This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it’s unifying transactional and analytical data with Hybrid Tables, improving governance for an open lakehouse with Snowflake Open Catalog or enhancing threat detection and monitoring with Snowflake Horizon Catalog , Snowflake is reducing the number of moving parts to give customers a fully managed service that just works.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to dataarchitecture and structured datamanagement that really hit its stride in the early 1990s.
Over the years, the technology landscape for datamanagement has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs. The schema of semi-structured data tends to evolve over time.
Summary The current trend in datamanagement is to centralize the responsibilities of storing and curating the organization’s information to a data engineering team. This organizational pattern is reinforced by the architectural pattern of datalakes as a solution for managing storage and access.
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
Summary Building and maintaining a datalake is a choose your own adventure of tools, services, and evolving best practices. The flexibility and freedom that datalakes provide allows for generating significant value, but it can also lead to anti-patterns and inconsistent quality in your analytics.
But, even with the backdrop of an AI-dominated future, many organizations still find themselves struggling with everything from managingdata volumes and complexity to security concerns to rapidly proliferating data silos and governance challenges.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. Can you give an overview of the options that are available for someone wanting to use its SQL engine for querying their data? Hudi, Delta Lake, Iceberg, Nessie, LakeFS, etc.).
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's dataarchitecture?
Data has continued to grow both in scale and in importance through this period, and today telecommunications companies are increasingly seeing dataarchitecture as an independent organizational challenge, not merely an item on an IT checklist. Previously, there were three types of data structures in telco: .
In this episode he explains how it is designed to allow for querying and combining data where it resides, the use cases that such an architecture unlocks, and the innovative ways that it is being employed at companies across the world. Can you start by giving an overview of what Presto is and its origin story?
Agencies are plagued by a wide range of data formats and storage environments—legacy systems, databases, on-premises applications, citizen access portals, innumerable sensors and devices, and more—that all contribute to a siloed ecosystem and the datamanagement challenge. . Modern dataarchitectures. Forrester ).
In this episode Satish Jayanthi explores the benefits of incorporating column-aware tooling in the data modeling process. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement RudderStack helps you build a customer data platform on your warehouse or datalake.
In August, we wrote about how in a future where distributed dataarchitectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Track data files within the table along with their column statistics. Open table formats enable efficient datamanagement and retrieval by storing these files chronologically, with a history of DDL and DML actions and an index of data file locations. It can also be integrated into major data platforms like Snowflake.
CDC tools fuel analytical apps and mission-critical data feeds in banking and regulated industries, with use cases ranging from data synchronization, managing risk, and preventing fraud to driving personalization. Unlike datalakes, which are predominantly append-only, lakehouses support data mutation natively.
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. How do you define data curation? How does the size and maturity of a company affect the ways that they architect and interact with their data systems?
At Precisely’s Trust ’23 conference, Chief Operating Officer Eric Yau hosted an expert panel discussion on modern dataarchitectures. The group kicked off the session by exchanging ideas about what it means to have a modern dataarchitecture.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
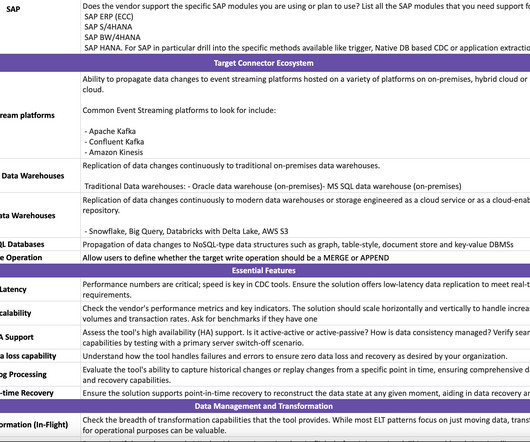
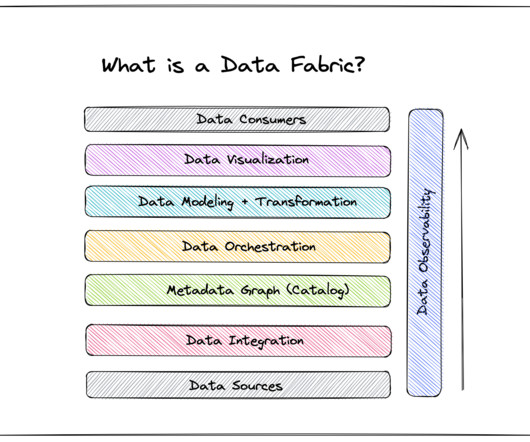
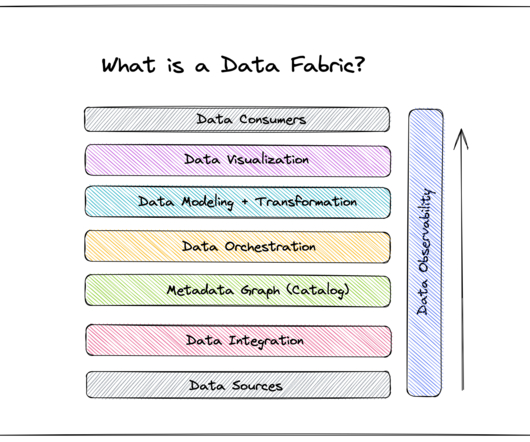
Enter data fabric: a datamanagementarchitecture designed to serve the needs of the business, not just those of data engineers. A data fabric is an architecture and associated data products that provide consistent capabilities across a variety of endpoints spanning multiple cloud environments.
Enter data fabric: a datamanagementarchitecture designed to serve the needs of the business, not just those of data engineers. A data fabric is an architecture and associated data products that provide consistent capabilities across a variety of endpoints spanning multiple cloud environments.
Data by itself has no value, it needs to be organized, standardized, and clean. In this context, datamanagement in an organization is a key point for the success of its projects involving data. One of the main aspects of correct datamanagement is the definition of a dataarchitecture.
Summary Datalakes have been gaining popularity alongside an increase in their sophistication and usability. Despite improvements in performance and dataarchitecture they still require significant knowledge and experience to deploy and manage. Can you describe what Cuelake is and the story behind it?
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
Key Takeaways Data Fabric is a modern dataarchitecture that facilitates seamless data access, sharing, and management across an organization. Datamanagement recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
Summary With the constant evolution of technology for datamanagement it can seem impossible to make an informed decision about whether to build a data warehouse, or a datalake, or just leave your data wherever it currently rests. How does it influence the relevancy of data warehouses or datalakes?
Monitor and Adapt: Continuously assess the impact of GenAI on data governance practices and be prepared to adapt policies as technologies evolve. Data governance is the only way to ensure those requirements are met. Chief Technology Officer, Finance Industry For all the quotes, download the Trendbook today!
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
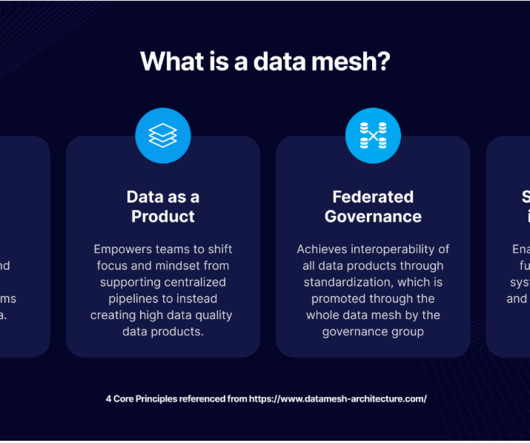
Data Mesh plays a vital role in managingdata effectively and is a valuable asset for organizations looking to improve agility, intelligence, and success in their operations in today’s constantly evolving environment. It also allows experts to access data directly, making work faster and more productive.
New Data Lakehouse Enables Stronger Data Governance SoftBank needed to reduce the number of workloads on its existing platform and decided to adopt Cloudera to build a datalake capable of managingdata more effectively. Team members with various Cloudera capabilities provided 24-hour support for upgrade.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented data warehouses and datalakes both rely on the durability and ease of use that it provides. Interview Introduction How did you get involved in the area of datamanagement?
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
For the same cost, organizations can now store 50 times as much data as in a Hadoop datalake than in a data warehouse. Datalake is gaining momentum across various organizations and everyone wants to know how to implement a datalake and why.
This was an eye opening conversation about how stateful computation of data streams from edge devices can reduce cost and complexity as compared to batch oriented workflows. We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, and Data Council.
It was interesting to learn about some of the custom data types and performance optimizations that are included. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e., need to integrate multiple “point solutions” used in a data ecosystem) and organization reasons (e.g., How CDF enables successful Data Mesh Architectures.
Combining and analyzing both structured and unstructured data is a whole new challenge to come to grips with, let alone doing so across different infrastructures. Both obstacles can be overcome using modern dataarchitectures, specifically data fabric and data lakehouse. Unified data fabric.
In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse. Simplify datamanagement . 1: Multi-function analytics . The *Any*-house.
To get a better understanding of a data architect’s role, let’s clear up what dataarchitecture is. Dataarchitecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Sample of a high-level dataarchitecture blueprint for Azure BI programs.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content