This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. It encompasses the systems, tools, and processes that enable businesses to manage their data more efficiently and effectively. As a result, they can be slow, inefficient, and prone to errors.
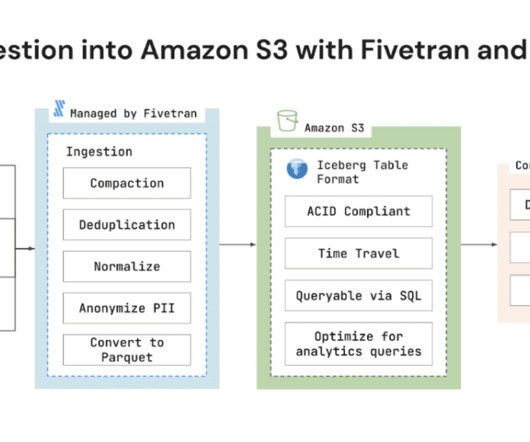
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve data validation, datacleansing, and data enrichment activities.
Future Developments: Evolution towards serverless architectures, automated scaling, and tighter integration with advanced cloud-based analytics. Data Mesh Implementation: Overview: Data Mesh, a decentralized approach, is gaining traction for scalable and domain-oriented dataarchitecture.
The emergence of cloud data warehouses, offering scalable and cost-effective datastorage and processing capabilities, initiated a pivotal shift in data management methodologies. Read More: Zero ETL: What’s Behind the Hype?
Technical Data Engineer Skills 1.Python Python Python is one of the most looked upon and popular programming languages, using which data engineers can create integrations, data pipelines, integrations, automation, and datacleansing and analysis.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a data lake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data.
Essentially, the fundamental principle underlying this process is to recognize data as a valuable resource, given its significant role in driving business success. Data management is a technical implementation of data governance and involves the practical aspects of working with data, such as datastorage, retrieval, and analysis.
There are three steps involved in the deployment of a big data model: Data Ingestion: This is the first step in deploying a big data model - Data ingestion, i.e., extracting data from multiple data sources. Data Variety Hadoop stores structured, semi-structured and unstructured data.
Zero Copy Cloning: Create multiple ‘copies’ of tables, schemas, or databases without actually copying the data. This noticeably saves time on copying and drastically reduces datastorage costs. The Solution phData recognized the imperative to enhance both the technical and people aspects of the data platform.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content