This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructureddata, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataLake? .
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
And that’s the most important thing: Big Dataanalytics helps companies deal with business problems that couldn’t be solved with the help of traditional approaches and tools. This post will draw a full picture of what Big Dataanalytics is and how it works. Big Data and its main characteristics.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Another leading European company, Claranet, has adopted Glue to migrate their data load from their existing on-premise solution to the cloud. The popular data integration tool, AWS Glue, enables dataanalytics users to quickly acquire, analyze, migrate, and integrate data from multiple sources.
This method is advantageous when dealing with structured data that requires pre-processing before storage. Conversely, in an ELT-based architecture, data is initially loaded into storage systems such as datalakes in its raw form. Would the data be stored on cloud or on-premises?’
They offer a high memory-to-CPU ratio, with configurations providing up to 1 Terabyte of memory, making them ideal for in-memory databases, big dataanalytics, and real-time processing. Ideal for real-time analytics, high-performance caching, or machine learning, but data does not persist after instance termination.
Slowly Changing Dimensions (SCDs) are data warehouse dimensions that store and manage both current and historical data over time. What is a datalake, and how does it differ from a data warehouse? Streaming Data Warehouses offer real-time computing and allow users to use offline data warehouse functions online.
Cybersecurity will finally join the modern data stack Omer Singer , Head of Cybersecurity Strategy at Snowflake, predicts that 2023 will see more security teams leveraging modern cloud datalakes , which provide a consolidated view of all security data, alongside business and IT data, to improve an organization’s security posture.
The migration enhanced data quality, lineage visibility, performance improvements, cost reductions, and better reliability and scalability, setting a robust foundation for future expansions and onboarding.
So, it’s not real-time data. Amazon Redshift Amazon Redshift cloud data warehouse is a fully-managed SQL analytics service. It analyzes structured and unstructureddata from other warehouses, operational databases, and datalakes. This is true for the three data warehouses mentioned above.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in dataanalytics, integration, and processing. This feature allows for a more flexible exploration of data.
Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance. Data mart vs data warehouse vs datalake vs OLAP cube. Datalakes, data warehouses, and data marts are all data repositories of different sizes.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
Splunk Splunk is an American software company broadening its horizon in monitoring, investigating, and analyzing data. Splunk is the leading software to convert any data into real-world action. You can search structured as well as unstructureddata with Splunk. A data lakehouse combines a data warehouse and a datalake.
However, while you might be familiar with what is big data and hadoop, there is high probability that other people around you are not really sure on –What is big data, what hadoop is, what big dataanalytics is or why it is important. Table of Contents What is Big Data and what is the Big Deal?
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – datalakes , data warehouses , data hubs ;, data streaming and Big Dataanalytics solutions ( Hadoop , Spark , Kafka , etc.);
Organisations are constantly looking for robust and effective platforms to manage and derive value from their data in the constantly changing landscape of dataanalytics and processing. These platforms provide strong capabilities for data processing, storage, and analytics, enabling companies to fully use their data assets.
In 2021, Vimeo moved from a process involving big complicated ETL pipelines and data warehouse transformations to one focused on data consumer defined schemas and managed self-service analytics. And, of course, experience in dataanalytics, pipelines, or other forms of data management is vital.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
Data collection is a methodical practice aimed at acquiring meaningful information to build a consistent and complete dataset for a specific business purpose — such as decision-making, answering research questions, or strategic planning. Key differences between structured, semi-structured, and unstructureddata.
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
However, there is a fundamental challenge standing in the way of being successful: data. Unstructureddata not ready for analysis: Even when defenders finally collect log data, it’s rarely in a format that’s ready for analysis.
Here are some data engineering project ideas to consider and Data Engineering portfolio project examples to demonstrate practical experience with data engineering problems. Realtime DataAnalytics Project Overview: Olber, a corporation that provides taxi services, is gathering information about each and every journey.
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
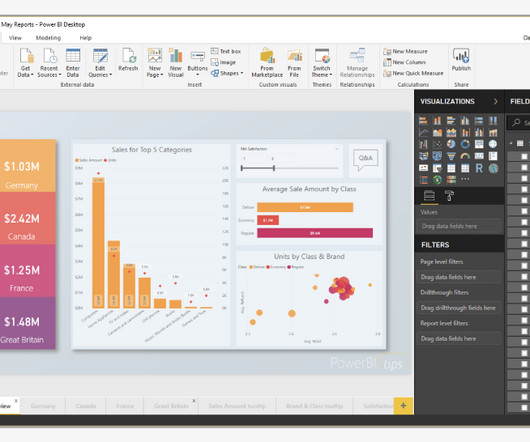
Power BI is a phenomenal tool for organizations looking to launch, prioritize and grow their business through data-driven intelligence efforts. Microsoft AI’s latest features allow even non-data scientists to prepare data, build machine learning models, find insights from structured and unstructureddata.
Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. Historically these highly specialized platforms were deployed on-prem in private data centers to ensure greater control , security, and compliance. Streaming dataanalytics. .
The applications of cloud computing in businesses of all sizes, types, and industries for a wide range of applications, including data backup, email, disaster recovery, virtual desktops big dataanalytics, software development and testing, and customer-facing web apps. What Is Cloud Computing?
But this data is all over the place: It lives in the cloud, on social media platforms, in operational systems, and on websites, to name a few. Not to mention that additional sources are constantly being added through new initiatives like big dataanalytics , cloud-first, and legacy app modernization.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Zero ETL is a bit of a misnomer.
(Source: [link] ) Hadoop is powering the next generation of Big DataAnalytics. NetworkAsia.net Hadoop is emerging as the framework of choice while dealing with big data. Four years ago Centrica was struggling hard on how to deal with the exponential increase in big data. March 11, 2016. March 31, 2016. Computing.co.uk
This eliminates the need to make multiple copies of data assets. Unified data platform: One Lake provides a unified platform for all data types, including structured, semi-structured, and unstructureddata. What’s new ever since Fabric’s GA announcement in November 2023?
News on Hadoop - March 2018 Kyvos Insights to Host Session "BI on Big Data - With Instant Response Times" at the Gartner Data and Analytics Summit 2018.PRNewswire.com, Source : [link] ) The datalake continues to grow deeper and wider in the cloud era.Information-age.com, March 5 , 2018.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. What is Data Quality? Data quality as a concept is not novel – “ data quality ” has been around as long as humans have been collecting data!
Data Warehouses: This service is used for storing relational, structured tables. Azure DataLake : Azure datalake can store both structured and unstructureddata. It is mainly used for dataanalytics and exploration. It is generally used for business reporting.
Whether your goal is dataanalytics or machine learning , success relies on what data pipelines you build and how you do it. But even for experienced data engineers, designing a new data pipeline is a unique journey each time. Data engineering in 14 minutes. ELT allows them to work with the data directly.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content