This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Choosing the right dataanalysistools is challenging, as no tool fits every need. This blog will help you determine which dataanalysistool best fits your organization by exploring the top dataanalysistools in the market with their key features, pros, and cons. Power BI 4.
As per the March 2022 report by statista.com, the volume for global data creation is likely to grow to more than 180 zettabytes over the next five years, whereas it was 64.2 And, with largers datasets come better solutions. It is a serverless big dataanalysistool. Best suited for large unstructured datasets.
And, when one uses statistical tools over these data points to estimate their values in the future, it is called time series analysis and forecasting. The statistical tools that assist in forecasting a time series are called the time series forecasting models. So, how can dataanalysistools help us?
Project Idea: Start data engineering pipeline by sourcing publicly available or simulated Uber trip datasets, for example, the TLC Trip record dataset.Use Python and PySpark for data ingestion, cleaning, and transformation. This project will help analyze user data for actionable insights.
Integrating and implementing business intelligence on Hadoop has revolutionized how businesses manage big data , making Hadoop-based BI solutions more efficient and cost-effective than traditional data warehousing. Business intelligence OLAP is a powerful technology used in BI to perform complex analyses of large datasets.
Source Code- Slowly Changing Dimensions Implementation using Snowflake Fraud Detection using PaySim Financial Dataset In today's world of electronic monetary transactions, detecting fraudulent transactions is a significant business use case. To overcome this issue, PaySim Simulator is used to create Synthetic Data available on Kaggle.
Distributed Data Processing Frameworks Another key consideration is the use of distributed data processing frameworks and data planes like Databricks , Snowflake , Azure Synapse , and BigQuery. These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets.
The Citizen Data Scientist is an individual who is not necessarily trained in data science or analytics but has the skills and tools to work with data and extract insights. Citizen data scientists leverage machine learning technology to build predictive or prescriptive analytics -based models.
Experience using automated data visualization tools such as Microsoft Power BI, Tableau, etc., for drawing meaningful insights from the given data. Ability to source large datasets from cloud servers. Extracting data from primary and secondary sources. Read our blog on how to become a data scientist to know more.
About 48% of companies now leverage AI to effectively manage and analyze large datasets, underscoring the technology's critical role in modern data utilization strategies. Here is a post by Lekhana Reddy , an AI Transformation Specialist, to support the relevance of AI in Data Analytics.
The potential of Generative AI in finance is rapidly expanding - driven by its ability to process vast datasets, identify patterns, and generate human-like text and code. You can also leverage AI to analyze vast datasets and uncover valuable insights, trends, and anomalies, improving financial reports' overall quality and informativeness.
AWS Data Analytics Certification Prerequisites If you are looking for a list of prerequisite for aws data analytics certification, then check out the points mentioned below: At least five years of experience with dataanalysistools and technologies. Source Code: Bosch Production Line Performance Project 4.
Data Profiling, also referred to as Data Archeology is the process of assessing the data values in a given dataset for uniqueness, consistency and logic. Data profiling cannot identify any incorrect or inaccurate data but can detect only business rules violations or anomalies. 5) What is data cleansing?
DBT shows how data moves across the organization while improving the outcomes of other dataanalysistools. Here are a few more useful features of the DBT tool that makes it valuable for data analysts and engineers.
If you are a tech enthusiast with strong moral fiber, the AI Data Ethicist path is ideal for making the world more ethical! Business Intelligence Consultant A Business Intelligence (BI) Consultant is responsible for leveraging dataanalysistools and techniques to assist organizations in making informed strategic decisions.
The essence of machine learning lies in its capacity to evolve through exposure to data, enabling computer science focused systems to improve their performance over time. Machine learning algorithms empower machines to make informed decisions and predictions by deciphering patterns and insights from vast datasets.
Sales Analysis Source Code Dataset Customer Review Sentiment Analysis It is the process of determining the emotional state of customers after they purchase or use the products. Students can use Python or R for dataanalysis. Tools like TextBlob and NLTK for sentiment analysis.
Integration with External Data : LangChain lets LLMs talk to APIs, databases, and other data sources. This lets them do things like get real-time information or process datasets that are specific to a topic. Some important reasons are: 1.
” Solution: Intelligent solutions can mine metadata, analyze usage patterns and frequencies, and identify relationships among data elements – all through automation, with minimal human input. Problem: “We face challenges in manually classifying, cataloging, and organizing large volumes of data.”
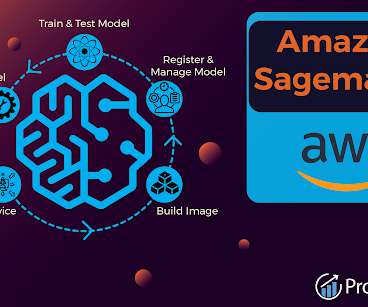
Build a Job Winning Data Engineer Portfolio with Solved End-to-End Big Data Projects Let us now explore the SageMaker architecture to understand what makes Amazon SageMaker unique and popular among the masses. Analyze – Data Wrangler allows you to analyze the features in your dataset at any stage of the data preparation process.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
As these engines are developed and optimized, data science for ecommerce plays a major role. Robust algorithms, fueled by extensive datasets, examine user behavior, past purchases, and product preferences to continuously improve the suggestions.
The benefits of AWS data analytics go beyond the technical skills professionals normally acquire through regular courses in the IT domain. Amazon Redshift, a data warehousing service that enables me to effectively store and analyze massive datasets, is a crucial part of AWS Data Analytics.
Build a Job Winning Data Engineer Portfolio with Solved End-to-End Big Data Projects Let us now explore the SageMaker architecture to understand what makes Amazon SageMaker unique and popular among the masses. Analyze – Data Wrangler allows you to analyze the features in your dataset at any stage of the data preparation process.
And, when one uses statistical tools over these data points to estimate their values in the future, it is called time series analysis and forecasting. The statistical tools that assist in forecasting a time series are called the time series forecasting models. So, how can dataanalysistools help us?
Data visualization and analysis (25–30%): Make dashboards and reports; improve the usability and storytelling of reports; and look for patterns and trends. Asset deployment and upkeep (20–25%): Manage workspaces, files, and datasets. Before responding, carefully go over the questions and the exhibits/datasets.
They employ various tools and approaches to handle data and construct and manage AI systems. They also work with Big Data technologies such as Hadoop and Spark to manage and process large datasets. Big Data Engineer Big Data engineers design and develop large-scale data processing systems.
Because of this, data science professionals require minimum programming expertise to carry out data-driven analysis and operations. It has visual data pipelines that help in rendering interactive visuals for the given dataset. Python: Python is, by far, the most widely used data science programming language.
Data Profiling, also referred to as Data Archeology is the process of assessing the data values in a given dataset for uniqueness, consistency and logic. Data profiling cannot identify any incorrect or inaccurate data but can detect only business rules violations or anomalies. 5) What is data cleansing?
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
MongoDB’s unique architecture and features have secured it a place uniquely in data scientists’ toolboxes globally. With large amounts of unstructured data requiring storage and many popular dataanalysistools working well with MongoDB, the prospects of picking it as your next database can be very enticing.
It involves working with large datasets of text and speech, analyzing the data to identify patterns and trends and developing algorithms to process and interpret the data. You should be comfortable with working on large datasets and have experience using tools like TensorFlow and Keras.
These BI projects will give you a deeper understanding of various data science concepts, BI tools, dataanalysistools, data warehousing, data visualization , data mining , etc.
If you are curious to know more about data science, you can check out what is Data Science course. Why is Data Science Important? One of the main reasons why data science is popular in today’s world is due to its ability to convert massive datasets into meaningful insights.
Proficiency in Python and other dataanalysistools for building new models and writing new software that can help organize, arrange, and filter data with minimal human work. . Data cleaning, processing, and validation . Execute some operations on datasets, such as Exploratory DataAnalysis. .
Data Scientist Template Link: Data Scientist (Download here) Why This Cover Letter Works: Highlights technical proficiency in relevant dataanalysistools and programming languages. Provides examples of utilizing data to solve complex business problems.
With the help of the company's "augmented analytics," you can ask natural-language inquiries and receive informative responses while also applying thoughtful data preparation. Some of the best features of oracle analytics cloud are augmented analytics, data discovery, and natural language processing.
One of the essential tools for data scientists is R, a programming language and software environment for statistical computing and graphics. . R is free and open-source software that statisticians and data scientists widely use. R is a powerful dataanalysistool with many built-in statistical and machine-learning functions.
Integration with External Data : LangChain lets LLMs talk to APIs, databases, and other data sources. This lets them do things like get real-time information or process datasets that are specific to a topic. Some important reasons are: 1.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content