This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
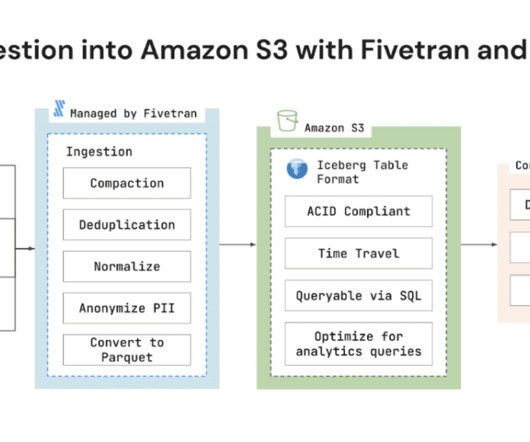
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format.
A new breed of ‘Fast Data’ architectures has evolved to be stream-oriented, where data is processed as it arrives, providing businesses with a competitive advantage. Dean Wampler (Renowned author of many big data technology-related books) Dean Wampler makes an important point in one of his webinars.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
Develop a long-term vision for Power BI implementation and data analytics. DataArchitecture and Design: Lead the design and development of complex dataarchitectures, including data warehouses, data lakes, and data marts. Define dataarchitecture standards and best practices.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
Accelerated Digital & Data Transformation : According to industry reports, a substantial number of teams report being over capacity, with many spending over 50% of their time just maintaining existing systems and with little time to truly modernize their data ecosystem.
Future Developments: Evolution towards serverless architectures, automated scaling, and tighter integration with advanced cloud-based analytics. Data Mesh Implementation: Overview: Data Mesh, a decentralized approach, is gaining traction for scalable and domain-oriented dataarchitecture.
The significance of data engineering in AI becomes evident through several key examples: Enabling Advanced AI Models with Clean Data The first step in enabling AI is the provision of high-quality, structured data. ChatGPT screenshot of AI-generated Python code and an explanation of what it means.
The emergence of cloud data warehouses, offering scalable and cost-effective data storage and processing capabilities, initiated a pivotal shift in data management methodologies. Read More: Zero ETL: What’s Behind the Hype?
The rise of microservices and data marketplaces further complicates the data management landscape, as these technologies enable the creation of distributed and decentralized dataarchitectures. Moreover, they require a more comprehensive data governance framework to ensure data quality, security, and compliance.
Source: McKinsy&Company For example, a data science team may spend 70 to 80 percent of their time preparing data for machine learning projects , with a prevailing part of this time being spent on datacleansing alone. Learn how data is prepared for machine learning in our dedicated video.
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
Also, data lakes support ELT (Extract, Load, Transform) processes, in which transformation can happen after the data is loaded in a centralized store. A data lakehouse may be an option if you want the best of both worlds. After residing in the raw zone, data undergoes various transformations.
The goal of these modifications is to better leverage the capabilities and benefits of the new environment while optimizing the new data warehouse for improved performance, scalability, and cost-effectiveness. As your business scales and new capabilities become available, your modernized data platform will be able to take advantage of them.
This process involves learning to understand the data and determining what needs to be done before the data becomes useful in a specific context. Discovery is a big task that may be performed with the help of data visualization tools that help consumers browse their data.
Data Integration at Scale Most dataarchitectures rely on a single source of truth. Having multiple data integration routes helps optimize the operational as well as analytical use of data. Data Volumes and Veracity Data volume and quality decide how fast the AI System is ready to scale.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content