This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RevOps teams want to streamline processes… Read more The post Best Automation Tools In 2025 for Data Pipelines, Integrations, and More appeared first on Seattle Data Guy. But automation isnt just for analytics.
The Data News are here to stay, the format might vary during the year, but here we are for another year. We published videos about the Forward Data Conference, you can watch Hannes, DuckDB co-creator, keynote about Changing Large Tables. HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. Not really digest.
There are plenty of statistics about the speed at which we are creating data in today’s modern world. On the flip side of all that data creation is a need to manage all of that data and thats where data teams come in.
Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” The ecosystem is louder, flashier, and more fragmented.
Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-driven decisions—without losing the value of human insight! But how do you implement these tools with confidence and ensure they complement human expertise rather than override it?
What will data engineering look like in 2025? How will generative AI shape the tools and processes Data Engineers rely on today? As the field evolves, Data Engineers are stepping into a future where innovation and efficiency take center stage.
If you work in data, then youve likely used BigQuery and youve likely used it without really thinking about how it operates under the hood. On the surface BigQuery is Google Clouds fully-managed, serverless data warehouse. appeared first on Seattle Data Guy. Its the Redshift of GCP except we like it a little more.
Does the LLM capture all the relevant data and context required for it to deliver useful insights? Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? But simply moving the data wasnt enough.
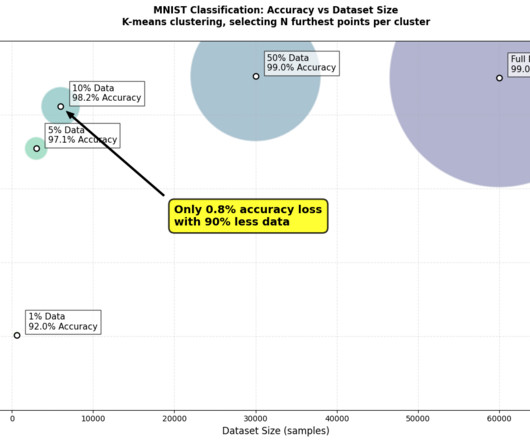
Building more efficient AI TLDR : Data-centric AI can create more efficient and accurate models. I experimented with data pruning on MNIST to classify handwritten digits. What if I told you that using just 50% of your training data could achieve better results than using the fulldataset? Image byauthor.
Storytelling is more than just data visualization. Storytelling provides an organized approach for conveying data insights through visuals and narrative. Data-driven storytelling could be used to influence user actions, and ensure they understand what data matters the most.
In this post, we delve into predictions for 2025, focusing on the transformative role of AI agents, workforce dynamics, and data platforms. For professionals across domains—data engineers, AI engineers, and data scientists—the message is clear: adapt or become obsolete.
Run Data Pipelines 2.1. Introduction Whether you are new to data engineering or have been in the data field for a few years, one of the most challenging parts of learning new frameworks is setting them up! Introduction 2. Run on codespaces 2.2. Run locally 3. Projects 3.1. Projects from least to most complex 3.2. Conclusion 1.
Key Takeaways: Data mesh is a decentralized approach to data management, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments.
Here’s where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024—plus a few predictions of my own. 2025 data engineering trends incoming. Small data is the future of AI (Tomasz) 7. The lines are blurring for analysts and data engineers (Barr) 8. Table of Contents 1.
Organizational data literacy is regularly addressed, but it’s uncommon for product managers to consider users’ data literacy levels when building products. Product managers need to research and recognize their end users' data literacy when building an application with analytic features.
Data integration is critical for organizations of all sizes and industriesand one of the leading providers of data integration tools is Talend, which offers the flagship product Talend Studio. In 2023, Talend was acquired by Qlik, combining the two companies data integration and analytics tools under one roof.
Saying mainly that " Sora is a tool to extend creativity " Last point Mira has been mocked and criticised online because as a CTO she wasn't able to say on which public / licensed data Sora has been trained on. Pandera, a data validation library for dataframes, now supports Polars.
Data lineage is an instrumental part of Metas Privacy Aware Infrastructure (PAI) initiative, a suite of technologies that efficiently protect user privacy. It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems.
Meroxa was created to enable teams of all sizes to deliver real-time data applications. In this episode DeVaris Brown discusses the types of applications that are possible when teams don't have to manage the complex infrastructure necessary to support continuous data flows. Can you describe what Meroxa is and the story behind it?
In the data-driven world […] The post Monitoring Data Quality for Your Big Data Pipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Three Zero-Cost Solutions That Take Hours, NotMonths A data quality certified pipeline. Source: unsplash.com In my career, data quality initiatives have usually meant big changes. Whats more, fixing the data quality issues this way often leads to new problems. Create a custom dashboard for your specific data qualityproblem.
However, PDF files also present multiple challenges when it… Read more The post What Is PDFMiner And Should You Use It – How To Extract Data From PDFs appeared first on Seattle Data Guy.
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
In the rapidly evolving healthcare industry, delivering data insights to end users or customers can be a significant challenge for product managers, product owners, and application team developers. The complexity of healthcare data, the need for real-time analytics, and the demand for user-friendly interfaces can often seem overwhelming.
You know, for all the hoards of content, books, and videos produced in the “Data Space” over the last few years, famous or others, it seems I find there are volumes of information on the pieces and parts of working in Data. appeared first on Confessions of a Data Guy.
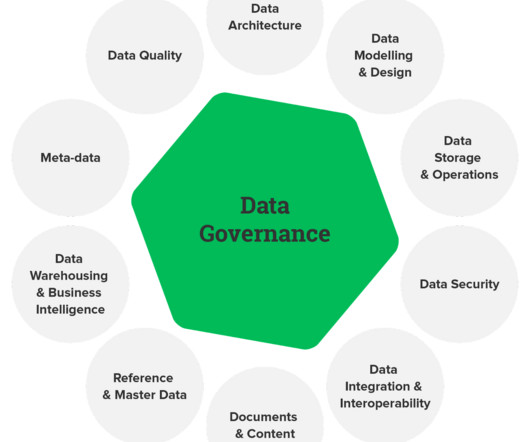
Key Takeaways: Prioritize metadata maturity as the foundation for scalable, impactful data governance. Recognize that artificial intelligence is a data governance accelerator and a process that must be governed to monitor ethical considerations and risk.
Agentic AI, small data, and the search for value in the age of the unstructured datastack. Heres where leading futurist and investor Tomasz Tunguz thinks data and AI stands at the end of 2024plus a few predictions of myown. 2025 data engineering trends incoming. Search: tools that leverage a corpus of data to answer questions 3.
Much of the data we have used for analysis in traditional enterprises has been structured data. However, much of the data that is being created and will be created comes in some form of unstructured format. However, the digital era… Read more The post What is Unstructured Data?
Logi Spark 2021 consists of two days of networking, best practice sessions, and forward-thinking keynotes on the future of data. Preview our sessions and sign up to join other data leaders looking to transform the world of analytics.
Data engineering plays a pivotal role in the vast data ecosystem by collecting, transforming, and delivering data essential for analytics, reporting, and machine learning. Aspiring data engineers often seek real-world projects to gain hands-on experience and showcase their expertise.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights. How Does Uber Know Where to Go?
A Deep Dive into Databricks Labs’ DQX: The Data Quality Game Changer for PySpark DataFrames Recently, a LinkedIn announcement caught my eyeand honestly, it had me on the edge of my seat. Databricks Labs has unveiled DQX, a Python-based Data Quality framework explicitly designed for PySpark DataFrames.
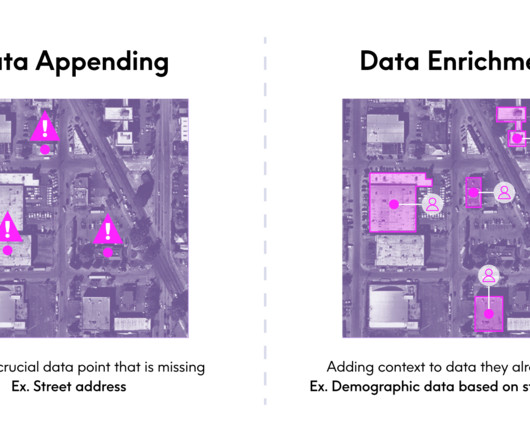
We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment. Ive noticed that “data appending” is more commonly used in industries like marketing and telecommunications, while data enrichment seems to be the preferred term in financial services and retail.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
We are excited to announce the acquisition of Octopai , a leading data lineage and catalog platform that provides data discovery and governance for enterprises to enhance their data-driven decision making. This dampens confidence in the data and hampers access, in turn impacting the speed to launch new AI and analytic projects.
After 10 years of Data Engineering work, I think it’s time to hang up the proverbial hat and ride off into the sunset, never to be seen again. Sometimes I wonder if I’ve learned anything […] The post What I’ve Learned After A Decade Of Data Engineering appeared first on Confessions of a Data Guy.
dbt is the standard for creating governed, trustworthy datasets on top of your structured data. We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. What is MCP? Why does this matter?
Think your customers will pay more for data visualizations in your application? Download the whitepaper to learn about Monetizing Analytics Features, and Why Data Visualizations Will Never Be Enough. Five years ago they may have. But today, dashboards and visualizations have become commonplace.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Data lakes are notoriously complex. Join in with the event for the global data community, Data Council Austin.
Most data projects use Docker to set up the data infra locally (and often in production). Communicate between containers and local OS 2.2.2. Start containers with docker CLI or compose 3. Conclusion 1. Introduction Docker can be overwhelming to start with.
As AI applications multiply quickly, vector technologies have become a frontier that data engineers must explore. The database landscape has reached 394 ranked systems across multiple categoriesrelational, document, key-value, graph, search engine, time series, and the rapidly emerging vector databases.
Building efficient data pipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Introduction 2. Project demo 3. Use DuckDB 4.4.
In the fast-moving manufacturing sector, delivering mission-critical data insights to empower your end users or customers can be a challenge. Traditional BI tools can be cumbersome and difficult to integrate - but it doesn't have to be this way.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content