This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Choosing the right dataanalysistools is challenging, as no tool fits every need. This blog will help you determine which dataanalysistool best fits your organization by exploring the top dataanalysistools in the market with their key features, pros, and cons. Power BI 4.
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Observability in Your DataPipeline: A Practical Guide Eitan Chazbani June 8, 2023 Achieving observability for datapipelines means that data engineers can monitor, analyze, and comprehend their datapipeline’s behavior. This is part of a series of articles about data observability.
Project Idea : Use the StatsBomb Open Data to study player and team performances. Build a datapipeline to ingest player and match data, clean it for inconsistencies, and transform it for analysis. Load raw data into Google Cloud Storage, preprocess it using Mage VM, and store results in BigQuery.
DBT shows how data moves across the organization while improving the outcomes of other dataanalysistools. Since the data warehouse manages all computational effort, controlling a DBT datapipeline necessitates using few resources. using control structures and environment variables).
Lastly, Google Data Studio is used to visualize the data. Source Code- GCP Data Ingestion using Google Cloud Dataflow Build DataPipeline using Dataflow, Apache Beam, Python This is yet another intriguing GCP project that uses PubSub, Compute Engine, Cloud Storage, and BigQuery.
AWS Data Analytics Certification Prerequisites If you are looking for a list of prerequisite for aws data analytics certification, then check out the points mentioned below: At least five years of experience with dataanalysistools and technologies. It is likely that people nearby you will also be doing the same.
They are specialists in database management systems, cloud computing, and ETL (Extract, Transform, Load) tools. Making sure that data is organized, structured, and available to other teams or apps is the main responsibility of a data engineer. Also, data analysts have a thorough comprehension of statistical ideas and methods.
Picture this: your data is scattered. Datapipelines originate in multiple places and terminate in various silos across your organization. Your data is inconsistent, ungoverned, inaccessible, and difficult to use. Some of the value companies can generate from data orchestration tools include: Faster time-to-insights.
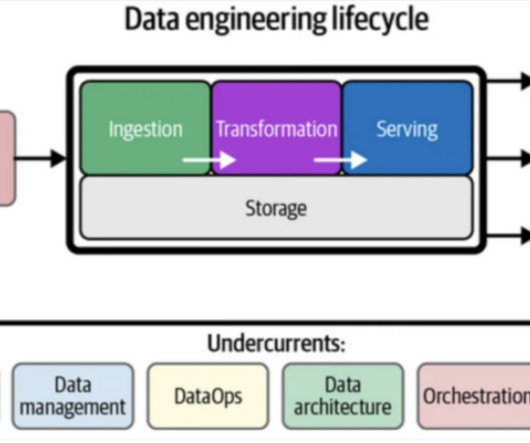
Data Engineer A Data Engineer specializes in designing, building, and maintaining datapipelines and infrastructure. They focus on creating scalable and efficient systems to collect, transform, and load raw data from different sources into usable formats for analysis by data scientists, analysts, and other stakeholders.
Prediction #5: Metrics Layers Unify Data Architectures (Tomasz) Tomasz’s next prediction dealt with the ascendance of the metrics layer, also known as the semantics layer. This made a big splash at dbt’s Coalesce the last two years and it’s going to start transforming the way datapipelines and data operations look.
Data Sourcing: Building pipelines to source data from different company data warehouses is fundamental to the responsibilities of a data engineer. So, work on projects that guide you on how to build end-to-end ETL/ELT datapipelines.
With this tool, data science professionals can quickly extract and transform data. It allows integrating various dataanalysis & data-related components for machine learning (ML) and data mining objective by leveraging its modular datapipelining concept.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content