This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to datawarehouses and expansive datalakes, with each architecture responding to different business and data needs. Now you dont have to choose. This is why Snowflake is fully embracing this open table format.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on data storage solutions for your dataarchitecture.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to dataarchitecture and structured data management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Each of these architectures has its own unique strengths and tradeoffs. The schema of semi-structured data tends to evolve over time.
More than 50% of data leaders recently surveyed by BCG said the complexity of their dataarchitecture is a significant pain point in their enterprise. As a result,” says BCG, “many companies find themselves at a tipping point, at risk of drowning in a deluge of data, overburdened with complexity and costs.”
It’s not enough for businesses to implement and maintain a dataarchitecture. The unpredictability of market shifts and the evolving use of new technologies means businesses need more data they can trust than ever to stay agile and make the right decisions.
Summary Building and maintaining a datalake is a choose your own adventure of tools, services, and evolving best practices. The flexibility and freedom that datalakes provide allows for generating significant value, but it can also lead to anti-patterns and inconsistent quality in your analytics.
Summary The current trend in data management is to centralize the responsibilities of storing and curating the organization’s information to a data engineering team. This organizational pattern is reinforced by the architectural pattern of datalakes as a solution for managing storage and access.
Summary The market for datawarehouse platforms is large and varied, with options for every use case. We have partnered with organizations such as O’Reilly Media, Dataversity, and the Open Data Science Conference. Coming up this fall is the combined events of Graphorum and the DataArchitecture Summit.
Modern dataarchitectures. To eliminate or integrate these silos, the public sector needs to adopt robust data management solutions that support modern dataarchitectures (MDAs). Deploying modern dataarchitectures. Lack of sharing hinders the elimination of fraud, waste, and abuse. Forrester ).
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature.
CDC tools fuel analytical apps and mission-critical data feeds in banking and regulated industries, with use cases ranging from data synchronization, managing risk, and preventing fraud to driving personalization. Unlike datalakes, which are predominantly append-only, lakehouses support data mutation natively.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. How has the move to the cloud for data warehousing/data platforms influenced the practice of data modeling?
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. Can you walk through the stages of an ideal lifecycle for data within the context of an organizations uses for it?
Anyways, I wasn’t paying enough attention during university classes, and today I’ll walk you through data layers using — guess what — an example. Business Scenario & DataArchitecture Imagine this: next year, a new team on the grid, Red Thunder Racing, will call us (yes, me and you) to set up their new data infrastructure.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
When I heard the words ‘decentralised dataarchitecture’, I was left utterly confused at first! In my then limited experience as a Data Engineer, I had only come across centralised dataarchitectures and they seemed to be working very well. Result: Datawarehouse was born. So what was missing?
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. On datawarehouses and datalakes.
In this context, data management in an organization is a key point for the success of its projects involving data. One of the main aspects of correct data management is the definition of a dataarchitecture. The data became useless. The Lakehouse architecture was one of them.
Data pipelines are the backbone of your business’s dataarchitecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. Understanding the essential components of data pipelines is crucial for designing efficient and effective dataarchitectures.
Summary Datalakes have been gaining popularity alongside an increase in their sophistication and usability. Despite improvements in performance and dataarchitecture they still require significant knowledge and experience to deploy and manage. No more scripts, just SQL. How are you using Cuelake in your work at Cuebook?
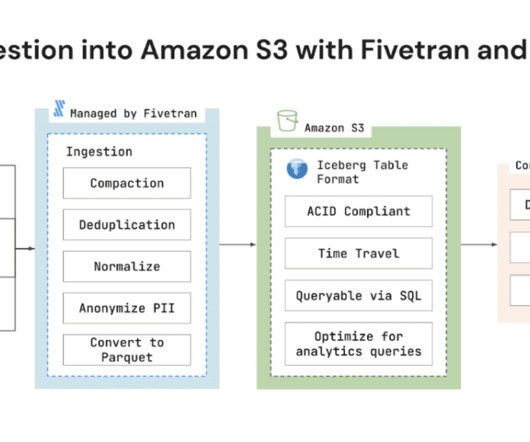
Today we want to introduce Fivetran’s support for Amazon S3 with Apache Iceberg, investigate some of the implications of this feature, and learn how it fits into the modern dataarchitecture as a whole. Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
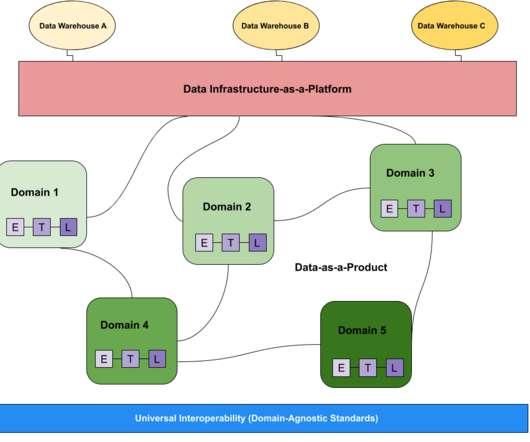
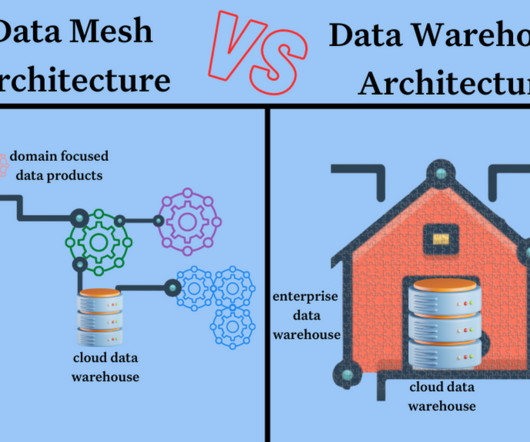
The data mesh design pattern breaks giant, monolithic enterprise dataarchitectures into subsystems or domains, each managed by a dedicated team. First-generation – expensive, proprietary enterprise datawarehouse and business intelligence platforms maintained by a specialized team drowning in technical debt.
Over the past decade, Cloudera has enabled multi-function analytics on datalakes through the introduction of the Hive table format and Hive ACID. Companies, on the other hand, have continued to demand highly scalable and flexible analytic engines and services on the datalake, without vendor lock-in.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
Summary With the constant evolution of technology for data management it can seem impossible to make an informed decision about whether to build a datawarehouse, or a datalake, or just leave your data wherever it currently rests. How does it influence the relevancy of datawarehouses or datalakes?
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
Data mesh vs datawarehouse is an interesting framing because it is not necessarily a binary choice depending on what exactly you mean by datawarehouse (more on that later). Despite their differences, however, both approaches require high-quality, reliable data in order to function. What is a Data Mesh?
Organizations have begun to built datawarehouses and lakes to analyze large amounts of data for insights and business reports. Often time they bring data from multiple data silos into their datalake and also have data stored in particular data stores like NoSQL databases to support different use cases.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake. What is a data fabric?
Trusted data is what makes the outputs of AI not just accurate, but impactful in decision making. Ensuring data is trustworthy comes with its own complications. Cloudera’s State of Enterprise AI and Modern DataArchitecture survey identified several challenges when it comes to data.
Summary Object storage is quickly becoming the unifying layer for data intensive applications and analytics. Modern, cloud oriented datawarehouses and datalakes both rely on the durability and ease of use that it provides.
However, to unlock the maximum power of corporate data, it is necessary to mix data from different systems and allow each data source to enhance the others. Various architectures, from datawarehouses to datalakes, have attempted to help solve this problem over the years.
Data organizations often have a mix of centralized and decentralized activity. DataOps concerns itself with the complex flow of data across teams, data centers and organizational boundaries. It expands beyond tools and dataarchitecture and views the data organization from the perspective of its processes and workflows.
Carrefour Spain , a branch of the larger company (with 1,250 stores), processes over 3 million transactions every day, giving rise to challenges like creating and managing a datalake and honing down key demographic information. . Working with Cloudera, Carrefour Spain was able to create a unified datalake for ease of data handling.
We have partnered with organizations such as O’Reilly Media, Dataversity, Corinium Global Intelligence, Alluxio, and Data Council. Upcoming events include the combined events of the DataArchitecture Summit and Graphorum, the Data Orchestration Summit, and Data Council in NYC.
Data platforms are no longer skunkworks projects or science experiments. As customers import their mainframe and legacy datawarehouse workloads, there is an expectation on the platform that it can meet, if not exceed, the resilience of the prior system and its associated dependencies. Conclusion.
Combining and analyzing both structured and unstructured data is a whole new challenge to come to grips with, let alone doing so across different infrastructures. Both obstacles can be overcome using modern dataarchitectures, specifically data fabric and data lakehouse. Unified data fabric.
In this episode, Oliver Cronk, Andrew Carr and David Hope talk about the ever-changing world of data, with conversations moving from datawarehouse to datalake, and data mesh to data fabric.
As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern dataarchitectures such as data lakehouses, data meshes, and data fabrics.
Phase 1 – Migrate: Move your legacy data system to Snowflake In the Migrate phase, you’ll move your data and workloads to Snowflake, and thereby resolve the cost concerns and performance bottlenecks associated with your legacy datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content