extract and summarize important internal content. No-code, low-code, and all-code solutions. Increase Productivity.
Rapid Document Conversion This project aims to quickly and accurately convert the document to the desired format as selected by the user. Many of the document converters, such as PDF to word converters and others, are available online. You must have experienced the need to convert an HTML page/document into PDF format.
This person wrote up a neat document that was well thought out, and sent it around to other senior staff engineers. But there was a problem, this engineer took an existing document that other engineers had written a few months before, copy-pasted it, changed a few words, and presented it as their own work.
Suppose you want to learn to use AWS CloudFormation, a tool for defining and deploying infrastructure resources as code. You could read the documentation, watch videos, or take online courses to understand the theoretical concepts and syntax of CloudFormation. The code consists of the client code (Vue.js
After experiencing numerous data quality challenges, they created Anomalo, a no-code platform for validating and documenting data warehouse information. Anomalo was founded in 2018 by two Instacart alumni, Elliot Shmukler and Jeremy Stanley. While working together, they bonded over their shared passion for data.
Code Repository : The data and code repository has to be selected such that it fits into the MLOps stack being used, especially if it is on the cloud ML Pipeline : Similar to data pipelines, ML pipelines help carry the state of the machine learning project from data to ML output. The source code for inspiration can be found here.
SnowConvert is an easy-to-use code conversion tool that accelerates legacy relational database management system (RDBMS) migrations to Snowflake. Florida State University has been using Document AI to efficiently extract data from PDFs and third-party sources, which simplifies data auditing and eliminates weeks’ worth of manual effort.
Claude Desktop I really enjoy using Claude Desktop because it makes it easy to view and interact with code in dynamic ways. Claude Code The moment I tried Claude Code with Claude Opus 4, I was impressed by how well it understands your requirements and code, producing almost bug-free results.
A problem that takes over 30 lines to solve with Keras can be solved in only five lines of code with FastAI. Dataset: Kaggle Chest X-Ray Images Tools and Libraries: FastAI, ResNet50, TensorFlow, Python Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization 8.
By Abid Ali Awan , KDnuggets Assistant Editor on June 13, 2025 in Programming Image by Author Claude Opus 4 is Anthropics most advanced and powerful AI model to date, setting a new benchmark for coding, reasoning, and long-running tasks. Copy the authentication code generated by the console and paste it into the Claude Code terminal.
Thats why we are announcing that SnowConvert , Snowflakes high-fidelity code conversion solution to accelerate data warehouse migration projects, is now available for download for prospects, customers and partners free of charge. And today, we are announcing expanded support for code conversions from Amazon Redshift to Snowflake.
Modern development workflow : Branching a database should be as easy as branching a code repository, and it should be near instantaneous. At zero, the cost of the lakebase is just the cost of storing the data on cheap data lakes. Product December 12, 2024 / 4 min read Making AI More Accessible: Up to 80% Cost Savings with Meta Llama 3.3
Here is why Python is the ideal choice for web scraping- Easy to Understand - Reading a Python code is similar to reading an English statement, making Python syntax simple to learn. Less Time-Consuming - Web scraping aims to save time, but if you have to write more code, what good is it?
See more details in the documentation. See more details in the documentation. "I am able to run my code without worrying about it timing out or variables being forgotten. Optimized data ingestion APIs that offer efficient materialization of Snowflake tables as pandas or PyTorch DataFrames.
Leverage Databricks Repos For Version Control And Collaboration You must use Databricks Repos, a centralized Git-based repository, for storing, versioning, and sharing notebooks, libraries, and code dependencies. They use Databricks Repos to manage and store their notebooks, including the code for data loading, transformation, and ingestion.
With working code snippets and in-depth explanations, you’ll gain hands-on experience to develop your model and see the process in action. One thus requires Hugging Face's Transformers for models like Llama-2 LangChain for document processing and Q&A systems FAISS for efficient retrieval of relevant information.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content