This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While data warehouses are still in use, they are limited in use-cases as they only support structureddata. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? .
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
And that’s the most important thing: Big Dataanalytics helps companies deal with business problems that couldn’t be solved with the help of traditional approaches and tools. This post will draw a full picture of what Big Dataanalytics is and how it works. Big Data and its main characteristics.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
This is where AWS DataAnalytics comes into action, providing businesses with a robust, cloud-based data platform to manage, integrate, and analyze their data. In this blog, we’ll explore the world of Cloud DataAnalytics and a real-life application of AWS DataAnalytics.
New data formats emerged — JSON, Avro, Parquet, XML etc. Datalakes were introduced to store the new data formats. Image by the author 2010 to 2020 - The Cloud Data Warehouse Enterprises now wanted quick dataanalytics without yesterday’s constraints of flexibility, processing power and scale.
What is a datalake, and how does it differ from a data warehouse? Datalakes contain raw, unstructured data of an organization, which can be stored indefinitely – either immediately or in the future. What are the components of AWS Kinesis?
link] LinkedIn: LakeChime - A Data Trigger Service for Modern DataLakes LinkedIn points out two critical flaws in a partitioned approach to data management. The granularity of partition creation constrained data consumption. However, the Map and Array comes with its cost.
This fast, serverless, highly scalable, and cost-effective multi-cloud data warehouse has built-in machine learning, business intelligence, and geospatial analysis capabilities for querying massive amounts of structured and semi-structureddata. This is true for the three data warehouses mentioned above.
Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance. Data mart vs data warehouse vs datalake vs OLAP cube. Datalakes, data warehouses, and data marts are all data repositories of different sizes.
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of dataanalytics and processing. These platforms provide strong capabilities for data processing, storage, and analytics, enabling companies to fully use their data assets.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a datalake used to host large amounts of raw data.
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
In broader terms, two types of data -- structured and unstructured data -- flow through a data pipeline. The structureddata comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
However, there is a fundamental challenge standing in the way of being successful: data. By breaking down data silos and integrating log data from multiple sources, Cloudera empowers defenders with the real-time analytics to respond to threats swiftly.
Data collection is a methodical practice aimed at acquiring meaningful information to build a consistent and complete dataset for a specific business purpose — such as decision-making, answering research questions, or strategic planning. Key differences between structured, semi-structured, and unstructured data.
Azure Synapse is Microsoft’s cloud-based analytics powerhouse. It’s a Swiss Army knife for data pros, merging data integration, warehousing, and big dataanalytics into one sleek package. No need to move the data around first. What is Azure Synapse?
Built around a cloud data warehouse, datalake, or data lakehouse. Modern data stack tools are designed to integrate seamlessly with cloud data warehouses such as Redshift, Bigquery, and Snowflake, as well as datalakes or even the child of the first two — a data lakehouse.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
You can leverage AWS Glue to discover, transform, and prepare your data for analytics. In addition to databases running on AWS, Glue can automatically find structured and semi-structureddata kept in your datalake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations.
Dynamic data masking serves several important functions in data security. One can use polybase: From Azure SQL Database or Azure Synapse Analytics, query data kept in Hadoop, Azure Blob Storage, or Azure DataLake Store. It does away with the requirement to import data from an outside source.
A Data Engineer is someone proficient in a variety of programming languages and frameworks, such as Python, SQL, Scala, Hadoop, Spark, etc. One of the primary focuses of a Data Engineer's work is on the Hadoop datalakes. NoSQL databases are often implemented as a component of data pipelines.
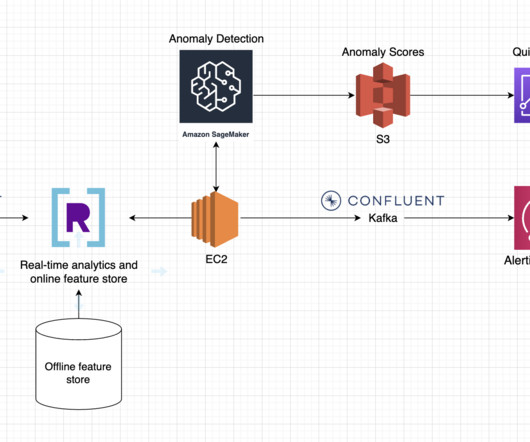
Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. This data tends to be slow changing and is stored in an offline feature store. This could be a cloud data warehouse, a datalake, or a database. The database has two primary jobs.
Collect data in real time Every organization can leverage valuable real-time data. Real-time analytics is made possible by the way the data is processed. Batch Processing In dataanalytics, batch processing involves first storing large amounts of data for a period and then analyzing it as needed.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Let the data drive the data pipeline architecture.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. What is Data Quality? Data quality as a concept is not novel – “ data quality ” has been around as long as humans have been collecting data!
Key features: Robust data visualization capabilities Seamless integration with Microsoft tools Easy-to-use interface 2. Looker Looker is a business intelligence (BI) and dataanalytics platform that provides a unified view of data from different sources.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. Q) What ETL does Amazon use? A) Amazon uses AWS Glue as its ETL tool.
Today’s data landscape is characterized by exponentially increasing volumes of data, comprising a variety of structured, unstructured, and semi-structureddata types originating from an expanding number of disparate data sources located on-premises, in the cloud, and at the edge.
Data Ingestion The process by which data is moved from one or more sources into a storage destination where it can be put into a data pipeline and transformed for later analysis or modeling. Data Integration Combining data from various, disparate sources into one unified view.
Also, you will find some interesting data engineer interview questions that have been asked in different companies (like Facebook, Amazon, Walmart, etc.) that leverage big dataanalytics and tools. Preparing for data engineer interviews makes even the bravest of us anxious. Structureddata usually consists of only text.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. The three most popular solutions for data storage and compute include the data warehouse, datalake, and data lakehouse.
Python for Data Analysis By Wes McKinney Online Along with Machine Learning, you also need to learn about Python, a widely used programming language in the field of DataAnalytics. Bruce, and Peter Gedeck) Naked Statistics: Stripping the Dread from the Data (Author: Charles Wheelan) 3.
As a result, having a central repository to safely store all data and further examine it to make informed decisions becomes necessary for enterprises. This is the reason why we need Data Warehouses. What is Snowflake Data Warehouse? To increase reliability over DataLake 1.0, What Does Snowflake Do?
This radical design choice made NoSQL databases — document databases, key-value stores, column-oriented databases and graph databases — great at storing huge amounts of data of varying kinds together, whether it is structured, semi-structured or polymorphic. Take the Hive analytics database that is part of the Hadoop stack.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content