This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Choosing the right dataanalysis tools is challenging, as no tool fits every need. This blog will help you determine which dataanalysis tool best fits your organization by exploring the top dataanalysis tools in the market with their key features, pros, and cons. Big data is much more than just a buzzword.
Read this blog to know how various data-specific roles, such as data engineer, data scientist, etc., differ from ETL developer and the additional skills you need to transition from ETL developer to data engineer job roles. Dataanalysis and visualization have traditionally been a common goal for businesses.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Reddit, being a vast community-driven platform, provides a rich data source for extracting valuable insights.
Build Azure Data Factory Pipeline - Data Collection and Processing The data from the various sources is collected using a combination of technologies such as machine-to-machine (M2M) communication, edge computing, and cloud-based services. The data is collected in real-time and processed using Azure Data Factory.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
On the other hand, a data engineer is responsible for designing, developing, and maintaining the systems and infrastructure necessary for dataanalysis. The difference between a data analyst and a data engineer lies in their focus areas and skill sets.
Data Analyst Interview Questions and Answers 1) What is the difference between Data Mining and DataAnalysis? Data Mining vs DataAnalysisData Mining DataAnalysisData mining usually does not require any hypothesis. Dataanalysis begins with a question or an assumption.
Data Science Roles - Top 4 Reasons to Choose Choosing data science as a career serves several benefits: Growth: According to the IBM report, there were about 2.7 million available positions in dataanalysis, data science, and related fields. They also help data science professionals to execute projects on time.
The reason for this growing importance is simple: the world is becoming increasingly data-driven. Learning basic AI concepts , particularly in the beginner-friendly domain of dataanalysis , will thus become a must-have skill among professionals of different industries. FAQs What is Artificial Intelligence for DataAnalysis?
Data Processing- The SQL Server Integration Services uses the on-premises ETL packages to run task-specific workloads. The above Data Factory pipeline uses the Integrated Runtime to perform an SSIS job hosted on-premises using a stored procedure. After completing the data purification task, a copy task loads the clean data into Azure.
They provide a centralized repository for data, known as a data warehouse, where information from disparate sources like databases, spreadsheets, and external systems can be integrated. This integration facilitates efficient retrieval and dataanalysis, enabling organizations to gain valuable insights and make informed decisions.
Getting Started with Azure Databricks Let’s walk through the steps to get started with Azure Databricks to understand how to use it for performing dataanalysis tasks and building ML models: Step 1: Setting up Azure Databricks Workspace To begin using Azure Databricks, you need to set up a workspace. How to Use Azure Databricks?
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. In addition to this, they make sure that the data is always readily accessible to consumers.
This proficiency allows users to extract data distributed across different tables, facilitating comprehensive dataanalysis and retrieval. Experience Hands-on Learning with the Best Azure Data Engineering Course and Get Certified! Consider we have two tables in a database: "Employees" and "Departments."
It entails using various technologies, including data mining, data transformation, and datacleansing, to examine and analyze that data. Both data science and software engineering rely largely on programming skills. However, data scientists are primarily concerned with working with massive datasets.
Data Mining- You cleanse your data sets through data mining or data cleaning. You delete incorrect data during the datacleansing process, and the data mining process entails removing identical and redundant data from your data collections.
They are responsible for processing, cleaning, and transforming raw data into a structured and usable format for further analysis or integration into databases or data systems. Their efforts make ensuring that data is accurate, dependable, and consistent, laying the groundwork for dataanalysis and decision-making.
Not very surprisingly, the amount of data used and shared between networks is infinite. This has led to dataanalysis being a vital element of most businesses. Data analysts are professionals who manage and analyze data that give insight into business goals and help align them. What is DataAnalysis?
4) Data Visualization The dataanalysis process includes more than just extracting useful insights from data. A good data analyst portfolio template will demonstrate to potential companies that you can use data to solve issues and discover new possibilities. 2) What aspect of data intrigues you the most?
Datacleansing. Before getting thoroughly analyzed, data ? In a nutshell, the datacleansing process involves scrubbing for any errors, duplications, inconsistencies, redundancies, wrong formats, etc. and as such confirming the usefulness and relevance of data for analytics. Dataanalysis.
Data Analyst Interview Questions and Answers 1) What is the difference between Data Mining and DataAnalysis? Data Mining vs DataAnalysisData Mining DataAnalysisData mining usually does not require any hypothesis. Dataanalysis begins with a question or an assumption.
Data Visualization: Assist in selecting appropriate visualizations for data presentation and formatting visuals for clarity and aesthetics. DataAnalysis: Perform basic dataanalysis and calculations using DAX functions under the guidance of senior team members.
Due to its strong dataanalysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
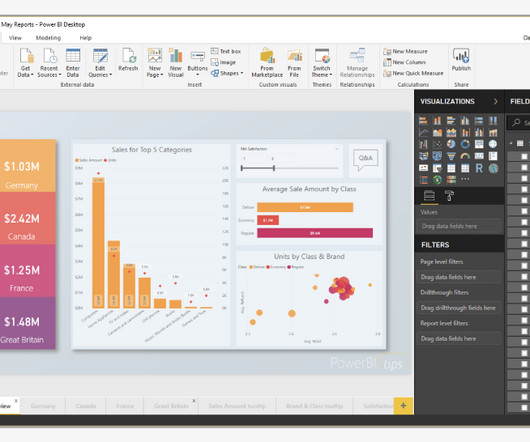
Power View Power view helps to create interactive charts, graphs, maps, and other visuals in Excel, SharePoint, SQL Server, and Power BI that bring data to life. Power Map Power map is a 3-D data visualization tool. Power Q&A Power Q&A is used to explore data in the fastest way to get an answer using natural language.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
This is again identified and fixed during datacleansing in data science before using it for our analysis or other purposes. Benefits of Data Cleaning in Data Scienece Your analysis will be reliable and free of bias if you have a clean and correct data collection.
Check out the best Data Science certification online if you want to develop a keen understanding of the subject. Collecting your data: Collecting data from sources you identify, such as databases, spreadsheets, APIs, or websites. Clean Data: Clean data to remove duplicates, inconsistencies, and errors.
In this letter, candidates showcase their expertise in designing interactive reports, dashboards, and data models. They may also mention their ability to connect to various data sources, perform datacleansing, and create calculated measures. Use metrics or quantifiable achievements to showcase your contributions.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
To manage these large amounts of data, testing necessitates using specific tools, frameworks, and processes. Big dataanalysis refers to the generation of data and its storage, retrieval of data, and analysis of large data in terms of volume and speed variation. What is the goal of A/B testing?
Understanding the importance of data cleaning and how it helps improve the quality of your products or services is important. . What Is Data Cleaning? . Data cleaning means the process of identifying and correcting data errors. Datacleansing removes duplicates from your existing data set. .
Data Preparation and Transformation Skills Preparing the raw data into the right structure and format is the primary and most important step in dataanalysis. By understanding how to cleanse, organize, and calculate data, you can ensure that your data is accurate and reliable.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. Utilizes structured data or datasets that may have already undergone extraction and preparation. Primary Focus Structuring and preparing data for further analysis.
To understand their requirements, it is critical to possess a few basic data analytics skills to summarize the data better. So, add a few beginner-level data analytics projects to your resume to highlight your Exploratory DataAnalysis skills. Blob Storage for intermediate storage of generated predictions.
These problems must be addressed during the datacleansing step. The aim during this cleaning phase is to maintain consistency by imputing missing numbers, eliminating or modifying outliers, and changing the data type. Start working on these projects in data science using Python and excel in your data science career.
The first step is capturing data, extracting it periodically, and adding it to the pipeline. The next step includes several activities: database management, data processing, datacleansing, database staging, and database architecture. Consequently, data processing is a fundamental part of any Data Science project.
4) Data Visualization The dataanalysis process includes more than just extracting useful insights from data. A good data analyst portfolio will demonstrate to potential companies that you can use data to solve issues and discover new possibilities. 2) What aspect of data intrigues you the most?
The transformation of data occurs within the data warehouse itself, after the loading phase. This means that both raw and transformed data coexist within the data warehouse, offering greater flexibility and providing a comprehensive historical context for dataanalysis.
The goal of a big data crowdsourcing model is to accomplish the given tasks quickly and effectively at a lower cost. Crowdsource workers can perform several tasks for big data operations like- datacleansing, data validation, data tagging, normalization and data entry.
Starting a career in data analytics requires a strong foundation in mathematics, statistics, and computer programming. To become a data analyst, one should possess skills in data mining, datacleansing, and data visualization.
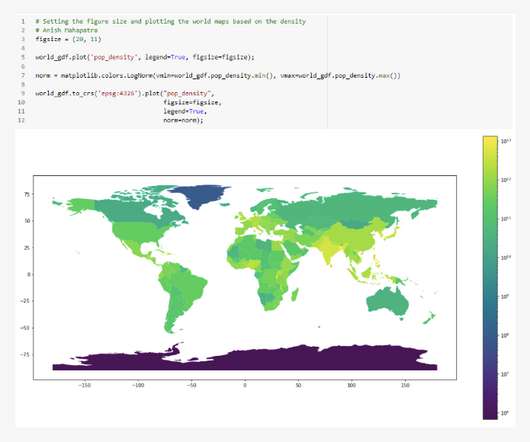
Here, in each of these applications, the spatial data becomes much more complex to use. With this article, we shall tap into the understanding of spatial data and geospatial dataanalysis with Python through some examples and how to perform operations from spatial statistics Python libraries. What is Geospatial Data?
Proper data pre-processing and data cleaning in dataanalysis constitute the starting point and foundation for effective decision-making, though it can be the most tiresome phase. This capability underpins sustainable, chattel datacleansing practices requisite to data governance.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content