This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog aims to give you an overview of the dataanalysis process with a real-world business use case. Table of Contents The Motivation Behind DataAnalysis Process What is DataAnalysis? What is the goal of the analysis phase of the dataanalysis process? What is DataAnalysis?
Choosing the right dataanalysis tools is challenging, as no tool fits every need. This blog will help you determine which dataanalysis tool best fits your organization by exploring the top dataanalysis tools in the market with their key features, pros, and cons. Big data is much more than just a buzzword.
However, the vast volume of data will overwhelm you if you start looking at historical trends. The time-consuming method of datacollection and transformation can be eliminated using ETL. You can analyze and optimize your investment strategy using high-quality structureddata.
1) Build an Uber Data Analytics Dashboard This data engineering project idea revolves around analyzing Uber ride data to visualize trends and generate actionable insights. Project Idea : Build a data engineering pipeline to ingest and transform data, focusing on runs, wickets, and strike rates. venues or weather).
While today’s world abounds with data, gathering valuable information presents a lot of organizational and technical challenges, which we are going to address in this article. We’ll particularly explore datacollection approaches and tools for analytics and machine learning projects. What is datacollection?
Data Science Pipeline Architecture Data Science Pipeline Architecture typically comprises three core steps: DataCollection, Storage, Processing, & Analytics, and Visualization. Categorizing these sources based on the type of data, they generate helps us understand the nature and relevance of the data they provide.
Table of Contents What is Real-Time Data Ingestion? Let us understand the key steps involved in real-time data ingestion into HDFS using Sqoop with the help of a real-world use case where a retail company collects real-time customer purchase data from point-of-sale systems and e-commerce platforms.
Million opportunities for remote and on-site data engineering roles. So, have you been wondering what happens to all the datacollected from different sources, logs on your machine, data generated from your mobile, data in databases, customer data, and so on? We call this system Data Engineering.
One of the most in-demand technical skills these days is analyzing large data sets, and Apache Spark and Python are two of the most widely used technologies to do this. Python is one of the most extensively used programming languages for DataAnalysis, Machine Learning , and data science tasks.
2) Cryptocurrency Analysis AI-powered agents are transforming cryptocurrency analysis by automating datacollection, trend detection, and market predictions. The Report Writer then synthesizes insights into a structured report. Source Code: How to Build an LLM-Powered DataAnalysis Agent?
Step 3: Developing Your Generative AI Solution Once you’ve gathered your training data and selected the appropriate frameworks, it’s time to start developing your generative AI model. This involves: Model Design- Choose the right architecture—GANs for images, VAEs for structureddata.
Role of LLMs for Web Scraping LLMs are adept at handling unstructured data and transforming it into meaningful insights. Using their natural language understanding capabilities, LLMs can: Summarize scraped content, such as distilling product reviews into sentiment analysis.
The data engineer skill of building data warehousing solutions expects a data engineer to curate data and perform dataanalysis on that data from multiple sources to support the decision-making process. In such instances, raw data is available in the form of JSON documents, key-value pairs, etc.,
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Get to know more about data science for business. Learning DataAnalysis in Excel Dataanalysis is a process of inspecting, cleaning, transforming and modelling data with an objective of uncover the useful knowledge, results and supporting decision. In dataanalysis, EDA performs an important role.
Become a Job-Ready Data Engineer with Complete Project-Based Data Engineering Course ! Big data is often characterized by the seven V's: Volume , Variety , Velocity, Variability, Veracity, Visualization, and Value of data. Database Management Systems Big Data Engineer works on unstructured and semi-structureddata.
They provide a centralized repository for data, known as a data warehouse, where information from disparate sources like databases, spreadsheets, and external systems can be integrated. This integration facilitates efficient retrieval and dataanalysis, enabling organizations to gain valuable insights and make informed decisions.
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the raw data that will be ingested, processed, and analyzed.
You might think that datacollection in astronomy consists of a lone astronomer pointing a telescope at a single object in a static sky. While that may be true in some cases (I collected the data for my Ph.D. thesis this way), the field of astronomy is rapidly changing into a data-intensive science with real-time needs.
Of course, handling such huge amounts of data and using them to extract data-driven insights for any business is not an easy task; and this is where Data Science comes into the picture. To make accurate conclusions based on the analysis of the data, you need to understand what that data represents in the first place.
Data Engineer Interview Questions on Big Data Any organization that relies on data must perform big data engineering to stand out from the crowd. But datacollection, storage, and large-scale data processing are only the first steps in the complex process of big dataanalysis.
Data Science initiatives from an operational standpoint help organizations optimize various aspects of their business, such as supply chain management , inventory segregation, and management, demand forecasting, etc. A data analyst would be a professional who will be able to accomplish all the tasks mentioned in the process of dataanalysis.
As organizations strive to gain valuable insights and make informed decisions, two contrasting approaches to dataanalysis have emerged, Big Data vs Small Data. These contrasting approaches to dataanalysis are shaping the way organizations extract insights, make predictions, and gain a competitive edge.
Big data can be summed up as a sizable datacollection comprising a variety of informational sets. It is a vast and intricate data set. Big data has been a concept for some time, but it has only just begun to change the corporate sector. The data can also show that the student succeeds well with online instruction.
LlamaIndex Best For - Integrating large language models (LLMs) with structureddata sources to create powerful, context-aware AI applications for advanced data querying and analysis. SingleStore introduces a powerful new Notebook feature, designed to streamline complex dataanalysis , machine learning, and exploration.
This article delves into the realm of unstructured data, highlighting its importance, and providing practical guidance on extracting valuable insights from this often-overlooked resource. We will discuss the different data types, storage and management options, and various techniques and tools for unstructured dataanalysis.
Learning Outcomes: You will understand the processes and technology necessary to operate large data warehouses. Engineering and problem-solving abilities based on Big Data solutions may also be taught. It separates the hidden links and patterns in the data. Data mining's usefulness varies per sector.
Critical Thinking Because they must match the client's expectations with their analysis of the data, business analysts need to be able to think critically. Business analysts must therefore put business requirements and dataanalysis in order of importance, considering several factors.
The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. The framework provides a way to divide a huge datacollection into smaller chunks and shove them across interconnected computers or nodes that make up a Hadoop cluster. Data access options.
It also entails data utilization, analysis techniques, user roles, and applications, allowing for a comprehensive comparison between business intelligence and data mining cycle. By examining these factors, organizations can make informed decisions on which approach best suits their dataanalysis and decision-making needs.
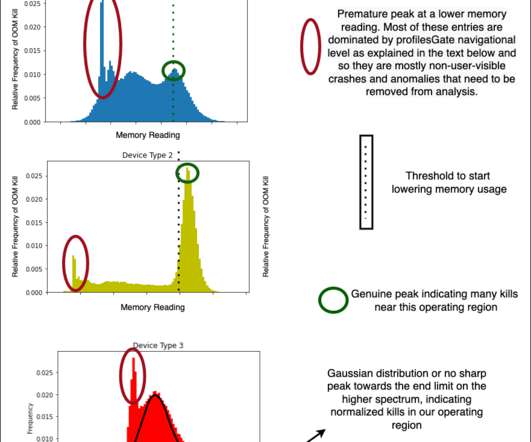
DataAnalysis and Observations Without diving very deep into the actual devices and results of the classification, we now show some examples of how we could use the structureddata for some preliminary analysis and make observations. Acknowledgements I would like to thank the members of various teams?
Their efforts make ensuring that data is accurate, dependable, and consistent, laying the groundwork for dataanalysis and decision-making. What does a Data Processing Analysts do ? A data processing analyst’s job description includes a variety of duties that are essential to efficient data management.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. Dataanalysis.
Benefits of Data wrangling Data Wrangling provides several benefits, including: It converts data into a required format suitable for the final system, which typically assists in making well-informed decisions. It significantly enhances data quality by removing unwanted rows and empty cells from the data frame.
Depending on what sort of leaky analogy you prefer, data can be the new oil , gold , or even electricity. Of course, even the biggest data sets are worthless, and might even be a liability, if they arent organized properly. Datacollected from every corner of modern society has transformed the way people live and do business.
However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured. This mainly happened because data that is collected in recent times is vast and the source of collection of such data is varied, for example, datacollected from text files, financial documents, multimedia data, sensors, etc.
However, the vast volume of data will overwhelm you if you start looking at historical trends. The time-consuming method of datacollection and transformation can be eliminated using ETL. You can analyze and optimize your investment strategy using high-quality structureddata.
Goal To extract and transform data from its raw form into a structured format for analysis. To uncover hidden knowledge and meaningful patterns in data for decision-making. Data Source Typically starts with unprocessed or poorly structureddata sources. Output Structureddata ready for analysis.
Data science and artificial intelligence might be the buzzwords of recent times, but they are of no value without the right data backing them. The process of datacollection has increased exponentially over the last few years. NoSQL databases are designed to store unstructured data like graphs, documents, etc.,
One of the most in-demand technical skills these days is analyzing large data sets, and Apache Spark and Python are two of the most widely used technologies to do this. Python is one of the most extensively used programming languages for DataAnalysis, Machine Learning , and data science tasks.
Data science and artificial intelligence might be the buzzwords of recent times, but they are of no value without the right data backing them. The process of datacollection has increased exponentially over the last few years. NoSQL databases are designed to store unstructured data like graphs, documents, etc.,
You can check out the Big Data Certification Online to have an in-depth idea about big data tools and technologies to prepare for a job in the domain. To get your business in the direction you want, you need to choose the right tools for big dataanalysis based on your business goals, needs, and variety.
Alignment of sequence data with a reference genome and variant-calling algorithms are key elements of primary and secondary genomic dataanalysis. The next step—tertiary analysis—involves analyzing large and dynamic collections of this preprocessed data, frequently packaged and distributed as compressed VCF files.
Google singles out four key phases through which a recommender system processes data. They are information collection, storing, analysis, and filtering. Datacollection. The initial phase involves gathering relevant data to create a user profile or model for prediction tasks. Dataanalysis.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content