This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Building a data pipeline may sound complex, but a few simple tools are sufficient to create reliable data pipelines with just a few lines of code. In this article, we will explore how to build a straightforward data pipeline using Python and Docker that you can apply in your everyday data work. Let’s get into it. as its environment.
These one-liners show how to do more with less code. These one-liners show how to extract meaningful info from data with minimal code while maintaining readability and efficiency. Please note: In the code snippets that follow, Ive excluded the print statements.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 24, 2025 in Python Image by Author | Ideogram Data is messy. By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on June 24, 2025 in Python Image by Author | Ideogram Data is messy.
Start here with a simple Python pipeline that covers the essentials. Nothing fancy, just practical code that gets the job done. 🔗 Link to the code on GitHub What Is an Extract, Transform, Load (ETL) Pipeline? You can find the complete code on GitHub. Happy coding! She enjoys reading, writing, coding, and coffee!
Airflow enables you to define workflows as Pythoncode, allowing for dynamic and scalable pipelines suitable to any use case from ETL/ELT to running ML/AI operations in production. With over 30 million monthly downloads, Apache Airflow is the tool of choice for programmatically authoring, scheduling, and monitoring data pipelines.
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. As understanding how to deal with data is becoming more important, today I want to show you how to build a Python workflow with DuckDB and explore its key features.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 22, 2025 in Python Image by Author | Ideogram # Introduction Most applications heavily rely on JSON for data exchange, configuration management, and API communication. She enjoys reading, writing, coding, and coffee!
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on August 5, 2025 in Python Image by Author | Ideogram # Introduction Picture this: youre working on a Python project, and every time you want to run tests, you type python3 -m pytest tests/ --verbose --cov=src. When you want to format your code, its black.
To do this, we’re excited to announce new and improved features that simplify complex workflows across the entire data engineering landscape — from SQL workflows that support collaboration to more complex pipelines in Python. Python XML RowTag Reader (private preview) allows loading large, nested XML files using a simple rowTag option.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter The Lifecycle of Feature Engineering: From Raw Data to Model-Ready Inputs This article explains how (..)
Recommended actions: Use orchestration tools like Airflow, Prefect, or Dagster to schedule and automate workflows Set up retry policies and alerts for failures Version your pipeline code and modularize for reusability 6. Streaming: Use tools like Kafka or event-driven APIs to ingest data continuously.
By Vinod Chugani on June 27, 2025 in Data Science Image by Author | ChatGPT Introduction Creating interactive web-based data dashboards in Python is easier than ever when you combine the strengths of Streamlit , Pandas , and Plotly. Youll write your code in a text-based IDE like VS Code, save it as a.py sum():,}") col2.metric("Average
The Python Data Source API integrates healthcare Python libraries into Spark, allowing single-step processing of compressed files instead of complex ETL pipelines with unzipping and UDFs. DICOM files contain a header section of rich metadata. There are over 4200 standard defined DICOM tags. core seconds per DICOM file.
But what happens when your data is too big for a spreadsheet, or when you want to run a prediction without writing a bunch of code? No Python or API wrangling needed - just a Sheets formula calling a model. That same notebook environment can even act as an AI partner to help plan your analysis and write code.
In this article, we go over essential Python libraries that address the core challenges of MLOps: experiment tracking, data versioning, pipeline orchestration, model serving, and production monitoring. DVC fills this gap by tracking your data files and transformations separately while keeping everything synchronized with your code.
That means no local setup headaches, you’re writing the code instantly. Data Project - Uber Business Modeling We will use it with Jupyter Notebook, combining it with Python for data analysis. Now, here is the code to make a connection and register the dataframe. Here is the code.
It packages code for reproducibility. Source Code : The exact code version used to produce the experiment results. MLFlow Projects MLflow Projects enable reproducibility and portability by standardizing the structure of ML code. A project contains: Source code : The Python scripts or notebooks for training and evaluation.
With over 54 repositories and 20k stars, Streamlit is an open-source Python framework for developing and distributing web apps for data science and machine learning projects. Let us explore a few exciting Streamlit python project ideas for data scientists and data engineers. using Streamlit. Check them out now!
I have a 15% discount code if you're interested BLEF_AIProductDay25. Actually a modern Kaggle for Agentic AI, in the end it's a mechanism to lower human labor cost, because spoiler human will code to create these agents. Agents write pythoncode to call tools and orchestrate other agents.
Run it once to generate the model file: python model/train_model.py However, it: Validates input data automatically Returns meaningful responses with prediction confidence Logs every request to a file (api.log) Uses background tasks so the API stays fast and responsive Handles failures gracefully And all of it in under 100 lines of code.
No Python environment setup, no manual coding, no switching between tools. Unlike writing standalone Python scripts, n8n workflows are visual, reusable, and easy to modify. This routine gets tedious when youre evaluating multiple datasets daily. Perfect for on-demand data quality checks.
By Matthew Mayo , KDnuggets Managing Editor on July 17, 2025 in Python Image by Editor | ChatGPT Introduction Pythons standard library is extensive, offering a wide range of modules to perform common tasks efficiently. This makes your code more readable than using a standard tuple. This is especially useful for grouping items.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter AI Agents in Analytics Workflows: Too Early or Already Behind? Here, SQL stepped in.
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Hack, C++, Python, etc.) web endpoints, data tables, AI models) used across Meta.
Get ready to supercharge your data processing capabilities with Python Ray! Our tutorial teaches you how to unlock the power of parallelism and optimize your Pythoncode for optimal performance. ​​Imagine This is where Python Ray comes in. Table of Contents What is Python Ray?
Learn to build no-code AI agents, automate tasks, and integrate tools visually using these real-world n8n templates and source code. n8n lets you combine the best of no-code automation with developer-grade power to build projects that really take off, from chatbot agents to marketing pipelines to data orchestration systems.
py # (Optional) to mark directory as Python package You can leave the __init.py__ file empty, as its main purpose is simply to indicate that this directory should be treated as a Python package. Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
In this blog, you’ll build a complete ETL pipeline in Python to perform data extraction from the Spotify API, followed by data manipulation and transformation for analysis. In this blog, you’ll learn how to build ETL pipeline in Python, the language most loved by data engineers worldwide. Python fits that role perfectly.
First, we need to initialize the BigQuery client with the following code. from google.cloud import bigquery client = bigquery.Client() Then, lets query our dataset in the BigQuery table using the following code. Note that the following code will overwrite the destination table if it already exists, rather than appending to it.
hen, show most suitable visualizations for this dataset and explain why each was selected and produce the plots in this chat by running code on the dataset. You can install it by using this code. (60 Let’s start by installing it using the code below. Here is the output. We have six different graphs that we produced with ChatGPT.
Data Warehouse Projects for Beginners From Beginner to Advanced level, you will find some data warehouse projects with source code, some Snowflake data warehouse projects, some others based on Google Cloud Platform (GCP), etc. Experience Hands-on Learning with the Best Azure Data Engineering Course and Get Certified!
It covers everything from interview questions for beginners to intermediate professionals, along with excellent coding and data science-related questions. Here are some common methods: From a List or NumPy array: You can create a Series from a Python list or a NumPy array. So, let’s get started!
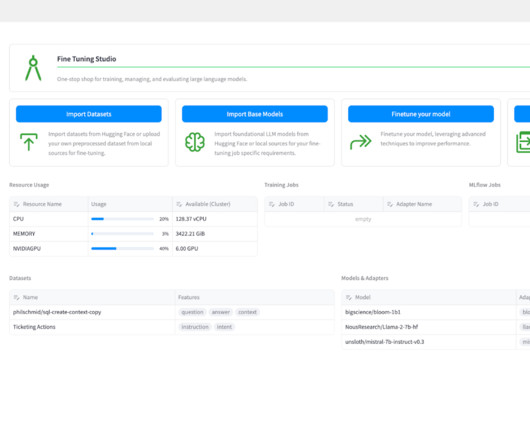
LLMs deployed as code assistants accelerate developer efficiency within an organization, ensuring that code meets standards and coding best practices. No-code, low-code, and all-code solutions. Fine Tuning Studio ships with a convenient Python client that makes calls to the Fine Tuning Studio’s core server.
User code and data transformation are abstracted so they can be easily moved to any other data processing systems. Design: Code Consolidation: Consolidated common code across teams, e.g. the dataset readers for Iceberg and Parquet.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization What do Data Engineers do? Good skills in computer programming languages like R, Python, Java, C++, etc. Here is a book recommendation : Python for Absolute Beginners by Michael Dawson.
This blog will discover how Python has become an integral part of implementing data engineering methods by exploring how to use Python for data engineering. As demand for data engineers increases, the default programming language for completing various data engineering tasks is accredited to Python.
I thought a real engineer looks at logs, hard-to-read code, and whatever else made them look smart if someone ever glanced at their computerscreen. Thanks to Python, this can be achieved using a script with as few as 100 lines ofcode. If you know a bit of Python and LLM prompting you should be able to hack the code in an hour.
By using Pythoncode, we can generate an interactive visualization that enables users to engage in a more intuitive data exploration process. Voilà The usual Jupyter Notebooks are a static application where you run the code as it is, and not a standalone application to run. We can see an example of Jupyter Widgets below.
We developed tools and APIs for developers to easily integrate Policy Zones, which automatically track and protect data flows by enforcing flow restrictions at runtime , to their code. The logger config code snippet above generates code that writes data to a corresponding Scribe message queue category from our web servers.
To address that, the Advisor360° analytics and insights team built a sentiment model from scratch, using highly specialized, Python-heavy code that would extract data and push it out to a file, then incorporate it into a dashboard. But, of course, the model required constant maintenance and updating.
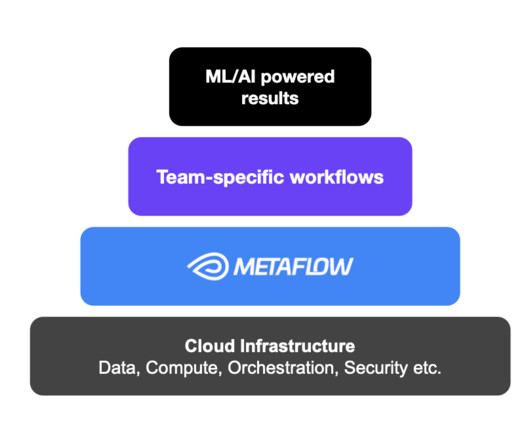
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
Customers can now access the most intelligent model in the Claude model family from Anthropic using familiar SQL, Python and REST API (coming soon) interfaces, within the Snowflake security perimeter. SQL and Python The model can be integrated into a data pipeline or a Streamlit in Snowflake app to process multiple rows in a table.
With Python libraries like Dash, Streamlit, and Plotly, building interactive dashboards is easier than ever. This blog will guide you through building dashboards in python that help users think less and understand more—just as our brains are designed to do! But why Python? Table of Contents Why Build Dashboards in Python?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content