This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
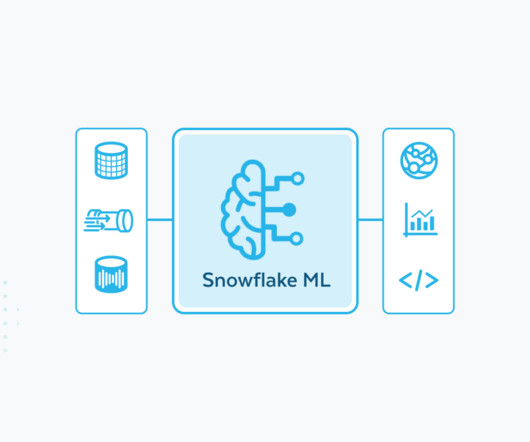
For training using default settings out of the box for Snowflake Notebooks on Container Runtime, our benchmarks show that distributed XGBoost on Snowflake is over 2x faster for tabular data compared to a managed Spark solution and a competing cloud service. CHG builds and productionizes its end-to-end ML models in Snowflake ML.
. “Unit imputation” means replacing a whole data point, while “item imputation” means replacing part of a data point. Missing information can cause bias, make dataanalysis harder, and lower efficiency. What Is Data Imputation? This process is important for keeping dataanalysis accurate.
This can be done by finding regularities in the data, such as correlations or trends, or by identifying specific features in the data. Pattern recognition is used in a wide variety of applications, including Image processing, Speech recognition, Biometrics, Medical diagnosis, and Fraud detection.
By learning the details of smaller datasets, they better balance task-specific performance and resource efficiency. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. What are Small language models?
Yet, its toolset for for audio analysis is not very sophisticated. For further steps, you need to load your dataset to Python or switch to a platform specifically focusing on analysis and/or machine learning. Labeling of audio data in Audacity. Source: Towards Data Science. Audio dataanalysis steps.
CHG Healthcare , a healthcare staffing company with over 45 years of industry expertise, uses AI/ML to power its workforce staffing solutions across 700,000 medical practitioners representing 130 medical specialties. CHG builds and productionizes its end-to-end ML models in Snowflake ML.
Data scientists are thought leaders who apply their expertise in statistics and machine learning to extract useful information from data. They can work with various tools to analyze large datasets, including social media posts, medical records, transactional data, and more.
Today, we will delve into the intricacies the problem of missing data , discover the different types of missing data we may find in the wild, and explore how we can identify and mark missing values in real-world datasets. Image by Author. Let’s consider an example. Image by Author. Image by Author. Image by Author.
Industry Applications of Predictive AI While both involve machine learning and dataanalysis, they differ in their core objectives and approaches. paintings, songs, code) Historical data relevant to the prediction task (e.g., Real-world Applications of Generative AI The Power of Predictive AI How Does Predictive AI Work?
By learning from historical data, machine learning algorithms autonomously detect deviations, enabling timely risk mitigation. Machine learning offers scalability and efficiency, processing large datasets quickly. It is a unique occurrence or trend that sticks out among most available data. Types of Anomalies 1.
Understanding what defines data in the modern world is the first step toward the Data Science self-learning path. There is a much broader spectrum of things out there which can be classified as data. For some, it does not matter what the data is about. For some of us are more inclined towards a particular domain of data.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
Roles: A Data Scientist is often referred to as the data architect, whereas a Full Stack Developer is responsible for building the entire stack. The main difference between these two roles is that a Data Scientist has tremendous expertise in dataanalysis and knows how to analyze data.
It improves accessibility, encourages innovation for greater value, lowers disparities in research and treatment, and harnesses large-scale medicaldataanalysis to create new data. It makes use of genetic data and intelligent computer programs to comprehend how our bodies function.
Memory Management RDD is used by Spark to store data in a distributed fashion (i.e., Spark's primary data structure is Resilient Distributed Datasets (RDD). Each dataset in an RDD is split into logical divisions that may be calculated on several cluster nodes. Looking to dive into the world of data science?
Data scientists are thought leaders who apply their expertise in statistics and machine learning to extract useful information from data. They can work with various tools to analyze large datasets, including social media posts, medical records, transactional data, and more.
This article emphasises on Data Analytics projects that would help you in securing jobs in the analytics Industry. What are Data Analytics Projects? Data analytics projects involve using statistical and computational techniques to analyse large datasets with the aim of uncovering patterns, trends, and insights.
At their core, ML models learn from data. They are trained on large datasets to recognise patterns and make predictions or decisions based on new information. During the model evaluation phase (validation mode), we will use a labelled dataset of emails to calculate metrics like accuracy, precision and recall.
Learning Outcomes: This data concentration will provide you a solid grounding in mathematics and statistics as well as extensive experience with computing and dataanalysis. Possible Careers: Data analyst Marketing analyst Data mining analyst Data engineer Quantitative analyst 3.
The publicly available Kaggle dataset of the Tesla Stock Data from 2010 to 2020 can be used to implement this project. Maybe you could even consider gathering more data from the source of the Tesla Stock dataset. You could undertake this exercise using the publicly available Cervical Cancer Risk Classification Dataset.
In addition, data scientists use machine learning algorithms that analyze large amounts of data at high speeds to make predictions about future events based on historical patterns observed from past events (this is known as predictive modeling in pharma data science).
View A broader view of data Narrower view of dataDataData is gleaned from diverse sources. View A broader view of data Narrower view of dataDataData is gleaned from diverse sources. to glean useful insights from data. Traditional data processing techniques cannot be used.
By learning the details of smaller datasets, they better balance task-specific performance and resource efficiency. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. What are Small language models?
Overnight, data science 's potential exploded. All thanks to scholars who combined statistics and computer science for dataanalysis, quick processing, inexpensive storage, big data, and other factors. To remove meaningful data from enormous amounts of data, processing of data is necessary.
The former uses data to generate insights and help businesses make better decisions, while the latter designs data frameworks, flows, standards, and policies that facilitate effective dataanalysis. But first, all candidates must be accredited by Arcitura as Big Data professionals.
Signal Processing Techniques : These involve changing or manipulating data such that we can see things in it that aren’t visible through direct observation. . Also, experience is required in software development, data processes, and cloud platforms. . is highly beneficial. Industries That Work With AI.
That’s quite a help when dealing with diverse data sets such as medical records, in which any inconsistencies or ambiguities may have harmful effects. As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Data ingestion.
Practical Applications The ability to split delimited string columns into rows opens up numerous possibilities for dataanalysis and manipulation. Here are some practical applications: Skill Analysis : In the example above, splitting employee skills allows for more granular analysis.
What distinguishes Generative AI is its capacity to learn from current data and then generate entirely new and realistic outputs that reflect the essence of what it has learned. Thus, AI is able to analyze medical images like X-rays, MRIs, and CT scans to detect anomalies. Here are some of the best generative ai use cases to study: 1.
Big Data vs Traditional Data The difference between Big Data vs Traditional Data heavily relies on the tools, plans, processes, and objectives used within, which derive useful insights from the datasets. Let us now take a detailed look into how Big Data differs from Traditional relational databases.
By implementing various machine learning algorithms over a dataset of dates, store, item information, promotions, and unit sales, you will be using time forecasting methods to predict the sales. Two Sigma Investments is a firm implementing data science tools over datasets for predicting financial trade since 2001.
In artificial intelligence , an AI model, including Open AI models, refers to a mathematical formulation that processes data, discovers patterns, makes predicaments, and decisions in AI systems. They are very good at activities such as object recognition, facial recognition, and even detecting anomalies in medical photos.
Google BigQuery Clean Rooms Google BigQuery Clean Rooms differentiates itself with its serverless approach to dataanalysis, emphasizing scalability without the overhead of infrastructure management. This makes Databricks especially attractive for organizations eyeing an end-to-end analytics solution from ETL to AI modeling.
They are responsible for processing, cleaning, and transforming raw data into a structured and usable format for further analysis or integration into databases or data systems. Their efforts make ensuring that data is accurate, dependable, and consistent, laying the groundwork for dataanalysis and decision-making.
Predictive Modeling and Virtual Screening Machine learning models trained on vast datasets can predict the biological activity and safety profiles of new compounds. Data Quality and Availability For accurate predictions to be made with reliable results, training data used for AI models needs to be of good quality.
Different types, types, and stages of dataanalysis have emerged due to the big data revolution. Data analytics is booming in boardrooms worldwide, promising enterprise-wide strategies for business success. Prescriptive analytics is a combination of data and various business rules.
Supports data migration to a data warehouse from existing systems, etc. 15 ETL Projects Ideas For Big Data Professionals Below is a list of 15 ETL projects ideas curated for big data experts, divided into various levels- beginners, intermediate and advanced. Load the dataset into HDFS storage after downloading it.
To further comprehend the dataset, do the exploratory dataanalysis. The proper model for your data must be chosen within the fifth step. Use the training dataset to coach the model when it’s been chosen. Use the testing dataset to assess the model’s performance after training.
Amazon AI Services provides potent dataanalysis, forecasting, and anomaly detection capabilities. Scalability: Built to train models on large datasets and distributed systems with scalability in mind. Its ability to create chatbots and virtual agents positions it as one of the leading AI chatbot platforms.
Business Intelligence in Healthcare: It has become common to use patients’ data to better diagnose diseases. Along with that, deep learning algorithms and image processing methods are also used over medical reports to support a patient’s treatment better. influence the land prices. to estimate the costs.
C++ and Java); capacity to work with large, complex datasets; deep knowledge of machine learning evaluation measures; excellent analytical and problem-solving skills; meticulous attention to detail; good writing and verbal communication skills, since machine learning engineers often need to communicate the project details to the client, etc.;
Data Science is the study of extracting insights from massive amounts of data using various scientific approaches, processes and algorithms. The development of big data, dataanalysis, and quantitative statistics has given rise to the term "data science." Data science is now more important than ever.
They enable organizations to use data as an asset, resulting in greater operational efficiency, improved decision-making, and an edge over competitors in today's data-driven corporate world. Database applications also help in data-driven decision-making by providing dataanalysis and reporting tools.
DBMS plays a very crucial role in today’s modern information systems, serving as a base for a plethora of applications ranging from some simple record-keeping applications to complex dataanalysis programs. The overhead is more noticeable in cases of complex queries, large datasets, or high concurrency.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content